


Data / IA
Les dix annonces clés du Snowflake Summit 2026
Par Laurent Delattre, publié le 12 juin 2026
Au Snowflake Summit 2026, organisé du 1er au 4 juin au Moscone Center de San Francisco, l’éditeur a déroulé une feuille de route incontestablement dense. Derrière les annonces produits, émerge une nouvelle réalité : Snowflake ne veut plus seulement être la plateforme où résident les données, mais celle où les agents les comprennent, les gouvernent, les sécurisent et les transforment en actions. Petit tour d’horizon…
Les grands shows technologiques sont devenus des exercices d’équilibriste entre innovations avant-gardistes et grosse piqure marketing. Et le Snowflake Summit 2026 n’a pas fait exception. Beaucoup de scène, beaucoup d’IA, beaucoup de démonstrations, mais aussi une pression plus concrète et omniprésente : montrer que sa plateforme peut absorber la complexité opérationnelle qui accompagne désormais les projets data et IA agentique. L’événement, tenu à San Francisco du 1er au 4 juin 2026 devant plus de 20 000 participants, a rassemblé une avalanche d’annonces autour des agents, de la gouvernance, de la sémantique, de la sécurité, du streaming, des modèles et de l’ouverture « lakehouse ». Snowflake y a mis en avant plus de 500 sessions et ateliers pratiques, dans un Summit placé sous le thème officiel « Making AI Real for Business », rendre l’IA réelle pour l’entreprise, avec l’« entreprise agentique » comme fil conducteur de bout en bout. Toute la stratégie de Snowflake consiste désormais à rendre ces agents fiables, contrôlables et exploitables en production.
La tonalité du show était donc moins celle d’un éditeur ajoutant une couche IA à son entrepôt de données que celle d’un acteur qui veut reprendre la main sur toute la chaîne : données, contexte, modèles, exécution, contrôle et audit. Snowflake ne vend plus seulement un Data Cloud, mais une architecture d’exploitation de l’IA d’entreprise.
1. CoWork, l’agent métier qui veut sortir la donnée des tableaux de bord
Sans contexte l’annonce la plus visible, Snowflake CoWork est le nouveau nom et l’évolution agentique logique de Snowflake Intelligence. Le produit est présenté comme un agent personnel pour les collaborateurs, capable d’interroger les données, de produire des analyses, de créer des artefacts (rapports, tableaux de bord interactifs), d’interagir avec des outils du quotidien et, surtout, de passer progressivement de la réponse à l’action. Au passage, CoWork s’invite directement dans Slack, dans Excel, sur mobile via une application iOS, et se connecte à Gmail, Google Drive ou Salesforce.

Depuis des années, Snowflake a profité du mouvement de centralisation analytique dans le cloud. Mais les tableaux de bord et requêtes SQL ne suffisent plus à faire circuler l’intelligence dans l’entreprise : il faut savoir où chercher, savoir interroger, savoir interpréter. Avec CoWork, l’éditeur tente de déplacer l’usage de la donnée vers les flux de travail réels des collaborateurs. Autrement dit, ne plus demander à l’utilisateur d’aller chercher la donnée, mais faire venir l’agent là où travaille l’utilisateur, qui peut alors poser ses questions en langage naturel, comme il le ferait à un collègue.
Avec CoWork, Snowflake cherche à remplacer les tableaux de bord par un collègue proactif qui interroge la donnée, rédige l’analyse et déclenche l’action, directement dans Slack, Excel ou la boîte mail, sans jamais sortir du cadre gouverné de la plateforme.
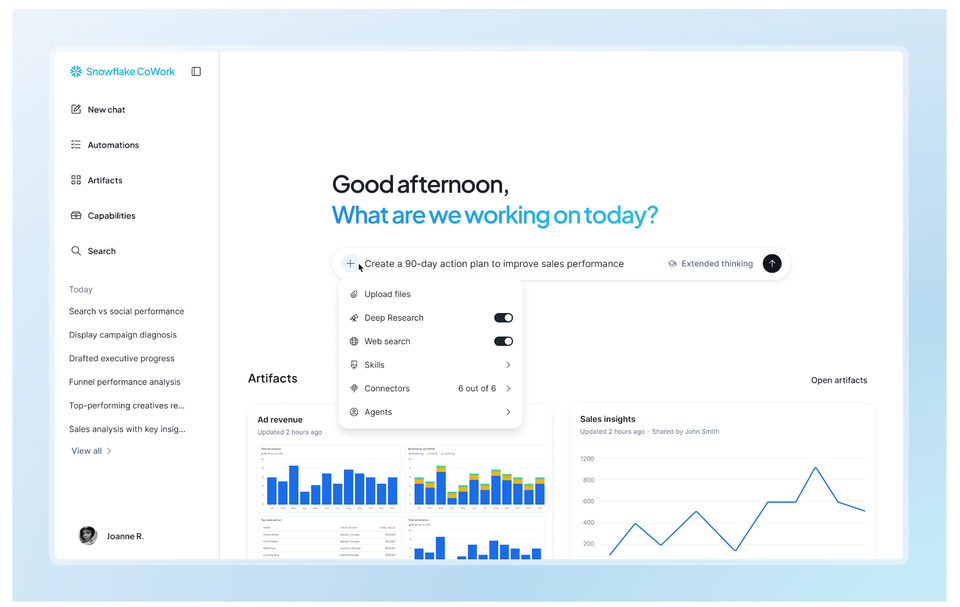
Sur le fond, CoWork marque aussi un changement de posture. Snowflake ne parle plus seulement aux équipes data. L’éditeur veut s’adresser aux ventes, à la finance, aux opérations, au support, aux RH, bref plus directement aux métiers. Mais cette ambition a un prix : pour être utile, un agent métier doit comprendre les définitions, les règles, les droits, les exceptions et les implicites d’une organisation. C’est précisément ce qui explique les autres annonces du Summit 2026. CoWork n’est pas un produit isolé. C’est la vitrine d’un socle beaucoup plus large.
2. Deep Research, la recherche augmentée sous contrôle de l’entreprise
Avec Deep Research dans CoWork, Snowflake reprend une mécanique devenue familière depuis que ChatGPT, Gemini ou Claude l’ont popularisée : l’IA explore plusieurs sources, raisonne en plusieurs étapes et produit une synthèse argumentée, plutôt qu’une réponse instantanée. Mais la différence revendiquée ici tient au périmètre : l’analyse s’effectue sur les données de l’entreprise (tableaux chiffrés, documents texte, etc.) dans un cadre gouverné, en respectant les droits d’accès de chaque utilisateur, et en citant systématiquement ses sources.
C’est une annonce intéressante parce qu’elle répond à un usage déjà installé dans les pratiques : les collaborateurs veulent des réponses synthétiques, contextualisées, argumentées, et non une pile de rapports ou de tableaux de bord à dépouiller. Mais en entreprise, cette recherche augmentée doit respecter des règles strictes : ne montrer à chacun que ce qu’il a le droit de voir, tracer ses sources, éviter les fuites et parler le vocabulaire du métier.
La valeur de Deep Research dépendra donc moins de la performance brute du modèle que de la qualité du corpus, de la gouvernance et de la couche sémantique disponible. Désormais, pour Snowflake, tout le défi est d’arriver à transformer un usage séduisant en fonction exploitable dans des environnements où l’information est fragmentée, sensible et souvent imparfaitement qualifiée.
Deep Research dans CoWork s’appuie sur l’architecture ArcticSwarm, le système multi-agents développé par l’équipe de recherche de Snowflake. Plutôt que de confier une question complexe à un agent unique, ArcticSwarm fait travailler en parallèle plusieurs agents aux historiques et aux points de vue volontairement différents, puis les fait se relire mutuellement avant de trancher. Le principe revendiqué est celui du « désaccord par conception » : on laisse les agents former des hypothèses indépendantes, on les fait confronter leurs preuves sur un espace de travail centralisé, et l’on traite le désaccord analytique comme un outil de vérification plutôt que comme un obstacle à supprimer. Les chiffres avancés par Snowflake ne sont pas inintéressants : sur le benchmark BrowseComp, ArcticSwarm atteint 73,6 % avec GPT-5, contre 54,9 % pour la recherche approfondie d’OpenAI et 63,4 % pour MiroFlow, une référence open source dans le domaine.
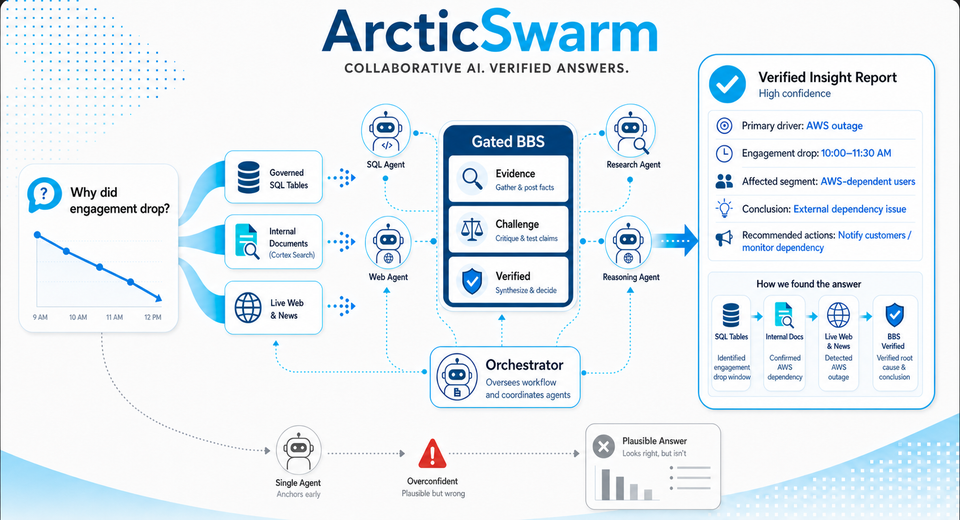
3. Cortex Sense, la brique qui donne du contexte aux agents
Et puisque l’on parle de contexte, et de faire en sorte que les IA répondent juste au lieu de répondre bien, l’une des annonces les plus structurantes et stratégiques n’est autre que Cortex Sense. Son rôle consiste à apporter automatiquement aux agents (et notamment à CoWork comme à CoCo, cf plus loin) une compréhension des règles métier, des définitions, des indicateurs, des relations entre données et des logiques opérationnelles de l’entreprise. Pour cela, la brique s’appuie sur des signaux déjà présents dans la plateforme : historique des requêtes, métadonnées, tableaux de bord existants (y compris Power BI ou Tableau).
Dit plus simplement, Cortex Sense est la mémoire métier des agents IA de Snowflake : la couche qui leur apprend ce qu’est un « client actif » ou une « marge nette » dans votre entreprise.

C’est aussi une façon de rappeler aux DSI qu’un agent d’entreprise ne peut pas seulement être branché sur des tables, des fichiers et des API. Il doit savoir ce qu’est, dans cette organisation précise, un « client actif », un « incident prioritaire » ou une « opportunité qualifiée ». Or ces définitions changent souvent selon les métiers, les pays et les systèmes. Sans cette couche de contexte, l’agent risque de produire des réponses bien tournées… mais fausses opérationnellement. Snowflake avance d’ailleurs un chiffre éloquent issu de ses tests internes : sur des questions d’entreprise complexes, ses agents passeraient de 47 % à 83 % de réponses exactes lorsqu’ils s’appuient sur Cortex Sense. La brique n’en est toutefois qu’à ses débuts : elle est lancée en avant-première privée, donc réservée pour l’instant à quelques clients testeurs.
Cortex Sense est une tentative de Snowflake de résoudre l’un des défis de l’IA appliquée à l’entreprise : l’ambiguïté. L’éditeur semble avoir bien compris que la bataille ne se joue pas uniquement sur les modèles, mais sur la capacité à leur fournir un contexte fiable, contrôlé et partagé.
4. CoCo, l’agent des développeurs et de l’ingénierie des données
Autre annonce importante : Snowflake CoCo, nouveau nom de Cortex Code. Là encore, le nom change, mais surtout l’ambition se précise. CoCo vise les développeurs, les ingénieurs data et les équipes plateforme. Il doit aider à construire des chaînes de traitement de données (les fameux « pipelines »), automatiser des tâches récurrentes, développer des applications analytiques et intervenir directement dans les environnements de développement. Ainsi, CoCo existe en application de bureau, en extension pour VS Code ou Excel, et s’interface même avec Claude Code d’Anthropic.

Si CoWork est l’agent des métiers, CoCo est l’agent des constructeurs. Snowflake tente ainsi de couvrir les deux extrémités de la chaîne : ceux qui consomment l’intelligence et ceux qui bâtissent les composants nécessaires à son exploitation.
L’intérêt pour les DSI est double. D’abord, CoCo peut accélérer des tâches souvent coûteuses : transformation de données, génération de code, documentation, maintenance des chaînes de traitement. Ensuite, il inscrit cette productivité dans l’environnement Snowflake, avec les contrôles de sécurité, de droits et d’audit associés. Le revers est évident : plus CoCo devient efficace, plus la plateforme va devenir incontournable dans les processus de développement data.
5. Cloud Agents, SDK et Skill Catalog : l’agentique passe de la démo à l’exploitation
Snowflake a également annoncé des briques destinées à industrialiser les agents : Cloud Agents (des agents qui s’exécutent en arrière-plan dans le cloud de Snowflake, sans qu’un poste de travail reste allumé), un CoCo Agent SDK (une boîte à outils permettant aux développeurs d’intégrer ces agents dans leurs propres applications), un bac à sable sécurisé (un environnement isolé où l’agent peut exécuter du code sans toucher au reste du système), ainsi que des compétences réutilisables (les « Skills ») et un catalogue pour les partager, le Skill Catalog.
Des annonces qui marquent une évolution essentielle : l’agent IA doit devenir un composant logiciel gouverné, réutilisable, observable et intégrable.
Beaucoup de projets d’agents se heurtent à la même limite : ils fonctionnent en démonstration, mais deviennent difficiles à administrer dès qu’il faut gérer les permissions, les erreurs, les appels à des outils tiers, les coûts et les responsabilités. En introduisant un catalogue de compétences et des agents exécutables dans le cloud, Snowflake cherche à apporter une réponse de plateforme.
Cette approche a aussi une portée organisationnelle. Elle suppose que les entreprises commencent à gérer les agents comme elles gèrent déjà les applications, les API ou les chaînes de traitement, avec des cycles de vie, des propriétaires, des politiques de sécurité et des contrôles d’usage.
6. Horizon Catalog et Horizon Context : la gouvernance devient le moteur de l’IA
Avec Horizon Catalog et Horizon Context, Snowflake veut faire de la gouvernance la couche centrale de sa stratégie IA.
Horizon Catalog sert de socle de catalogage (l’inventaire de toutes les données disponibles), de sécurité, de contrôle et de traçabilité — savoir d’où vient chaque donnée et par quelles transformations elle est passée, ce que les spécialistes appellent le « lignage ».
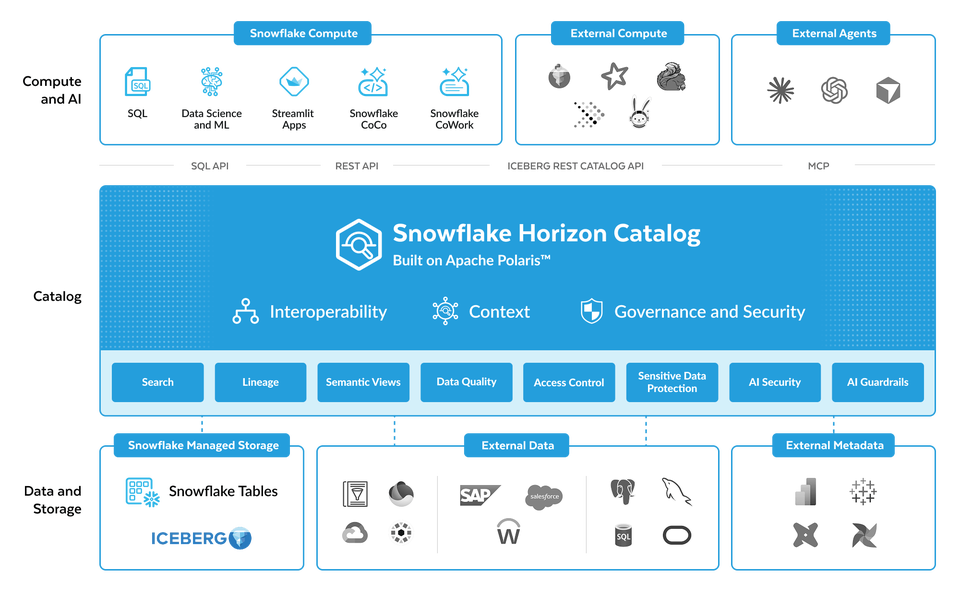
Horizon Context ajoute une dimension sémantique : il aligne les définitions métier, les indicateurs et les relations entre données, pour que le SQL, les outils décisionnels, les applications et les agents parlent enfin le même langage.
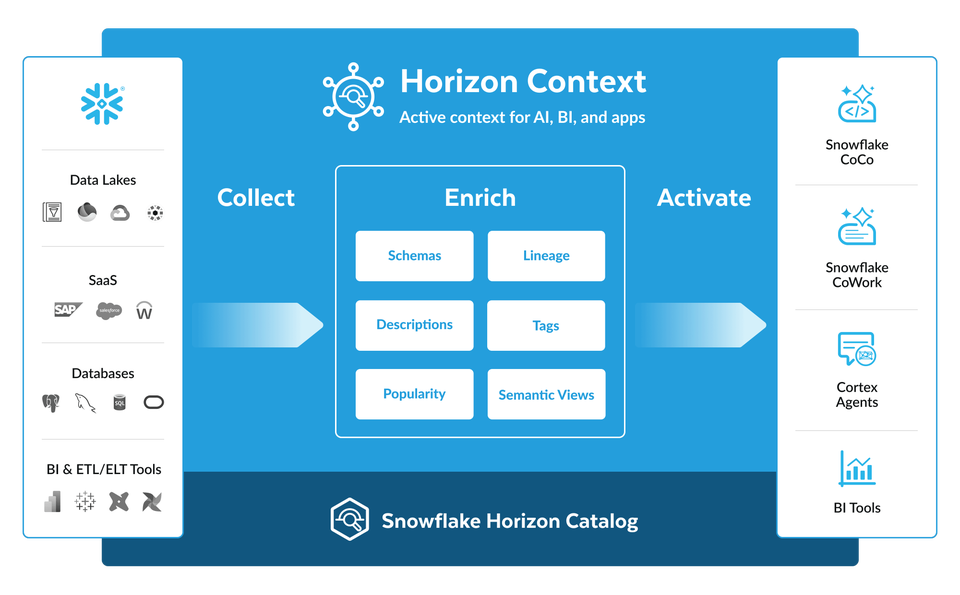
C’est probablement l’une des annonces les plus importantes du Summit. Dans les architectures data classiques, la gouvernance est souvent perçue comme une contrainte, un passage obligé pour la conformité, la sécurité ou l’audit. Dans une architecture agentique, elle devient une condition de fonctionnement. Un agent qui ne sait pas quelles données il peut consulter, comment les interpréter, quelles règles appliquer et comment tracer ses actions n’est tout simplement pas industrialisable.
Snowflake veut ainsi imposer Horizon en plan de contrôle de l’IA d’entreprise et en faire le poste de pilotage d’où l’on décide ce que les agents peuvent voir et faire. Dans cette vision, le catalogue n’est plus un inventaire de données, mais un fournisseur de contexte et de règles pour les agents.
7. Sécurité agentique : identifier les agents, contrôler leurs actions
Snowflake a aussi beaucoup insisté sur la sécurité : identité des agents, garde-fous IA, détection des injections de requêtes (ces instructions malveillantes glissées dans un document ou un message pour détourner le comportement d’une IA qui le lit), surveillance via le Trust Center, bac à sable d’exécution, politiques de mouvement de données, protection contre l’exfiltration et les rançongiciels, avec validation à plusieurs pour les opérations sensibles. Les annonces autour d’Agent Identity sont particulièrement révélatrices : chaque agent reçoit une identité vérifiée et chacune de ses actions est tracée. Car dans un système agentique, il ne suffit plus de savoir quel utilisateur a accès à quelles données ; il faut aussi savoir quel agent agit, pour le compte de qui, avec quels droits et dans quel contexte.
C’est une bascule majeure pour les RSSI. Les agents brouillent les frontières traditionnelles entre utilisateur, application, script et automatisation. Ils peuvent lire, interpréter, déclencher, écrire, transférer, résumer. Leur surface de risque est donc plus large que celle d’un simple robot conversationnel.
Snowflake cherche ici à rassurer en intégrant la sécurité dans son propre plan de contrôle. Reste une question de fond : jusqu’où ces garde-fous suffiront-ils lorsque les agents se connecteront à des environnements hétérogènes, à des outils tiers et à des données hors Snowflake ?
Le projet d’acquisition de Natoma, annoncé pendant le Summit, répond précisément à cette tension. Cette jeune pousse s’est spécialisée dans la sécurisation des connexions MCP, devenu le standard de fait pour brancher les agents IA sur des applications externes (messagerie, CRM, outils de tickets…). Natoma doit permettre d’ouvrir les agents vers l’extérieur sans perdre la maîtrise des accès.
8. Cortex Training : adapter les modèles au plus près des données
Snowflake a aussi enrichi son offre IA avec Cortex Training, un service destiné à entraîner ou adapter des modèles « open weight » (ces modèles dont les paramètres internes sont publiés, comme ceux des familles Qwen ou Mistral, et que chacun peut donc personnaliser) directement au contact des données de l’entreprise, sur des processeurs graphiques entièrement gérés par Snowflake. Objectif ? Permettre aux entreprises de spécialiser un modèle sur leur propre savoir sans déplacer leurs données sensibles hors de l’environnement gouverné, et sans avoir à administrer elles-mêmes une infrastructure d’entraînement.
Ce service complète une palette de modèles déjà large dans Cortex AI : on y trouve les modèles Claude d’Anthropic (partenariat encore approfondi à l’occasion du Summit, Claude motorisant désormais CoWork et CoCo) mais aussi les modèles d’OpenAI, dont l’intégration découle, elle, du partenariat de 200 millions de dollars scellé entre les deux entreprises en février 2026, quelques mois avant le Summit.
Cette stratégie illustre le repositionnement de Snowflake. L’éditeur ne veut plus être uniquement le lieu où l’on stocke et analyse les données ; il veut devenir le lieu où l’on exécute les charges IA, où l’on adapte les modèles, où l’on applique les politiques de sécurité et où l’on contrôle les usages. Le pari est cohérent : les données restent le principal différenciateur de l’IA d’entreprise. Snowflake mise sur son avantage historique : la donnée gouvernée déjà présente dans la plateforme.
9. Datastream : le temps réel devient une brique native
Les agents, les modèles de scoring, les systèmes de détection, les applications de chaîne logistique, les usages cybersécurité ou les opérations clients ne peuvent pas s’appuyer uniquement sur des données « froides », rafraîchies une fois par nuit. Ils ont besoin de données fraîches, parfois continues, et surtout gouvernées dès leur arrivée dans la plateforme.
Avec Snowflake Datastream, l’éditeur renforce son entrée dans les usages temps réel. Pour comprendre l’annonce, il faut savoir qu’Apache Kafka est devenu le standard de fait du « streaming » de données : une sorte d’autoroute logicielle sur laquelle circulent en continu les événements générés par les applications — une commande passée, un capteur qui remonte une mesure, une transaction bancaire. Puissant, mais lourd à installer et à maintenir. Datastream est un service entièrement géré et compatible Kafka : les applications existantes peuvent y envoyer leurs flux sans modification, et les données arrivent dans Snowflake en quelques secondes, sans qu’il faille entretenir une infrastructure Kafka séparée.
Datastream montre que Snowflake veut réduire l’écart entre l’entrepôt analytique, la plateforme applicative et l’infrastructure événementielle. C’est une évolution logique, mais aussi délicate : le streaming est un domaine exigeant, où la latence, la résilience, les coûts et l’intégration avec l’existant sont décisifs.
10. Iceberg, Polaris et l’Interoperable Lakehouse
Enfin, Snowflake a renforcé son discours autour de l’« Interoperable Lakehouse ». Derrière ce jargon, une idée simple : permettre à plusieurs moteurs d’analyse (Snowflake, mais aussi Spark, Trino et d’autres) de lire et d’écrire les mêmes données, sans les dupliquer, ni les convertir.
Deux technologies en open source rendent cela possible :
* Apache Iceberg, d’abord, un format ouvert qui décrit comment stocker de très grandes tables de données de manière à ce que n’importe quel moteur compatible puisse les exploiter. Durant Summit 2026, Snowflake a annoncé la disponibilité générale de sa version 3 et un nouveau service de stockage dédié, Snowflake Storage for Apache Iceberg Tables.
* Apache Polaris, ensuite, un catalogue libre qui motorise désormais Horizon Catalog et autorise la lecture comme l’écriture de ces tables depuis des moteurs externes tout en conservant les règles de sécurité fixées dans Snowflake, jusqu’au masquage de colonnes ou au filtrage de lignes.
Cette annonce doit être lue à deux niveaux. Offensivement, Snowflake veut attirer les organisations qui souhaitent bénéficier de sa plateforme sans enfermer toute leur architecture dans un format propriétaire. Défensivement, l’éditeur répond à une inquiétude persistante : la dépendance à une plateforme unique.
Le sujet est sensible. Les entreprises veulent de l’intégration, mais pas au prix d’un verrouillage excessif. Elles veulent de la gouvernance, mais pas forcément un moteur unique. Elles veulent de la performance, mais aussi de la portabilité. En poussant Iceberg, Polaris et l’accès multi-moteur, Snowflake tente de concilier ces attentes parfois contradictoires.
Snowflake veut devenir le plan de contrôle de l’entreprise agentique
Pris isolément, chaque annonce peut sembler attendue : un agent métier, un agent développeur, du contexte, de la gouvernance, du streaming, des modèles, du lakehouse ouvert. Mais leur cohérence globale est plus intéressante que leur accumulation. Snowflake ne cherche pas seulement à ajouter de l’IA à son Data Cloud. Il cherche à devenir la plateforme d’exécution et de contrôle de l’IA d’entreprise.
C’est une ambition considérable. Elle suppose de résoudre simultanément des problèmes de données, de sémantique, de sécurité, d’orchestration, de coût, de performance, d’intégration et de gouvernance. Elle suppose aussi de convaincre les DSI que Snowflake peut jouer ce rôle sans devenir une dépendance supplémentaire trop structurante.
Au final, ce Summit 2026 aura bien marqué un tournant. Snowflake n’y a pas seulement parlé de données augmentées par l’IA. Il a décrit une architecture dans laquelle les agents deviennent des utilisateurs de la donnée, les catalogues deviennent des fournisseurs de contexte, la gouvernance devient un moteur d’exécution et la sécurité doit suivre chaque action automatisée.
Reste une question clé : les entreprises adopteront-elles cette vision comme un raccourci vers l’industrialisation de l’IA, ou la verront-elles comme une nouvelle plateformisation à surveiller de près ? C’est probablement là que se jouera la prochaine étape de Snowflake. En attendant de voir comment va lui répondre son principal concurrent, Databricks, dont la grande conférence annuelle a lieu la semaine prochaine. A suivre donc…
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :











