Data / IA
Les 10 annonces clés à retenir du Databricks Data + AI Summit 2026
Par Laurent Delattre, publié le 17 juin 2026
Deux semaines après Snowflake, Databricks occupe à son tour le Moscone Center de San Francisco pour son propre « Data + AI Summit 2026 ». Et comme son meilleur ennemi, l’éditeur déroule une rafale d’annonces qui convergent toutes vers la même conviction : un modèle d’IA ne vaut plus rien sans le contexte, la gouvernance et la donnée temps réel de l’entreprise. Demain, les agents ne devront pas seulement interroger la donnée, ils devront agir avec elle, en temps réel, dans un cadre gouverné, ouvert et directement connecté aux processus métiers.
Comme il y a 15 jours avec le Summit 2026 de Snowflake, il flotte cette semaine à San Francisco, une assurance que l’industrie de la donnée n’a plus affichée depuis longtemps. Sur la grande scène du Moscone Center, devant une assistance que l’éditeur chiffre à près de 30 000 personnes, Ali Ghodsi a ouvert son discours par une affirmation que peu de dirigeants osent encore formuler aussi nettement. « Nous pensons que l’AGI est déjà là », a lancé le cofondateur et patron de Databricks. « L’IA n’a pas de problème d’intelligence en ce moment : elle est largement assez intelligente. Le problème, c’est que l’AGI n’imprègne pas encore complètement nos organisations. La question est : comment l’activer au travail ? »
Cette phrase résume assez bien l’ambition du cru 2026 du « Data + AI Summit » de Databricks. L’éditeur ne cherche plus seulement à convaincre que son Lakehouse est une meilleure architecture de données. Il veut démontrer que cette architecture devient le socle d’exécution des agents d’entreprise. Autrement dit, l’endroit où l’IA trouve la donnée, comprend le contexte métier, agit sur les applications, respecte les droits d’accès, se souvient, coûte moins cher et reste auditable. Snowflake a tenu exactement le même discours.
Les plateformes de données ne sont plus seulement des entrepôts analytiques, elles deviennent des plans de contrôle pour l’IA. Il y a 15 jours, Snowflake dégainait Snowflake CoWork, CoCo, Cortex Training, Horizon Context ou Agent Identity pour que l’IA agentique soit contextualisée, sécurisée, gouvernée. Databricks répond avec Genie One, Genie Ontology, Agent Bricks, Unity AI Gateway, Lakehouse//RT, Lakebase Search et OpenSharing.
Pour Databricks comme pour Snowflake, les modèles sont devenus une commodité commune, et la guerre se joue désormais sur la couche sémantique, la gouvernance et l’orchestration. Dit autrement, pour les entreprises et leur DSI, l’avantage business se construit sur ses propres données, non sur l’abonnement à tel ou tel fournisseur de modèles. Pour Ali Ghodsi, « faire entrer le contexte de l’entreprise dans l’IA est plus difficile qu’on ne l’imagine. C’est le problème sur lequel nous nous sommes concentrés chez Databricks. »
Les modèles savent parler. Ils savent même raisonner de mieux en mieux. Mais ils restent souvent incapables de comprendre les définitions internes d’un KPI, les subtilités d’un référentiel client, les règles d’accès, les dépendances entre applications, les workflows métiers et les exceptions opérationnelles qui font la vraie vie d’une entreprise. C’est précisément sur ce terrain que Databricks a concentré ses dix annonces les plus structurantes.
1. Genie One et Genie Ontology : le collègue agentique qui sait « calculer »
À l’instar d’un Copilot Cowork officialisé cette semaine par Microsoft ou de Snowflake Cowork, Databricks ne présente plus son « Genie » comme un simple assistant conversationnel capable de répondre à des questions sur les données mais comme un « coworker » agentique, capable d’exploiter des données structurées, des documents, des applications, des tickets, des conversations, des réunions et plus largement le contexte métier de l’entreprise. Genie One se veut un véritable coéquipier numérique destiné aux métiers. Il agit, ne se contente plus de répondre : il interroge l’ensemble du patrimoine de données via la fédération et les connecteurs Lakeflow, dialogue dans les deux sens avec Gmail, Slack ou Microsoft Teams, prépare des notes de synthèse, déclenche des alertes et orchestre des actions, sur le poste comme sur de nouvelles applications iOS et Android. Les anciens Genie Spaces (l’éditeur en revendique plus d’un million) se muent en Genie Agents, des agents autonomes spécialisés que n’importe quel expert métier peut créer à partir d’une simple consigne, puis partager à ses équipes. Pour Ali Ghodsi, « Genie One calcule là où les autres agents récitent. ». Il peut calculer un indicateur, mobiliser la donnée fraîche, interpréter un contexte métier et prendre une décision justifiable.
Pour cela, l’agent métier doit comprendre une intention, trouver les bonnes données, interpréter leur sens, déclencher une action, documenter ce qu’il a fait et respecter les politiques internes.
C’est là qu’intervient l’autre brique essentielle, Genie Ontology, la couche censée reconstruire automatiquement la carte métier de l’entreprise : définitions, relations, règles, acteurs, processus, documents de référence, applications et signaux opérationnels. Plus pragmatiquement, c’est une couche de contexte vivante qui extrait en continu le savoir dispersé dans les tableaux de bord, les requêtes, les pipelines, les wikis et les tickets, pour le réorganiser en un graphe de la manière dont l’entreprise fonctionne réellement. Sa trouvaille consiste à hiérarchiser l’autorité des sources selon une logique inspirée du PageRank de Google : fraîcheur, fréquence d’usage, réputation de l’auteur, proximité avec des actifs certifiés.

Snowflake CoWork et Horizon Context poursuivent exactement la même ambition : donner aux agents un contexte sémantique fiable, gouverné, compréhensible par les métiers.
Microsoft, de son côté, décline Copilot Cowork et Work IQ.
La promesse de tous ces duos « IA Agentique + Couche Contextuelle » est séduisante, mais elle pose un défi classique aux DSI : un agent n’est aussi bon que le contexte qu’on lui donne. Sans gouvernance des référentiels, sans qualité des métadonnées et sans clarification des droits d’accès, le « collègue IA » risque vite de devenir un collègue très bavard, mais peu fiable.
Pour Databricks, le contexte ne doit pas être plaqué au-dessus des données, il doit naître de la plateforme de données elle-même.
2. Lakehouse//RT : Databricks veut supprimer la couche temps réel séparée
Et, justement, Databricks fait évoluer sa plateforme de données. Avec Lakehouse//RT, l’éditeur s’attaque à un vieux problème des architectures data : la séparation entre données analytiques et données temps réel. Le nouveau moteur, propulsé par Reyden, promet des latences de l’ordre de la milliseconde directement sur les tables Delta Lake et Apache Iceberg, pour des dizaines de milliers d’utilisateurs et d’agents simultanés, sans devoir maintenir la classique couche de service séparée. « Aucun autre système existant n’en est capable, tranche Reynold Xin, cofondateur et architecte en chef de Databricks. C’est probablement la plus importante introduction depuis le lancement du Lakehouse lui-même. »
Aujourd’hui, beaucoup d’entreprises conservent leurs données dans un lakehouse, mais doivent les recopier vers des bases spécialisées, des index, des caches ou des moteurs temps réel dès qu’il faut servir une application interactive, un tableau de bord ultra-rapide ou un agent qui doit réagir immédiatement. Cette duplication ajoute des coûts, de la complexité, des risques de désynchronisation et de nouvelles surfaces de gouvernance.
Databricks veut faire sauter cette couche intermédiaire. « Pendant des décennies, l’infrastructure complexe de données était une taxe que les équipes étaient obligées de payer », a expliqué Ali Ghodsi à propos de cette nouvelle convergence. Pour Databricks, si l’on veut des agents vraiment utiles, il faut qu’ils puissent interroger l’état réel de l’entreprise, pas une copie plus ou moins fraîche.
Databricks réconcilie traitement transactionnel et analytique sur une même copie de référence stockée dans le lac de données ce que l’éditeur baptise LTAP (Lake Transactional/Analytical Processing).
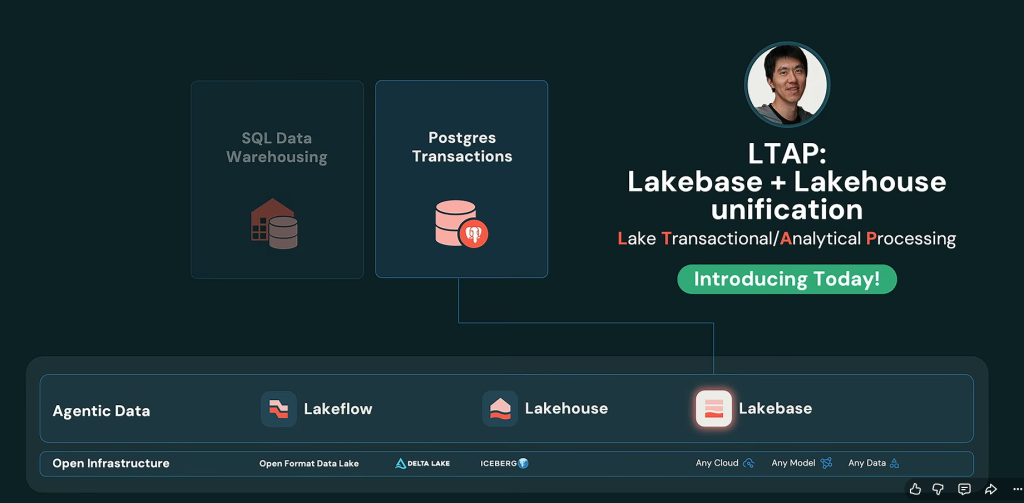
Snowflake a aussi insisté cette année sur la performance interactive, les usages temps réel et l’optimisation des workloads analytiques. Là où ce dernier a misé sur une « copie logique » gouvernée de la donnée et sur la généralisation d’Iceberg v3, Databricks répond par un moteur natif unifiant l’opérationnel et l’analytique. Avec cette idée de permettre aux entreprises de conserver leur socle ouvert Delta/Iceberg tout en servant des usages à très faible latence. La cible concurrentielle est large : ClickHouse, SingleStore, Apache Pinot, Druid, Rockset, Elasticsearch, Redis, Materialize, sans oublier les architectures maison qui empilent Kafka, Flink, caches et bases spécialisées.
Moins de duplication, moins d’ETL inversé, moins de plateformes à maintenir. La promesse est belle mais la prudence reste de mise. La frontière, héritée des années 1980, entre la base qui sert l’application et l’entrepôt qui éclaire la décision ne s’effacera pas d’un claquement de doigt. Au-delà des promesses marketing, il va falloir les vérifier sur des workloads réels, avec des volumes, des droits d’accès, des pics d’usage et des SLA de production. Le temps réel n’est pas seulement une question de moteur. C’est aussi une question d’architecture, d’exploitation et de coûts.
3. Agent Bricks devient une plateforme d’agents multi-modèles
Lancé l’an dernier comme atelier de construction d’agents, Agent Bricks accède au rang de plateforme à part entière. L’évolution la plus visible est l’ouverture multi-modèles : aux moteurs d’OpenAI, Anthropic, Gemini et Qwen s’ajoute désormais Kimi, et surtout un partenariat avec SpaceX pour rendre les modèles Grok nativement disponibles sur Databricks. Tous s’exécutent à l’intérieur du même périmètre de sécurité, ce qui permet de basculer d’un fournisseur à l’autre pour arbitrer entre comportement, latence et coût.
Au-delà du catalogue de modèles, l’éditeur y ajoute des pièces indispensables à l’ère agentique : l’intégration à Genie Ontology ; une mémoire d’agents managée, adossée à Lakebase, qui persiste le contexte et l’historique de session ; le support du protocole MCP ; un bac à sable d’exécution (sandbox) ; et des fonctions d’intelligence documentaire (analyse et extraction de PDF) désormais en disponibilité générale. Une façon de rappeler que les agents ne doivent pas être de simples wrappers autour d’un LLM, mais des entités capables de s’appuyer sur des données fiables, un historique, des documents et des actions contrôlées.
Et parce que Databricks n’oublie pas que « production », pour une DSI, signifie supervision, droits, coûts, journalisation, tests, sécurité, rollback, responsabilités et conformité, l’éditeur enrichit Agent Bricks de fonctions de gouvernance, traçabilité, politiques d’accès et intégration avec Unity Catalog.
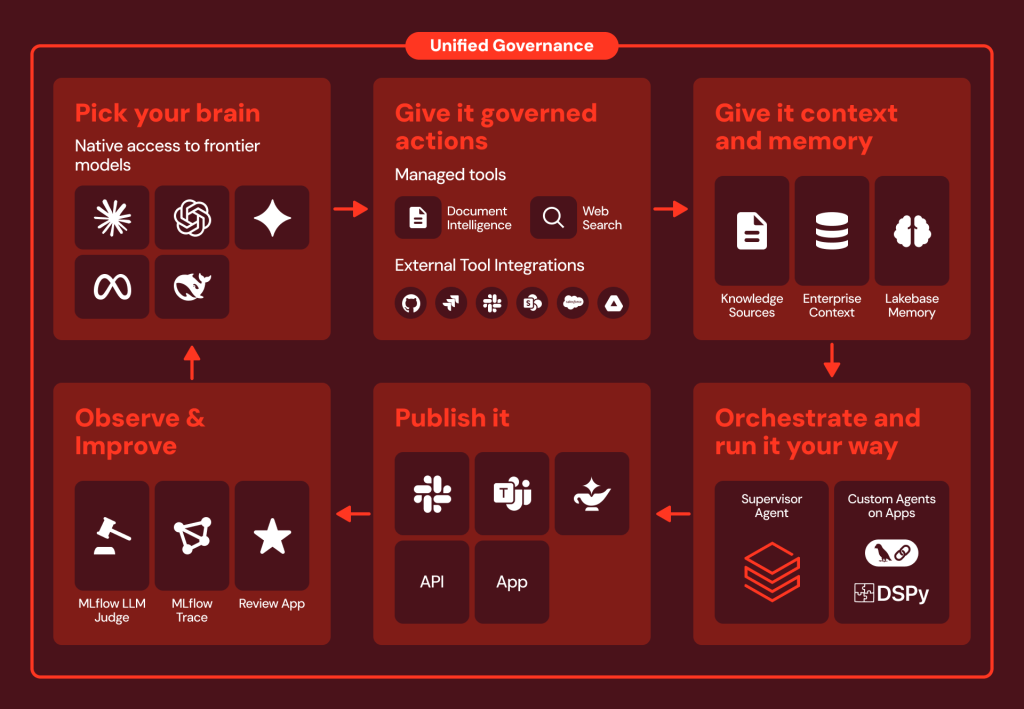
L’enjeu stratégique est de taille. En faisant de Databricks un point de convergence neutre entre tous les modèles du marché, l’éditeur se positionne face aux ateliers des hyperscalers (Amazon Bedrock, Microsoft AI Foundry, Google Gemini Enterprise Agent Platform) et aux frameworks ouverts comme LangGraph et CrewAI. La bataille va se jouer sur les coûts, la fiabilité et surtout sur la gouvernance.
4. Unity AI Gateway : la gouvernance IA passe au runtime
De gouvernance justement, il en est question avec l’annonce qui traduit le gain en maturité du marché : nity AI Gateway est une couche de gouvernance d’exécution qui s’applique aux modèles, aux agents, aux serveurs MCP, aux outils et… aux coûts de l’IA !
Budgets, plafonds de dépense, routage intelligent vers le modèle le plus pertinent, traçabilité complète et contrôles de sécurité : l’éditeur outille frontalement ce que Ali Ghodsi décrit comme la première préoccupation de ses clients. « Toutes les organisations sont terrifiées à l’idée de voir leurs coûts exploser, a-t-il confié. C’est la question numéro un qu’on nous pose. »
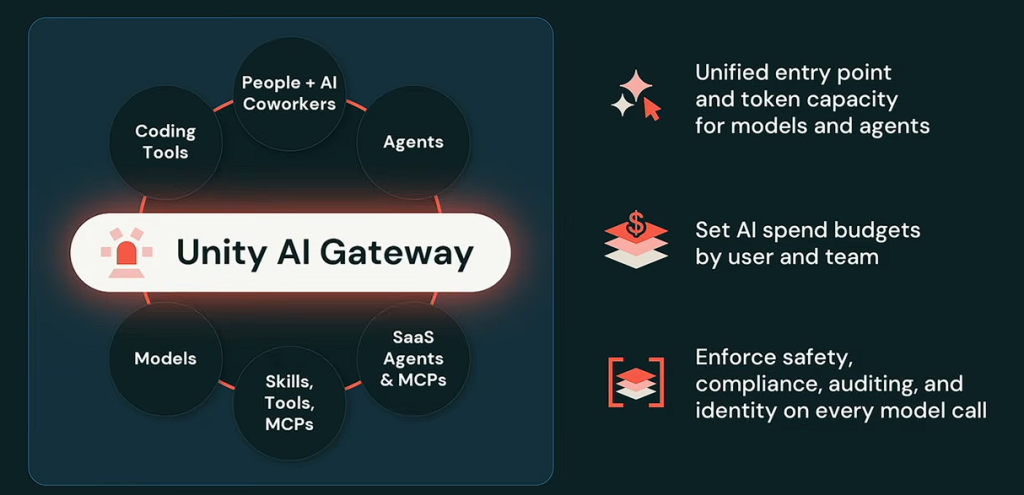
Unity AI Gateway répond à cette inquiétude en implémentant une brique de FinOps IA autant qu’une brique de sécurité. En centralisant la maîtrise des dépenses et la sécurité au même endroit que la gouvernance des données, Databricks répond à un manque criant que comblaient jusqu’ici des passerelles tierces (de type Portkey, Kong AI Gateway ou LiteLLM).
5. Acquisition de Panther : le « Security Lakehouse » part à l’assaut des SIEM
Databricks confirme ses ambitions en cybersécurité en annonçant le rachat de Panther Labs, éditeur d’une plateforme de centre opérationnel de sécurité (SOC) dopée à l’IA, dont la liste de clients comprend, fait notable, Anthropic. L’opération vient renforcer Lakewatch, le SIEM agentique dévoilé en mars, et matérialiser l’idée d’un « Security Lakehouse » : centraliser les journaux et la télémétrie de sécurité dans l’architecture lakehouse, puis y faire opérer des agents défensifs capables de détecter et d’investiguer les menaces.
Les SOC croulent sous les logs, les alertes, les signaux faibles et les outils spécialisés. Les SIEM traditionnels, même modernisés, restent coûteux, complexes et parfois mal adaptés à l’explosion des volumes. Databricks pense que la sécurité doit revenir dans le lakehouse, là où résident déjà les données d’entreprise, les journaux, les historiques, les pipelines et désormais les agents.
« Si l’on vous attaque avec des agents, vous devez vous défendre avec des agents. Il faut combattre le feu par le feu » affirme Ali Ghodsi. Les attaquants automatisent la reconnaissance, l’exploitation, le phishing, la génération de code malveillant et l’adaptation en temps réel. Les défenseurs ne peuvent plus seulement empiler des règles statiques et des alertes manuelles.

Avec Panther, Databricks récupère des capacités de détection, d’investigation et de workflow SOC, avec l’idée de les connecter au Lakehouse, à Lakewatch et à ses briques agentiques.
Reste qu’en proposant des flux de travail de SOC agentiques sur le même socle de données que l’analytique et l’IA, Databricks s’attaque à un marché tenu par Splunk, Microsoft Sentinel ou CrowdStrike et sur lequel Elastic, Google, Palo Alto Cortex, Exabeam, Sumo Logic et nombre d’acteurs du XDR ont aussi des velléités.
6. Lakeflow nouvelle génération : le data engineering devient agentique
Autre sujet, Databricks pousse l’ingénierie des données vers l’automatisation assistée par agents avec une refonte d’ampleur de Lakeflow.
Genie Code s’intègre désormais à toutes les étapes (création de connecteurs, construction de pipelines en Python ou SQL, orchestration).
Lakeflow Designer passe en disponibilité générale : cette interface visuelle sans code, pilotée en langage naturel, permet à des analystes métiers de bâtir des chaînes de traitement de qualité production, qui s’exécutent nativement sur des pipelines déclaratifs Spark sans rupture ni perte de traduction.
Plus audacieux encore, Genie ZeroOps est un agent d’arrière-plan qui surveille les actifs en production, détecte les incidents, en réalise l’analyse de cause racine et propose des correctifs validés dans un bac à sable, l’humain gardant la main sur l’application finale.
L’éditeur complète l’édifice par un écosystème de plus de cent connecteurs natifs (de Jira à SharePoint, de HubSpot aux régies publicitaires Meta, TikTok et Google), par Zerobus Ingest, qui ingère des événements à haut débit sans bus de messages, et par un mode temps réel pour les pipelines déclaratifs Spark affichant des latences de bout en bout de l’ordre de cinq millisecondes.
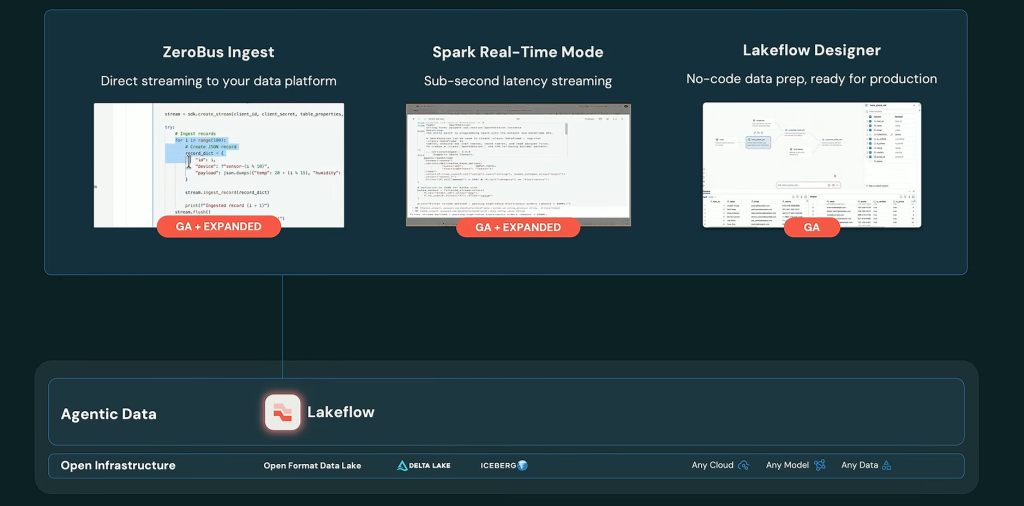
La promesse est de réduire la fragmentation des chaînes data. Dans beaucoup d’entreprises, l’ingestion passe par un outil, la transformation par un autre, l’orchestration par Airflow ou équivalent, la qualité par une brique spécialisée, l’observabilité par un autre service, et les incidents par Slack, PagerDuty ou des scripts maison. Réduire la fragmentation, c’est réduire la complexité qui freine l’industrialisation.
Tout comme Snowflake et son Openflow, Databricks cherche ici à absorber une partie du terrain occupé par Fivetran, dbt, Airflow, Informatica, Talend, Matillion, Confluent ou les architectures Flink maison.
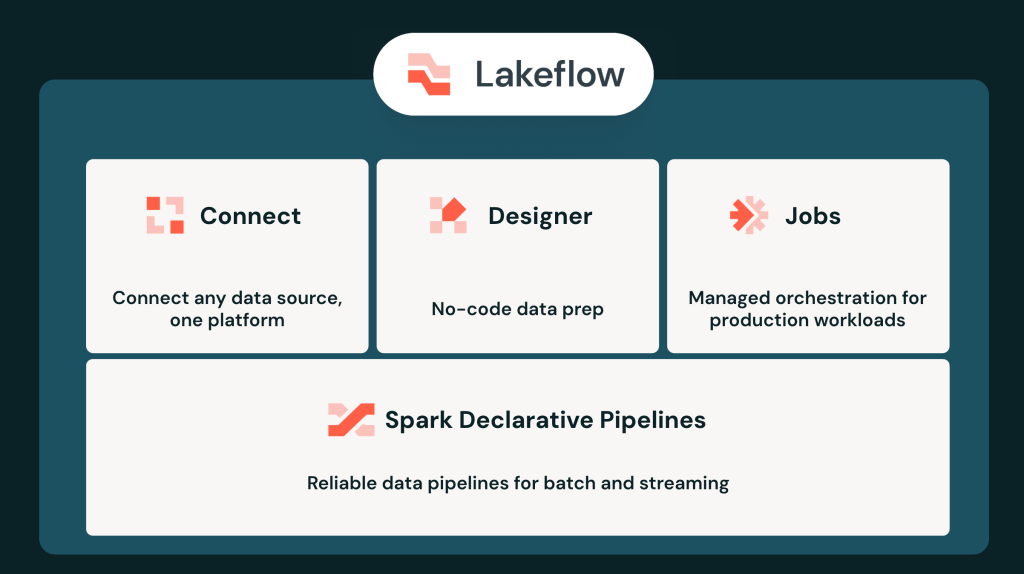
L’enjeu DSI est évidemment de rendre les pipelines compréhensibles, auditables, gouvernés et moins dépendants de quelques experts rares. L’automatisation agentique du data engineering peut être une réponse, à condition de ne pas transformer les pipelines en boîtes noires générées par IA. Dans ce domaine, la transparence du code, la traçabilité des transformations et la gestion des changements resteront essentielles.
7. OpenSharing : Delta Sharing s’ouvre aux modèles, aux agents et aux compétences
Pionnier du partage ouvert de données avec Delta Sharing en 2021, Databricks en publie une évolution « agentique » sous le nom d’OpenSharing : un protocole ouvert et neutre vis-à-vis des fournisseurs, désormais hébergé par la Linux Foundation, et premier du genre à couvrir non seulement les données, mais aussi les modèles d’IA, les compétences d’agents et les contenus non structurés. Il ne s’agit plus seulement de partager des données entre clouds, formats et fournisseurs, mais aussi des modèles, des agents et des compétences réutilisables.
Le protocole ajoute le support des clients Iceberg (catalogue REST) et, via des partenaires de stockage comme MinIO ou Qumulo, permet de connecter des actifs sur site ou en cloud privé sans mouvement de données.
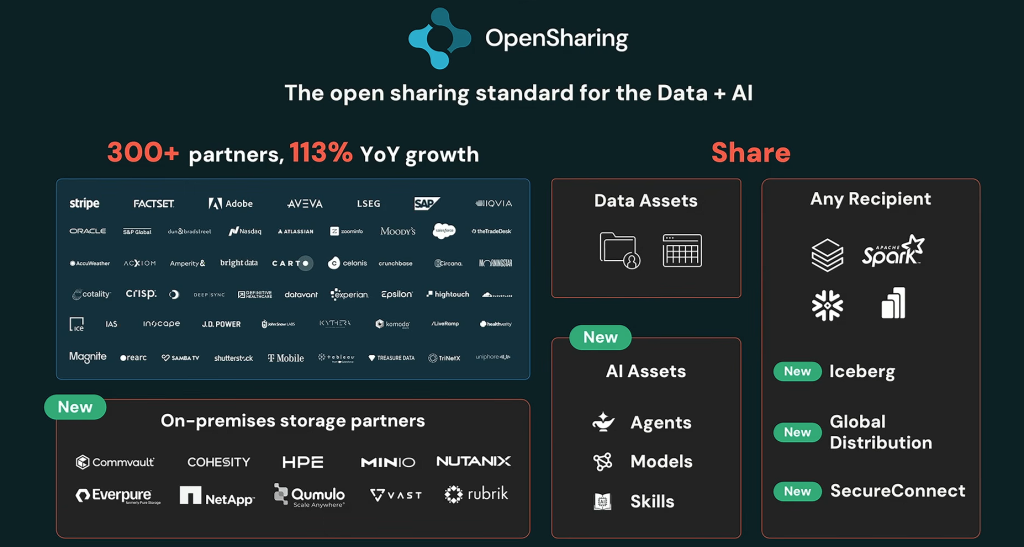
Databricks anticipe ici un changement de nature du partage de données. Dans l’entreprise agentique, on ne partagera plus uniquement des tables ou des fichiers. On partagera aussi des capacités : un modèle de scoring, un agent d’analyse, une compétence de conformité, un outil métier, une fonction de segmentation, une logique de détection. Databricks veut que ces actifs puissent circuler sans verrouillage excessif.
8. Lakebase Search : la recherche hybride au plus près de la mémoire des agents
Plus discrète mais révélatrice de la direction prise par l’éditeur, Lakebase Search intègre désormais une recherche hybride (vectorielle et plein texte) directement dans Lakebase, la base PostgreSQL opérationnelle de Databricks. L’objectif est explicitement pensé pour les boucles d’agents et la mémoire opérationnelle : permettre à un agent de retrouver instantanément le bon document ou la bonne donnée dans le flux de son raisonnement, sans détour par un moteur de recherche tiers.
Databricks veut ainsi rapprocher la recherche sémantique et textuelle d’une base Postgres opérationnelle, afin que les agents puissent retrouver, comparer, contextualiser et mémoriser des informations sans dépendre d’une architecture trop dispersée.
Pour les DSI, le bénéfice potentiel est la réduction du « RAG sprawl », cette multiplication de petits pipelines, index et embeddings difficiles à maintenir.
9. CustomerLake : Databricks entre par la grande porte dans le marketing
Avec CustomerLake, l’éditeur signe son incursion la plus nette dans le marketing : une plateforme de données clients (CDP) agentique, intégrée nativement au lakehouse, pour construire une vision client à 360°, segmenter les audiences, activer les campagnes et personnaliser les parcours. Disponible en préversion privée, l’offre adopte un modèle de facturation à la consommation, présenté comme une alternative économique aux licences logicielles traditionnelles, dans une logique assumée de consolidation et de réduction de la dépense marketing.
Databricks attaque le territoire de Salesforce Data Cloud, d’Adobe Experience Platform et de Twilio Segment, sur un marché de la CDP où les directions marketing ploient sous l’empilement d’outils.
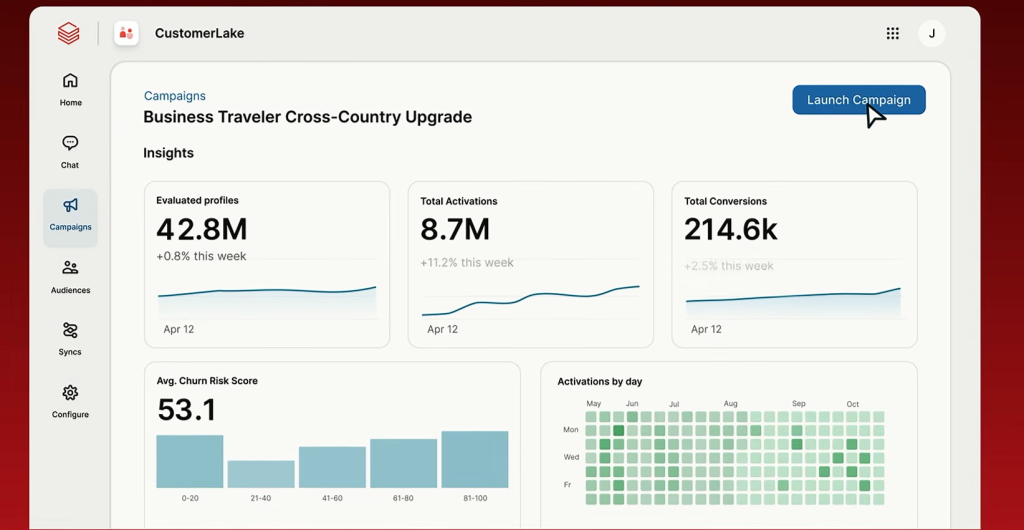
Dans la vision de l’éditeur, mieux vaut construire les capacités marketing directement sur le Lakehouse, plutôt que d’envoyer les données client vers une CDP séparée, car c’est là où résident déjà les données transactionnelles, comportementales, analytiques et IA. CustomerLake ajoute des agents de profil et de campagne pour aider les équipes marketing à comprendre les clients, créer des segments, personnaliser les interactions et activer les canaux.
C’est probablement l’annonce la plus métier du Summit. Elle montre que Databricks ne veut plus seulement parler aux data engineers, data scientists et architectes. Il veut aussi convaincre les directions marketing et les directions métiers que le Lakehouse peut devenir une plateforme d’action.
10. Apps on Databricks Marketplace : gouverner le “vibe coding” avant qu’il ne dérape
La dernière annonce phare, Databricks pousse les Apps sur son Marketplace et encadre la montée du « vibe coding », c’est-à-dire la création rapide d’applications par IA à partir d’intentions formulées en langage naturel.
Avec Apps on Databricks Marketplace, les entreprises pourront découvrir, installer et exécuter des applications data et IA tierces directement dans leur environnement Databricks, sans sortir les données du cadre gouverné par Unity Catalog. C’est un argument fort dans un contexte où les directions métiers réclament des applications rapides, mais où les DSI redoutent la prolifération de petits outils non maîtrisés.
Pour accompagner le mouvement, Databricks dégaine tout un arsenal pour démocratiser la création : App Spaces, Genie App Builder (un générateur d’applications piloté par Genie) et Serverless Micro Apps (des micro-applications sans serveur. L’idée est de permettre à des utilisateurs de créer ou déployer des apps plus facilement, tout en les isolant, en les gouvernant et en maîtrisant leur exécution. C’est une réponse au phénomène que toutes les entreprises vont rencontrer : après le shadow IT, puis le shadow AI, voici le risque du shadow app building. Des collaborateurs pourront générer des micro-applications utiles en quelques minutes. Mais qui les sécurise ? Qui les maintient ? Qui vérifie leurs accès aux données ? Qui paie leur exécution ? Qui les retire lorsqu’elles deviennent obsolètes ? C’est à ces questions que Databricks veut aujourd’hui répondre en canalisant l’énergie du « vibe coding » au sein même de sa plateforme.
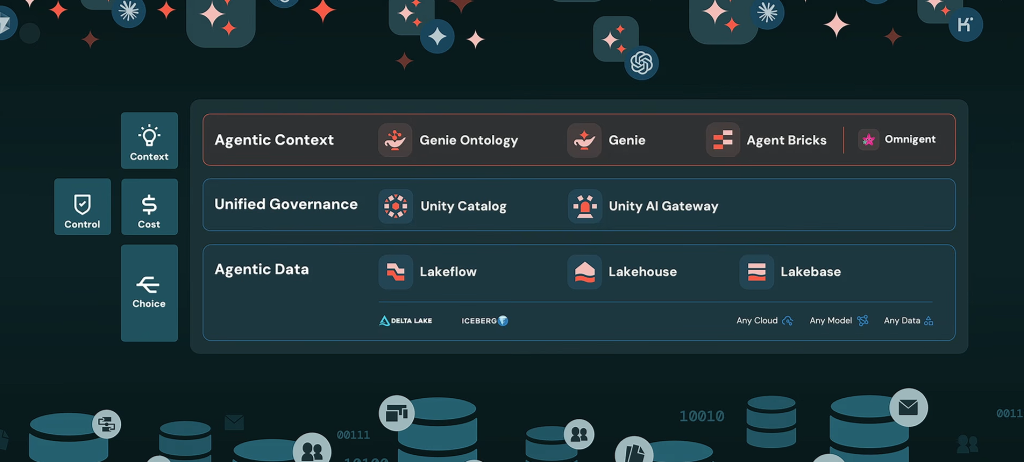
Au final, difficile de ne pas tracer de parallèle entre les annonces de Snowflake et celles de Databricks. Logique. Les deux éditeurs se livrent désormais la même bataille : devenir le plan de contrôle de l’IA d’entreprise.
Il y a 15 jours, Snowflake est parti de son Data Cloud, de son modèle de gouvernance, de son entrepôt analytique et de son écosystème marketplace.
Au « Data + AI Summit 2026 », Databricks a montré comment il fait de son Lakehouse la plateforme d’exécution de l’entreprise agentique. Les agents y trouvent leur contexte avec Genie Ontology, leur interface métier avec Genie One, leur plateforme avec Agent Bricks, leur gouvernance runtime avec Unity AI Gateway, leur mémoire avec Lakebase Search, leur temps réel avec Lakehouse//RT, leurs pipelines avec Lakeflow, leurs actifs partagés avec OpenSharing, leurs usages marketing avec CustomerLake et leurs applications avec Apps on Marketplace.
Dit autrement, le marché demande aujourd’hui aux DSI non plus de choisir un data warehouse ou un lakehouse mais de choisir où vivront les agents, où sera gouverné leur contexte, où seront contrôlés leurs coûts, où seront tracées leurs actions et où seront exécutées les applications qu’ils généreront.
Databricks ne vend plus seulement une architecture de données. Il vend une architecture de travail pour l’ère agentique.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :