


Cloud
AWS re:Invent 2025 : Amazon transforme l’IA agentique en chaîne de montage industrielle
Par Laurent Delattre, publié le 05 décembre 2025
À re:Invent 2025, AWS a déroulé une vision très industrielle de l’IA agentique, en alignant nouveaux processeurs, AI Factories, S3 vectoriel, modèles Nova 2 et runtime AgentCore. L’événement consacre le cloud d’Amazon comme chaîne de fabrication d’agents IA, des modèles frontier jusqu’aux agents Dev, Sec et Ops mis en production.
Sur le fond, les discours d’AWS, de Microsoft et de Google convergent désormais presque mot pour mot. Les trois promettent que les agents IA vont devenir la nouvelle interface universelle, la nouvelle « user experience » du cloud et des processus d’entreprise. Les agents IA s’invitent déjà dans la chaîne DevOps, dans la cybersécurité, dans la gouvernance de la donnée et commencent à pénétrer les métiers. Et tous affirment qu’il faudra industrialiser cette IA agentique : la sécuriser, la gouverner, l’observer, l’orchestrer, la connecter à des systèmes critiques.
Mais, comme toujours, la différence se niche dans les détails et la façon de structurer la pile technologique. À re:Invent 2025, AWS a surtout voulu démontrer qu’il maîtrise toute la chaîne de valeur de l’IA, du silicium jusqu’aux agents métiers. Là où Microsoft se met en scène comme l’« OS des Frontier Firms » avec Microsoft Fabric, Azure Foundry et ses Copilots, et où Google pousse son AI HyperComputer, Vertex AI et Gemini AI Enterprise pour s’afficher en orchestrateur d’écosystèmes agentiques, AWS reste fidèle à son positionnement « industriel » : fournir des briques, beaucoup de briques, et laisser chaque client assembler sa propre solution idéale.
L’invitation implicite faite aux DSI est finalement assez simple : « Venez fabriquer, personnaliser et faire tourner vos modèles et vos agents IA à grande échelle chez nous, au meilleur coût possible, avec des briques cohérentes de bout en bout. »
L’édition 2025 de re:Invent a déroulé cette promesse un peu dans tous sens : nouveaux processeurs Trainium et GPU Blackwell, AI Factories on-prem, S3 vectoriel, Nova 2 et modèles open-weight, Bedrock AgentCore, Strands Agents, agents Frontier comme Kiro, Nova Act pour automatiser les interfaces web, et un important bloc sécurité (GuardDuty, Security Hub, AgentCore Policy, IAM Policy Autopilot…).
Pour en mesurer la cohérence, le plus simple est de remonter cette pile agentique depuis l’infrastructure IA jusqu’aux agents IA mis en production.
Des infrastructures pour l’IA
Comme le démontre la valorisation actuelle de Nvidia, mais aussi les récentes annonces de Google avec IronWood ou de Microsoft avec Cobalt 200, l’ère de l’IA démarre du socle d’infrastructure. Et AWS avait beaucoup de choses à raconter et annoncer.
Les besoins des modèles de fondation et des agents sont connus : densité de calcul massive, interconnexion très haut débit, stockage à très forte bande passante, et surtout coût par token le plus bas possible.
AWS répond en empilant trois piliers : son propre silicium (Trainium, Inferentia, Graviton), les GPU NVIDIA de dernière génération, notamment pour l’entraînement, une couche Kubernetes/EKS et même une plateforme SageMaker HyperPod pensée pour l’ultra-scale. L’objectif est évident : convaincre les grands comptes, les labos et les États que la prochaine génération de modèles et d’agents peut être entraînée et exploitée de manière fiable sur AWS… voire dans leurs propres datacenters via les nouvelles AWS AI Factories.
Graviton5, le super CPU pour des infras plus économes
Annoncé au dernier jour de l’AWS « re:invent 2025 », Graviton5 marque un nouvel échelon dans la stratégie de l’hyperscaler de concevoir ses propres processeurs afin de réduire les coûts et de ne plus dépendre intégralement de fournisseurs comme Intel et AMD.

Ce nouveau CPU Arm vise à offrir plus de performances, un meilleur rendement énergétique et un coût au vCPU plus bas sur un large éventail de workloads à commencer par tous ceux engageant les bases de données et l’IA. Il embarque 192 cœurs ARM par puces et promet jusqu’à 25% de performance en plus par rapport à la génération précédente, avec une consommation maîtrisée, grâce notamment à une gravure en 3 nanomètres. Comme les précédentes générations, Graviton5 repose sur le système Nitro, cette couche matériel logiciel qui déporte la virtualisation, le réseau et le stockage sur du matériel dédié afin de laisser les cœurs CPU concentrés sur les workloads des clients.
Autre nouveauté de ce Graviton5, l’introduction du Nitro Isolation Engine est présentée comme une évolution majeure de la sécurité du cloud AWS. Cette brique exploite des techniques de vérification formelle pour démontrer mathématiquement que les workloads sont isolés les uns des autres, ainsi que des opérateurs AWS, via un code minimal formellement prouvé.
Trainium3 et Trainium4 arment le « frontier compute »
AWS a officiellement lancé son nouvel accélérateur Trainium3, présenté comme le premier accélérateur IA en 3 nm disponible dans un cloud public. Trainium3 vise explicitement l’entraînement des modèles « frontier » et les fine-tunings massifs. Cette puce marque un saut technologique majeur : elle offre jusqu’à 4,4 fois plus de puissance de calcul que la génération précédente, une bande passante mémoire presque quadruplée et une efficacité énergétique améliorée de 40 %. Concrètement, cela permet de réduire drastiquement les temps d’entraînement des modèles d’IA, passant de plusieurs mois à quelques semaines, tout en divisant les coûts pour certains clients de près de moitié. Avec une capacité d’interconnexion massive, Trainium3 peut être déployé à l’échelle de clusters réunissant jusqu’à un million de puces, ouvrant la voie à des projets multimodaux d’une ampleur inédite.

AWS les assemble au sein de « Trn3 UltraServers » où chaque serveur combine 144 puces Trainium3. Ces UltraServers sont conçus pour être déployés en UltraClusters de très grande taille, avec la promesse de clusters à l’échelle du million de puces pour les acteurs qui veulent entraîner leur propre modèle frontière.
Mais la surprise la plus étonnante, c’est qu’AWS ne présente désormais plus Trainium3 comme une puce dédiée à l’entraînement. Bien au contraire. La puce a même été présentée comme une plateforme d’inférence de nouvelle génération. Trainium3 est présenté comme l’accélérateur le plus rapide de Bedrock (la plateforme d’inférence et Model as a Service d’AWS), capable de délivrer jusqu’à 5 fois plus de tokens par mégawatt que le Trainium2 à latence équivalente. C’est ce point qu’AWS martèle : dans un monde où les agents IA vont générer des volumes massifs de tokens, l’enjeu business devient le coût marginal du token en production, pas seulement le coût d’entraînement initial. Trn3 est vendu comme la réponse maison à cette équation. Il est déjà massivement utilisé pour l’inférence par Anthropic, Karakuri, Metagenomi, NetoAI, Ricoh, Splash Music ou Decart. Il est aussi l’accélérateur par défaut des modèles Nova et de plus en plus de modèles ouverts hébergés sous Bedrock. Enfin, il est supporté en standard par Red Hat AI Inference Server, basé sur vLLM.
Tout aussi étonnant, et probablement pour enthousiasmer les investisseurs, mais aussi piquer la curiosité de ses clients, AWS a également fait du Teasing du prochain « Trainium4 » attendu l’an prochain. La future puce promet déjà d’offrir 6 fois plus de performance d’inférence en FP4, jusqu’à 3 fois plus de performances en FP8, quatre fois plus de bande passante mémoire avec une capacité HBM doublée par rapport à Trainium3. Plus étonnant, AWS promet l’intégration de NVLink Fusion pour interconnecter à très haut débit GPU Nvidia, Trainium4 et CPU Graviton au sein de racks vraiment hybrides !

Des UltraServers NVidia pour l’univers IA Cuda
Parallèlement, AWS n’abandonne évidemment pas NVIDIA. L’hyperscaler avait déjà été l’un des premiers à mettre en œuvre la plateforme GB200 NVL72. À re:Invent 2025, AWS a officiellement lancé ses nouvelles instances « P6e-GB300 UltraServers », basés sur la plateforme NVIDIA GB300 NVL72 (à base de superchips combinant CPU Grâce et GPU Blackwell), ciblent les charges d’inférence à très grande échelle, typiquement des modèles de plusieurs centaines de milliards de paramètres et des agents de raisonnement, en production.
Parallèlement, les nouvelles instances « P6 » (sans le « e ») combinent plus raisonnablement des GPU Nvidia B200 ou B300 avec des Intel Xeon au sein de configurations plus classiques (HGX-B200/B300), mais promettent de doubler la performance par rapport aux instances P5en.

Par ailleurs, les puces Nvidia sont mises en avant comme la brique GPU phare des nouvelles AWS AI Factories…
AI Factories : le cloud AI d’AWS en « on-prem »
La nouveauté la plus stratégique de ce re:Invent 2025 pour les secteurs critiques restera sans doute l’annonce des AWS AI Factories. Amazon propose de déployer chez ses clients les plus fortunés des « mini-régions privées » AWS dédiées à l’IA. Ces usines combinent Trainium3, GPU NVIDIA, réseau basse latence, stockage haute perf et services managés, comme Bedrock et SageMaker AI, le tout opéré par AWS dans le datacenter de l’entreprise ou de l’administration. AWS prend en charge design, intégration et exploitation, tandis que les organisations fournissent espace et énergie. Objectif : offrir une capacité d’entraînement et d’inférence de niveau cloud public, mais sur site, en accélérant les projets de plusieurs mois ou années et en répondant aux exigences de conformité sectorielle et de contrôle de la donnée des secteurs critiques. Bien évidemment, le terme « souveraineté » est également largement employé. Mais si l’offre répond clairement aux attentes d’« on-prem hyperscale » pour l’IA (garder la donnée dans ses murs, limiter la latence, montrer aux régulateurs que l’empreinte est localisée), le régime juridique applicable en cas d’extraterritorialité du droit américain (Cloud Act) n’est pas magiquement effacé par le fait que les racks AWS sont chez le client.

Pour l’instant, AI Factories ressemble surtout à une réponse musclée aux offres « AI factories » d’Oracle ou même d’OVHcloud, plus qu’à une solution prête à cocher toutes les cases du Cloud de Confiance à la Française.
SageMaker HyperPod : une brique méconnue qui muscle l’entraînement
Amazon SageMaker HyperPod est la brique AWS pour entraîner des modèles géants sur des grappes de milliers de GPU ou de puces Trainium sans gérer soi-même l’infra. Cette infrastructure permet selon AWS de réduire les coûts d’entraînement et de déploiement jusqu’à 40% par rapport à une infrastructure assemblée soi-même. À re:Invent 2025, AWS y ajoute deux capacités clés :
– le checkpointless training, qui permet de récupérer un entraînement après un plantage sans redémarrer le job ni recharger de gros checkpoints, en maintenant jusqu’à 95 % de rendement effectif sur des milliers d’accélérateurs. C’est important car l’entraînement de modèles de centaines de milliards de paramètres répartis sur des milliers de machines souffre toujours de pannes matérielles et bugs logiciels qui font planter l’entraînement. Pour éviter de tout recommencer, on sauvegarde régulièrement l’état du modèle (checkpointing), mais cela prend des heures et immobilise des clusters ultra-coûteux. Ici, le « checkpointless training » préserve en continu l’état du modèle sur l’ensemble du cluster. En cas de défaillance le remplacement des machines défectueuses et la restauration de l’entraînement ne prend que quelques minutes…
– l’elastic training, qui ajuste automatiquement la taille du cluster en fonction des ressources disponibles.

Véritable cluster IA managé au sein de SageMaker, HyperPod s’intègre avec EKS, NeMo et les recettes prêtes à l’emploi pour Llama et GPT-OSS, ce qui en fait un outil central pour industrialiser le training de LLM et d’agents maison à grande échelle.
EKS : Kubernetes comme tissu d’ultra-scale IA
En dessous de Bedrock, AWS positionne clairement Amazon EKS comme le tissu d’orchestration des workloads IA d’ultra grande taille. EKS supporte désormais jusqu’à 100 000 nœuds par cluster, soit jusqu’à 1,6 million de puces Trainium ou 800 000 GPU NVIDIA dans un seul cluster Kubernetes, ce qui tombe à pic pour les formations de modèles de type Nova ou Claude 4.5.
Le message de re:Invent 2025, c’est que les grands entraînements et les grandes fermes d’inférence doivent être vus comme des workloads Kubernetes « comme les autres », mais dopés aux GPU/Trainium et aux CNI haut débit. EKS Auto Mode automatise le provisioning de nœuds spécialisés (P6, Trn3, G6…), la gestion du réseau, du stockage et des versions de kube, pendant que SageMaker HyperPod, Bedrock et EMR (la plateforme big data managée d’AWS) s’adossent de plus en plus à EKS pour orchestrer leurs jobs. L’enjeu pour les DSI ? Ne plus opposer plateforme IA et plateforme Kubernetes, et assumer qu’à très grande échelle, l’IA se gère via les mêmes abstractions, observabilité et contrôles RBAC que le reste du SI, en tirant parti d’un EKS très intégré à l’écosystème AWS.
Une once de quantique…
Avec moins de fanfare que l’an dernier, AWS a aussi rappelé qu’elle voyait dans l’informatique quantique l’une des pistes les plus prometteuses des infrastructures IA de demain. L’hyperscaler continue d’explorer le potentiel de son premier chip quantique maison : Ocelot. Basé sur des cat qubits supraconducteurs, il promet de réduire de près de 90 % le coût de la correction d’erreurs, véritable talon d’Achille du quantique, et devrait arriver sur Amazon Braket (le services QaaS d’AWS) même si l’hyperscaler se refuse encore à avancer la moindre date. L’annonce n’a pas d’impact immédiat sur les projets IA des entreprises, mais elle confirme qu’AWS continue d’investir sur le long terme dans les technologies post-Moore. Pour l’instant, c’est surtout un signal « on est là » adressé aux communautés recherche quantique… et à Alice & Bob, la deeptech française pionnière des qubits de Chat.

Des modèles à personnaliser et des plateformes d’inférence
Une fois le socle de calcul posé – Trainium3, GPU NVIDIA, AI Factories on-prem, EKS et HyperPod pour orchestrer le tout – la question devient : que va-t-on réellement faire tourner sur cette machinerie ultra-scale ? La réponse tient en un mot : les modèles.
Les LLM et modèles multimodaux sont le moteur de l’IA agentique. C’est là qu’AWS avait le plus de retard à rattraper. Il lui a fallu deux ans. Mais avec sa plateforme « Model as a Service » Bedrock devenue ultra populaire et l’introduction de ses propres modèles « Nova » aux tarifs très attractifs, l’hyperscaler a refait son retard et su faire revenir ses clients partis voir ailleurs dans leurs quêtes de capacités IA pour satisfaire leurs besoins métiers. AWS avance désormais crânement ses pions en affirmant que m’enjeu n’est plus seulement de proposer « un bon modèle », mais de permettre à chaque DSI de choisir le bon moteur pour chaque cas d’usage, de le customiser finement et de l’exposer via des plateformes d’inférence maîtrisées en coût, en latence et en gouvernance. Et de customisation, il en a beaucoup été question…
La famille Nova 2 : quatre profils pour couvrir les cas d’usage
L’arrivée de la famille de modèles maison d’AWS, Nova, avait été l’annonce phare du « re:Invent » de 2024. Un an plus tard, l’hyperscaler veut montrer qu’il sait aussi faire évoluer ses modèles avec les mêmes bonds de progression que les Gemini ou Claude.
Grosse attraction de cette édition 2025, la nouvelle famille Nova 2 comporte déjà quatre nouveaux modèles clairement pensés pour l’entreprise et les cas d’usage métier.
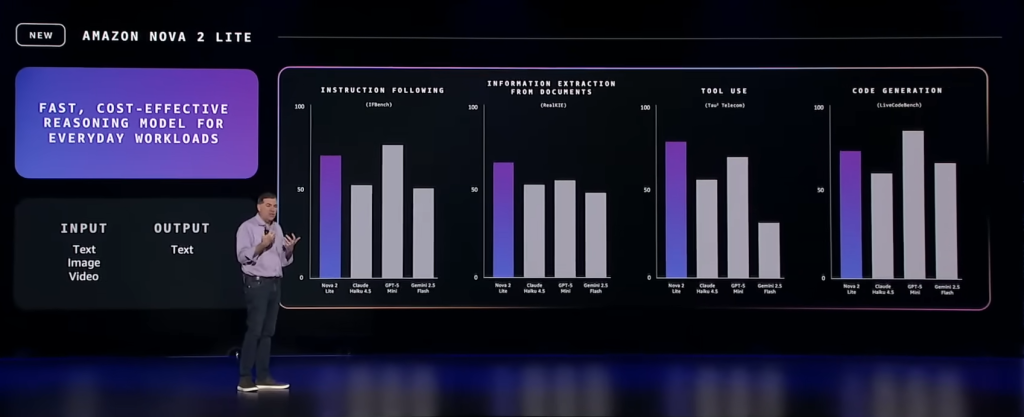
Nova 2 Lite se veut le modèle de raisonnement le plus rapide et le plus économique, pensé pour les tâches IA quotidiennes et optimisé « réduction des coûts » pour les tâches conversationnelles et les agents orientés productivité. Il surpasse Claude Haiku 4.5, GPT-5 mini et Gemini Flash 2.5 dans la plupart des tests. AWS y voit le modèle idéal pour démocratiser l’IA dans les scénarios métiers des entreprises.
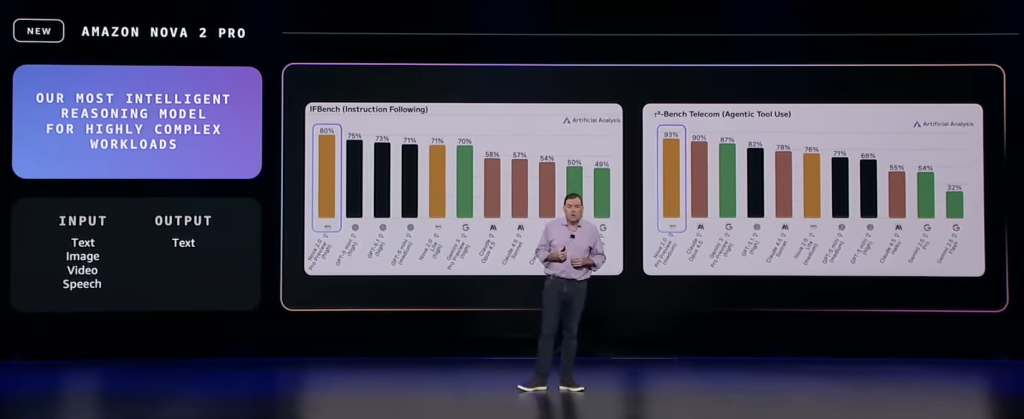
Nova 2 Pro est le nouveau modèle frontière d’AWS, positionné sur la haute performance en raisonnement, en code et sur les principaux benchmarks académiques. AWS le présente comme un modèle compétitif face aux meilleurs modèles propriétaires du marché, à utiliser dès que la qualité prime sur le coût.
Nova 2 Omni est le premier vrai modèle multimodal (texte, image, audio, vidéo) d’AWS, conçu pour les agents qui doivent analyser des documents, des interfaces, des images ou des flux vidéo. C’est le pendant, côté AWS, de Gemini 3.0 ou de GPT-5.
Nova 2 Sonic est le modèle orienté voix, speech-to-speech, faible latence, pour les assistants vocaux et les interactions téléphoniques.
Les DSI doivent surtout retenir qu’AWS décline sa famille Nova par profil de latence/coût/capacité, de façon assez similaire à Microsoft (Phi/Semantic Kernel + GPT-5.x) ou Google (Gemini Nano/Pro/Ultra), mais en les liant très fortement à l’infrastructure maison Trainium/HyperPod et aux services d’agents que nous évoquerons plus loin.
Bedrock se transforme en hub de modèles open-weight
L’autre mouvement important, moins visible, mais structurant, est l’enrichissement de Bedrock en modèles open-weight. AWS a annoncé 18 nouveaux modèles open source ou open-weight – pour le langage, le code, l’image, les agents – exposés via Bedrock et déployables en VPC, avec des garanties de gouvernance et d’isolement des données. Et parmi ces nouveaux modèles, AWS a officialisé l’arrivée de la nouvelle génération de modèles de Mistral, sous licence Apache 2.0 : le modèle frontière Mistral Large 3 et les modèles « Edge » Ministral 3 en version 3B, 8B et 14B.
Pour un DSI, c’est une manière de profiter du dynamisme de l’écosystème open source (Mistral, LLaMA, etc.) sans avoir à gérer la complexité d’un déploiement bare-metal ou Kubernetes maison : Bedrock se charge du provisioning, de l’auto-scaling, de l’observabilité et des contrôles d’accès.

Bedrock ne se limite pas à un service de type « Model-as-a-Service » ou à une simple place de marché de modèles. La plateforme se positionne comme un hub de modèles et de services associés, avec des contrôles de sécurité, des garde-fous, de la gouvernance, du monitoring et des fonctions avancées comme le RAG, l’orchestration d’agents, l’intégration aux services AWS. Il permet même du fine-tuning ou de l’adaptation sur les données du client. Et en la matière, AWS enclenche la vitesse supérieure.
Model customization : Bedrock et SageMaker AI montent en gamme
Car AWS a beaucoup insisté cette année sur la personnalisation des modèles. Une telle personnalisation est la clé d’une IA d’entreprise ancrée sur le patrimoine informationnel et le jargon des métiers ainsi qu’un moyen de limiter l’apparition d’hallucinations dans les cas d’usage métiers. Désormais, Bedrock et SageMaker AI cherchent à rendre la personnalisation de modèles aussi simple et industrialisable que possible, là où le fine-tuning restait jusqu’ici un chantier long, cher et réservé aux spécialistes IA.
Côté Bedrock, les nouveautés sont nombreuses. Des pipelines de customisation plus intégrés (RAG, fine-tuning, distillation, quantization) deviennent pilotables via une expérience unifiée. AWS introduit surtout un « Reinforcement Fine Tuning » (RFT) sous forme de service managé. Le principe : le développeur choisit un modèle de base (par exemple Nova 2 Lite), branche ses logs d’invocation ou un jeu de données métier, définit une fonction de “récompense” (règles, modèle IA ou gabarit prêt à l’emploi), et Bedrock prend en charge toute la chaîne de fine-tuning. Plus besoin de construire des pipelines RL complexes ni de gérer l’infrastructure : AWS orchestre entraînement, évaluation et déploiement, avec à la clé des gains moyens annoncés de l’ordre de 66 % en précision par rapport au modèle de base, tout en permettant d’utiliser des modèles plus petits et donc moins coûteux.

SageMaker AI pousse la logique un cran plus loin pour les équipes qui veulent garder la main. AWS propose un fine-tuning serverless, avec deux modes : une expérience « agentique » où un agent guide le développeur en langage naturel à travers la génération de données synthétiques, le choix de la technique de customisation et l’évaluation, mais également une expérience « auto-pilotée » pour ceux qui veulent régler eux-mêmes les paramètres. Dans les deux cas, l’infrastructure est abstraite, les workflows sont unifiés et les cycles de customisation passent de plusieurs mois à quelques jours, ce qui permet enfin d’industrialiser le fine-tuning à l’échelle des portefeuilles d’applications et d’agents IA de l’entreprise. Couplé à HyperPod, cela permet aux équipes data/ML de lancer des campagnes de fine-tuning sans se transformer en équipe d’ordonnancement de clusters.
Globalement, AWS rattrape son retard sur la notion de « model lifecycle management » face à Azure AI Studio et Google Vertex AI, en misant sur Bedrock comme point d’entrée unifié et en gardant SageMaker comme plateforme avancée pour les équipes ML les plus matures.
Nova Forge : un étage au-dessus du simple fine-tuning
C’est l’une des très grosses surprises de ce re:Invent 2025 et l’un des rares services IA d’AWS qui n’a encore aucun équivalent chez la concurrence, même si l’hyperscaler vise ici un segment de marché restreint. Là où Bedrock permet de consommer ou de fine-tuner des LLM, Nova Forge vise les organisations qui veulent forger leur propre modèle frontière à partir de Nova 2.
Concrètement, le service donne accès à des checkpoints Nova (pré-, mid- ou post-training) et permet de les poursuivre en co-entraînant le modèle avec des données métiers, sur l’infrastructure SageMaker AI/HyperPod. On ne se contente plus ici d’ajuster la dernière couche : on ré-ouvre le cycle d’entraînement pour injecter du métier tôt dans la vie du modèle. Les variantes produites, appelées « Novellas » par AWS, conservent les capacités générales de Nova (raisonnement, follow instructions, multimodalité selon la base choisie), mais deviennent fortement spécialisées sur un secteur, un corpus ou un contexte réglementaire. AWS ajoute à cela un toolkit de RFT (Reinforcement Fine Tuning) et de garde-fous responsables pour aligner le comportement de votre propre modèle frontière nouvellement créé sur des métriques internes, des simulateurs ou des règles métier.
Ticket d’entrée élevé, ancrage fort dans l’écosystème AWS/Bedrock et dépendance à l’architecture Nova : Nova Forge s’adresse clairement aux DSI qui envisagent le modèle comme un actif stratégique différenciant, pas comme une commodité, et qui acceptent un niveau de lock-in plus fort en échange d’une « forge industrielle » pour co-construire leur propre LLM de classe frontier.
C’est une réponse directe aux offres de type « model foundry » de Google (AI HyperComputer) ou de Microsoft (Azure Foundry), mais avec une accessibilité bien supérieure et une simplicité de mise en œuvre sans comparaison. On est très curieux de voir les premiers cas d’usage de cette nouvelle offre.
Les données pour l’IA
Personnaliser les modèles et optimiser les plateformes d’inférence ne suffit pas : sans données fiables, fraîches, bien gouvernées, les meilleurs LLM restent des moteurs au ralenti. La vraie performance des agents IA se joue désormais dans la façon dont l’entreprise structure, expose et protège ses données, qu’elles servent à entraîner des modèles maison, à nourrir des RAG métiers ou à alimenter des mémoires d’agents.
C’est précisément sur ce terrain qu’AWS a fait feu de tout bois à re:Invent 2025, en transformant S3, EMR, Clean Rooms et même IAM en véritable socle data pour l’IA, capable de servir à la fois de lac, de vecteur store, de fabrique de jeux d’entraînement et de zone de confiance pour les collaborations sensibles.
S3 devient une plateforme vectorielle et analytique de premier plan
L’IA agentique a besoin de mémoire et de contexte. AWS transforme son S3, le « disque dur d’Internet » et standard de fait du stockage objet, en cerveau vectoriel.
Avec S3 Vectors, les index d’embeddings vivent désormais directement dans S3. Plus besoin de base de données vectorielle séparée pour les cas simples. S3 intègre désormais l’indexation vectorielle nativement. Vous déposez un fichier, il est instantanément « RAG-ready ». Désormais disponible dans 14 régions et capable de stocker jusqu’à 2 milliards de vecteurs par index et jusqu’à 20 000 milliards de vecteurs par bucket, le service annonce des économies de coûts pouvant aller jusqu’à 90 % par rapport à des bases vectorielles spécialisées. La mémoire des agents (embeddings, historiques, features) peut désormais vivre directement dans S3, sans multiplier les technos.

Dans le même mouvement, AWS pousse S3 au cœur du data plane analytique : les objets peuvent désormais monter jusqu’à 50 To, de quoi absorber datasets d’entraînement, vidéos et logs massifs sans sharding.
Parallèlement les S3 Tables gagnent un stockage Intelligent-Tiering et des capacités de réplication automatique (Iceberg) qui rapproche un peu plus S3 d’un data lakehouse exploitable pour les workloads analytiques à grande échelle.
Enfin, l’intégration renforcée avec FSx for NetApp ONTAP – désormais adressable via S3 – facilite le pont entre stockage fichier d’entreprise et stockage objet pour l’IA, ce qui parlera aux DSI ayant déjà standardisé leurs NAS sur NetApp.
EMR Serverless : Spark sans stockage local à gérer
Côté data processing, Amazon EMR Serverless élimine désormais la nécessité de provisionner du stockage local pour les jobs Spark. Le service prend en charge automatiquement le shuffle et la gestion des données intermédiaires, ce qui, selon Amazon, permet de réduire les coûts de traitement jusqu’à 20 % et de limiter les échecs de jobs liés aux volumes de données intermédiaires.
Dit autrement, EMR Serverless se rapproche du modèle économique et opérationnel du serverless pur pour les pipelines big data, ce qui ravira les équipes qui alimentent les features stores, les jeux d’entraînement et les pipelines de préparation de données pour l’IA.
AWS Clean Rooms : collaborer sur des données sensibles
AWS Clean Rooms franchit un nouveau cap avec la génération de jeux de données synthétiques respectant les comportements statistiques des données originales tout en préservant la confidentialité. Les entreprises peuvent ainsi entraîner des modèles sur des données collaboratives sensibles (partenaires, écosystèmes) tout en limitant les risques de ré-identification. Pour des secteurs comme la banque, la santé, la distribution ou les télécoms, cette capacité de « privacy by design » est un élément clé pour concilier AI Factories, projets d’agents, AI Act et NIS2.
MCP Server et IAM Policy Autopilot : gouverner l’accès via les agents eux-mêmes
Positionné à la frontière entre data, sécurité et outillage développeurs, IAM Policy Autopilot est un nouveau serveur MCP (Model Context Protocol) open source qui analyse le code d’une application pour générer les politiques IAM nécessaires, et propose des corrections ciblées en cas d’erreurs d’autorisations. C’est une brique intéressante dans un monde où les agents et assistants de développement produisent massivement du code qui touche des ressources cloud : au lieu de laisser les équipes extrapoler des politiques trop permissives, un agent dédié s’appuie sur CloudTrail, les SDK et la connaissance des services AWS pour proposer des politiques de départ raisonnablement bornées.
Plus largement, AWS pousse un écosystème de MCP servers pour documenter, décrire et gouverner l’accès aux ressources (docs, infra, IAM, etc.) par les agents, dans lequel Bedrock AgentCore (cf plus loin) joue le rôle de runtime.
Les outils de création d’applications IA et d’agents IA
Mettre de l’ordre dans les données et doter les modèles d’un cerveau vectoriel ne suffit pas : encore faut-il transformer ce capital en applications et en agents qui rendent des services concrets aux équipes métiers, aux développeurs et aux Ops. C’est là qu’AWS change de registre et tente de gagner le cœur des développeurs IA. Avec une nouvelle arme de prédilection, Kiro !
Au-dessus de son socle de compute, de ses modèles Nova et de son data plane S3, l’hyperscaler déroule une panoplie d’outils pour « empaqueter » l’IA : agents développeurs avec Kiro, assistants de productivité et d’analyse avec Quick Suite, agents de modernisation applicative avec AWS Transform, SDK Strands pour industrialiser la construction d’agents sur mesure. En clair, on passe de l’IA comme infrastructure à l’IA comme main-d’œuvre logicielle intégrée aux pipelines Dev, aux projets de migration et aux workflows métiers.
Amazon Kiro : un « développeur virtuel » très AWS-centric
Présenté en mai 2025 et officiellement lancé en juillet 2025, Kiro est l’environnement de développement intégré (EDI) basé sur l’IA agentique d’AWS, conçu pour transformer la manière dont les développeurs écrivent du code en générant automatiquement des programmes robustes et maintenables à partir de spécifications ou d’instructions en langage naturel. Dit autrement, Kiro est un environnement de dev piloté par l’IA, centré sur le « spec-driven development » : le développeur formalise ses intentions dans des specs exécutables, Kiro construit le contexte (code, docs, tickets) et orchestre des agents qui produisent le code correspondant.
À re:Invent 2025, AWS y a ajouté deux briques clés :
* Kiro Autonomous Agent (KAA), l’un des trois « frontier agents » lancé par AWS (voir plus loin), est présenté comme un développeur virtuel de niveau mid-senior qui travaille en tâche de fond pendant des heures ou des jours. Il maintient un contexte persistant sur plusieurs sessions, lit specs, ADR, tickets et dépôts Git, conçoit des changements, écrit et refactore le code, ajoute des tests, ouvre des pull requests et coordonne des modifications multi-repos. Il se branche directement sur GitHub, Jira, Slack et les pipelines CI/CD pour suivre l’avancement et adapter son travail, tout en laissant aux équipes la main sur ce qui est fusionné.
Dit autrement, on peut voir KAA comme un « Virtual Developer » autonome capable de prendre une issue Jira, de naviguer dans le code, de proposer un fix et de lancer les tests. De quoi gagner un temps fou !

* Les Kiro Powers donnent aux agents Kiro une expertise instantanée sur les outils de l’écosystème dev/ops. Un « power » combine des serveurs MCP pour accéder à des outils spécialisés, des fichiers de steering encapsulant les bonnes pratiques et des hooks pour déclencher des actions dans des workflows précis, du design à la prod. AWS fournit déjà des « powers » prêts à l’emploi pour Datadog, Dynatrace, Figma, Neon, Netlify, Postman, Stripe, Supabase et ses propres services, avec la possibilité pour les équipes de créer et partager leurs propres powers. Au lieu d’un agent générique qui « bricole » des appels d’API, avec ses Powers Kiro s’équipe de capacités verticales riches, activées à la demande pour limiter la consommation de tokens et augmenter la précision.
Pour un DSI, Kiro n’est donc pas seulement un concurrent de GitHub Copilot : c’est une plateforme de développement orientée specs et agents, avec un frontier agent autonome branché sur le cycle de vie logiciel complet, et un système d’extensions (powers) qui permet d’injecter dans l’agent l’expertise outillée de toute la chaîne Dev, Sec et Ops.
Amazon Quick Suite : l’IA de productivité à la sauce AWS
Amazon Quick est un peu aux collaborateurs de l’entreprise ce que Kiro est aux développeurs. AWS se positionne ici sur le terrain des suites de productivité augmentées à l’IA avec une approche originale.
Avec Amazon Quick Suite, AWS ne se contente pas d’un énième chatbot de bureau : il propose un véritable espace de travail agentique. Quick Suite regroupe dans une même interface des « teammates » IA capables de chercher de l’information dans l’ensemble du SI (S3, Redshift, data warehouses, SaaS, wikis…), de l’analyser, de la visualiser et surtout de déclencher des actions dans les applications métiers, en s’appuyant sur Amazon Q Business et l’écosystème MCP pour se connecter à des centaines d’outils tiers.
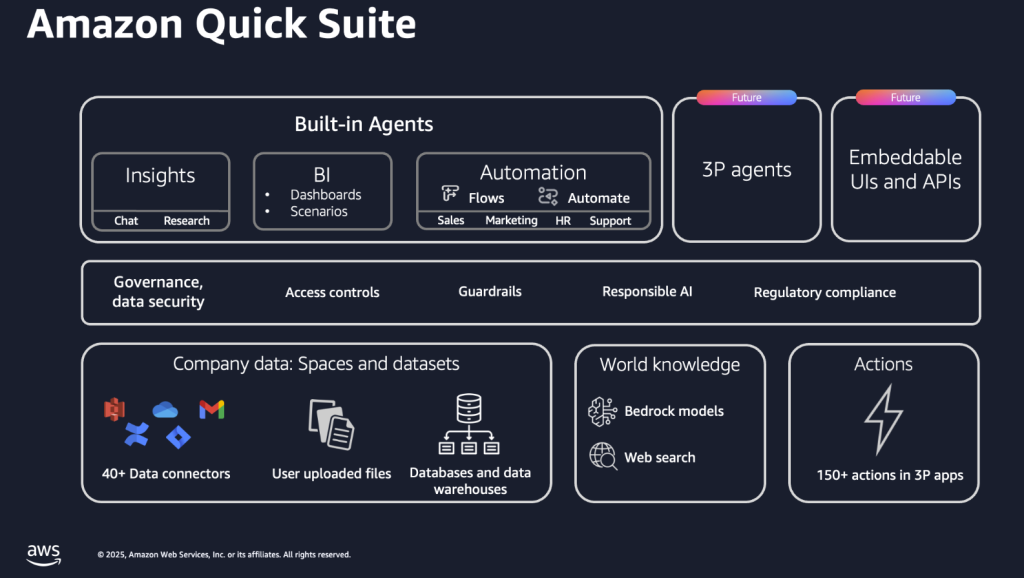
Sous le capot, Quick Suite assemble plusieurs briques : QuickSight pour la BI et les dashboards, Quick Research pour la recherche et l’analyse approfondies de documents, Quick Index pour l’indexation et la découverte de données, Quick Flows et Quick Automate pour l’orchestration et l’automatisation de workflows complexes. L’ensemble est accessible depuis une web app, des extensions de navigateur, Slack ou les applications Microsoft 365, et applique finement les permissions existantes via IAM Identity Center, de sorte que les réponses et les automatismes respectent les droits d’accès des utilisateurs.
Quick Suite se positionne moins comme un concurrent frontal d’Office ou de Workspace que comme une surcouche IA unifiée au-dessus des données et outils déjà présents dans l’écosystème AWS. Son intérêt principal : transformer les projets d’IA générative, souvent traités comme des POC isolés, en un environnement de travail continu où les agents exploitent directement les lacs S3, les modèles Bedrock et les connecteurs SaaS pour produire des synthèses, piloter des analyses, automatiser des processus et faire circuler l’information sans multiplier les applications ni les intégrations maison.
Modernisation et migration : AWS Transform et ses agents applicatifs
Dans le prolongement de Kiro et d’Amazon Quick Suite, AWS applique la même logique d’agents spécialisés à un autre chantier critique : la modernisation de masse et l’éradication de la dette technique. Et l’hyperscaler a un outil agentique pour cela : AWS Transform.
Lancé plus tôt cette année, AWS Transform se présente comme le premier service d’IA agentique dédié à la modernisation de stacks complètes Windows, mainframe et VMware, désormais étendu à « tout code, toute appli, tout runtime », y compris des langages propriétaires. Les agents automatisent découverte, analyse, refactoring, génération de plans, exécution et tests, avec des gains annoncés pouvant aller jusqu’à ×5 sur la vitesse de modernisation et jusqu’à 70 % de réduction des coûts de maintenance et de licences. AWS affirme avoir déjà analysé plus de 1,1 milliard de lignes de code et économisé plus de 810 000 heures de travail manuel grâce à Transform.
Le volet Full Stack Windows Modernization illustre bien cette approche. L’agent scanne les bases SQL Server (sur EC2 ou RDS) et le code .NET dans les dépôts Git pour produire un plan de modernisation éditable, puis transforme de manière coordonnée l’application, les frameworks UI, la base de données (migration vers Aurora PostgreSQL avec conversion intelligente des procédures stockées) et les configurations de déploiement. AWS revendique des projets jusqu’à cinq fois plus rapides et une forte baisse des coûts de licences Microsoft.
Côté mainframe, Transform avait été lancé au printemps comme premier service d’IA agentique pour ce périmètre. À re:Invent, AWS ajoute des capacités dites de « Reimagine » et de tests automatisés : agents d’analyse d’activité pour décider quoi moderniser ou retirer, extraction de règles métier et de flux fonctionnels cachés dans le code, génération automatique de plans et de jeux de tests. De quoi faire passer certains programmes de modernisation de plusieurs années à quelques mois.
Sur le front VMware, Transform est désormais GA avec des workflows d’IA agentique capables d’inventorier des milliers de VM, de cartographier les dépendances, de convertir les règles réseau, de proposer des vagues de migration et d’optimiser les tailles d’instances EC2 cibles, là où ces tâches prenaient auparavant des semaines de travail manuel.

Mais la grande nouveauté de ce re:Invent reste Transform Custom. Amazon s’est rendu compte qu’il lui serait impossible de sortir un module pour chaque langage, framework et autres plateformes héritées. Il fallait une autre approche et permettre à chaque entreprise de composer son agent de modernisation. Transform Custom permet d’industrialiser la modernisation de code spécifique à chaque organisation : langages internes, frameworks maison, versions exotiques de runtime. Il combine des transformations packagées (upgrades Java, Node.js, Python, changements de runtime) et des règles sur mesure définies par l’entreprise.
Pour un DSI, Transform ressemble de plus en plus à un bureau d’études IA pour la modernisation : une batterie d’agents de domaine qui encapsulent 19 ans d’expertise migration AWS et transforment un chantier lourd et peu valorisant – la dette technique – en un pipeline industriel, au prix, évidemment, d’un ancrage fort dans l’écosystème AWS.
Strands Agents SDK : un SDK agentique multi-langage
Reste un dernier point : comment aller plus loin et permettre aux organisations de créer leurs propres agents IA métiers ? Dans l’écosystème AWS, la réponse s’appelle « Strands Agents SDK ». Strands joue le rôle de framework open source « maison » pour les agents, en parallèle des stacks propriétaires type LangGraph, Semantic Kernel ou des runtimes managés comme Bedrock AgentCore. Lancé au printemps 2025 en Python, il s’est rapidement imposé comme une alternative très intégrée à AWS, mais suffisamment ouverte pour rivaliser avec LangChain, CrewAI ou d’autres frameworks d’agents multi-LLM.
Strands Agents adopte une approche « model-driven » : l’agent est défini comme une boucle de raisonnement (planifier, choisir des outils, exécuter, évaluer) gérée par le modèle lui-même, plutôt que par des workflows orchestrés à la main. Le SDK fournit des primitives pour composer des agents, brancher des outils, piloter des LLM (Bedrock, Claude, OpenAI, Ollama, etc.), gérer le contexte et les sessions, avec un accent fort sur la production (observabilité, sécurité, intégration AWS). De nombreuses équipes internes l’utilisent déjà (Amazon Q Developer, Glue, VPC Reachability Analyzer).
À re:Invent 2025, AWS a franchi une étape en annonçant le support TypeScript en preview. Jusqu’ici, seuls les développeurs Python bénéficiaient de Strands ; désormais, l’écosystème Node.js peut bâtir des agents avec le même modèle conceptuel, en profitant de la sécurité de typage, des patterns async modernes et d’une intégration naturelle avec les apps front et les backends JS. Le repo sdk-typescript reprend les notions clés du SDK Python (agents, tools, SOP, steering) en les adaptant à l’univers TypeScript.

Strands s’accompagne d’un ensemble de composants satellites :
– des tools prêts à l’emploi, qui encapsulent des capacités avancées (web search, appels à des APIs AWS, manipulations de données) ;
– un dépôt agent-sop, qui formalise des Standard Operating Procedures en langage naturel structuré (MUST/SHOULD…) pour guider les agents et rendre leur comportement plus prévisible et débogable ;
– un module evals, pour évaluer systématiquement les agents selon différents scénarios et métriques ;
– un Agent Builder en ligne de commande pour créer, tester et étendre des agents et des outils.
Par rapport à la concurrence, Strands se distingue par son double ancrage : très natif AWS (intégration avec Bedrock, AgentCore, observabilité, IAM) tout en restant officiellement ouvert et multi-cloud via son support de modèles tiers et de déploiements variés (local, edge, Kubernetes, Lambda). C’est, en pratique, le pendant open source du couple Bedrock/AgentCore : les DSI et équipes dev peuvent garder la main sur leur framework d’agents, tout en s’alignant sur les bonnes pratiques et les briques de gouvernance qu’AWS pousse pour l’IA agentique en production.
Mettre l’IA et les agents IA en action
L’infrastructure est opérationnelle, les données sont là, les modèles sont customisés, les agents sont créés… Reste la dernière question essentielle : comment faire travailler ces agents, en vrai, sur des processus critiques, de manière fiable et gouvernée ?
C’est précisément l’objet du dernier étage de la fusée d’annonces de ce re:Invent 2025. AWS a démontré comment ses Frontier Agents, sa plateforme d’automatisation Nova Act, sa méta brique agentique Bedrock AgentCore et tout un socle de sécurité adapté (GuardDuty, Security Hub, CloudWatch) transforment les concepts en exécutions concrètes : agents développeurs, agents sécurité, agents DevOps, agents de navigateur… branchés sur les systèmes existants, observables, bornés par des politiques et déjà testés chez des clients comme Blue Origin ou Sony. AWS démontre que l’on peut, en cette fin d’année 2025, vraiment envisager de quitter la phase d’expérimentation pour entrer dans celle où les agents prennent en charge une partie de vos processus métiers.
Nova Act : une nouvelle plateforme d’automatisation
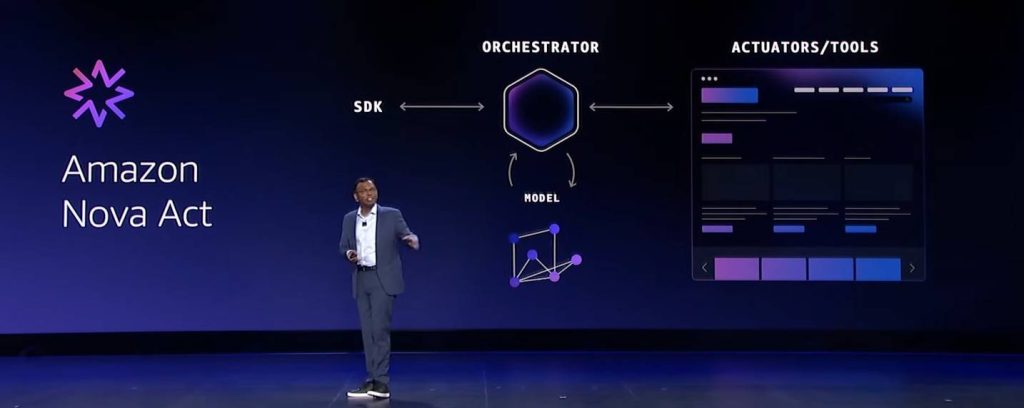
Nova Act est la nouvelle brique AWS dédiée au « computer use » en production. Bien plus qu’un simple agent, il s’agit là d’un véritable service managé pour bâtir et opérer des flottes d’agents qui pilotent des navigateurs, automatisent des workflows web critiques et atteignent plus de 90 % de réussite promet AWS. Propulsé par un modèle Nova 2 Lite spécialisé, entraîné par renforcement dans des « web gyms » qui simulent des milliers d’interfaces, il verticalise modèle, orchestrateur, outils et SDK pour maximiser la fiabilité, là où beaucoup de modes « computer use » concurrents restent au stade de la démo.
Pour les développeurs, Nova Act propose un trajet simple : playground web pour prototyper en langage naturel, workflows décrits en mixant texte et Python, extension d’IDE pour déboguer, déploiement puis supervision dans la console AWS. Les agents enchaînent tests de régression UI, saisies et extractions de données, parcours de checkout ou mises à jour de CRM, avec possibilité d’appeler des APIs, des outils via MCP et d’escalader à l’humain sans casser le flot. Le service s’intègre à Strands Agents pour les scénarios multi-agents, à Bedrock AgentCore pour le runtime, à CloudWatch pour l’observabilité, à IAM pour les permissions et à 1Password pour la gestion sécurisée des identifiants.
Et AWS de citer les premiers cas d’usage de ses clients : Hertz automatise ses tests de réservation web et dit avoir multiplié par cinq sa vélocité de déploiement en passant de semaines à quelques heures de création de cas de test ; Amazon Leo (internet par satellite) et Project Kuiper l’utilisent pour l’automatisation QA de plateformes critiques ; 1Password s’en sert pour simplifier les logins web de ses utilisateurs. Nova Act vise clairement à faire passer l’automatisation UI du statut de RPA fragile à celui de charge agentique de premier plan, alignée sur les mêmes standards de fiabilité, de sécurité et d’observabilité que le reste du SI.
Les Frontier Agents
Au-delà de ces automatisations agentiques, AWS entrevoit déjà une nouvelle catégorie de « supers agents IA ». Concrètement, quand AWS parle de « Frontier Agents », il ne désigne pas un copilot agentique de plus, mais une nouvelle classe de supers agents IA qui travaillent comme de vrais membres d’équipe. Ce sont des systèmes très autonomes, capables de prendre un objectif (« réduire le temps de résolution des incidents », « durcir la sécurité de telle appli », « implémenter telle feature »), de planifier, d’appeler des outils, de coordonner d’autres agents IA et d’exécuter le travail pendant des heures, voire des jours, sans repasser en boucle devant l’utilisateur. Ils s’appuient sur Bedrock AgentCore (mémoire longue durée, gestion d’outils, identité, observabilité) et sont conçus pour fonctionner à grande échelle sur des dizaines d’applications et d’équipes simultanément. Matt Garman, le CEO d’AWS, n’hésite pas à affirmer que ces agents auront, pour l’entreprise, un impact du même ordre que l’Internet ou le cloud.
Et pour AWS, ces agents ne sont pas futuristes. Ils sont déjà là. L’hyperscaler dégaine ainsi une première vague de « Frontier Agents ». AWS limite pour l’instant le champ aux fondamentaux du cycle de vie logiciel avec ses trois premiers Frontier Agents : un « développeur virtuel » (Kiro autonomous agent), un « ingénieur sécurité virtuel » (AWS Security Agent) et un « SRE/DevOps virtuel » (AWS DevOps Agent). Avec eux, AWS ambitionne de faire passer l’IA, dans le développement applicatif, du rôle d’assistant conversationnel à celui de collègue autonome qui délivre un résultat complet.

* Nous avons déjà évoqué plus haut Kiro Autonomous Agent, le Frontier Agent dédié au développement. Là où Kiro « classique » joue le rôle d’IDE et de CLI augmentés à base d’agents, Kiro autonomous agent devient un développeur virtuel à qui l’on assigne des tâches de backlog plutôt que des prompts.
* AWS Security Agent occupe le rôle de spécialiste AppSec. C’est un Frontier Agent pensé pour sécuriser les applications « de la maquette à la prod » en combinant trois capacités : revue de conception, revue de code continue et pentest à la demande. Les équipes sécurité définissent une fois leurs exigences (libraries autorisées, politiques de logs, contraintes de chiffrement, règles de conformité), que l’agent applique ensuite automatiquement en analysant documents d’architecture et pull requests. Il commente le code directement dans GitHub, signale les écarts aux stratégies internes, et surtout transforme le pentest en service on-demand : l’agent construit un plan d’attaque spécifique à chaque application à partir du code, des specs et de la doc, puis exécute des scénarios multi-étapes couvrant OWASP Top 10 et failles de logique métier, avec rapports exploitables et propositions de correctifs. Des early adopters comme SmugMug expliquent avoir réduit leurs campagnes de tests de plusieurs jours à quelques heures, à coûts bien inférieurs aux prestations humaines, en découvrant des bugs métier qui passaient sous les radars des outils classiques.
* AWS DevOps Agent complète le triptyque côté exploitation. Il se comporte comme un SRE virtuel toujours d’astreinte, connecté à CloudWatch, Datadog, Dynatrace, New Relic, Splunk, aux runbooks, aux dépôts de code et aux pipelines CI/CD. L’agent cartographie les ressources, corrèle métriques, logs, traces et déploiements, et commence à enquêter dès qu’une alerte tombe, qu’il soit 2 h du matin ou en pleine journée. Son objectif est double : raccourcir drastiquement le MTTR en identifiant la root cause et en proposant (ou en exécutant sous contrôle) des plans de remédiation, puis analyser les incidents passés pour recommander des améliorations ciblées en observabilité, en dimensionnement d’infrastructure, en robustesse des pipelines ou en résilience applicative. En interne chez AWS, le service revendique plus de 86 % de succès dans l’identification de la cause racine sur des milliers d’escalades, et des clients comme la Commonwealth Bank of Australia rapportent des diagnostics ramenés de plusieurs heures à moins d’un quart d’heure sur des incidents réseau/identité complexes. L’agent s’intègre aux canaux existants (Slack, PagerDuty, ServiceNow) pour garder les humains dans la boucle tout en automatisant l’essentiel de l’analyse.
Bien sûr, la promesse est séduisante, mais reste à éprouver en production : les services ne sont encore qu’en preview, limités géographiquement, et l’histoire récente des agents IA invite à la prudence sur la robustesse réelle, le taux d’erreurs et la gouvernance des droits d’action.
Reste que, pris ensemble, ces Frontier Agents matérialisent la vision d’AWS d’un « agentic SDLC » : développement, sécurité et opérations confiés à des IA spécialisées, construites sur la même base technologique que les agents que les clients pourront eux-mêmes développer : Bedrock AgentCore
Établir la confiance : Evaluation, mémoire et Policy
Pour transformer ces agents en briques de production, AWS devait adresser la question de la confiance. C’est le rôle des nouvelles capacités d’Amazon Bedrock AgentCore.
Pour rappel, Bedrock AgentCore est le runtime commun des agents AWS : il gère identité, outils, exécution et observabilité, que l’on utilise Strands, LangGraph ou d’autres frameworks. C’est le socle sur lequel reposent non seulement les Frontier Agents, Nova Act ou Transform, mais également tous les agents IA métiers créés par les entreprises avec Strands Agents SDK.

Et c’est par AgentCore qu’AWS veut construire la confiance dans l’IA agentique. À re:invent 2025, l’hyperscaler a annoncé trois nouvelles briques au cœur d’AgentCore destinées à forger cette confiance :
* AgentCore Policy permet de définir, en langage naturel ou via des règles structurées, ce qu’un agent a le droit de faire : quels outils (APIs, fonctions Lambda, MCP servers, SaaS) il peut appeler, sur quelles ressources, dans quelles conditions. Les politiques sont appliquées en dehors de la boucle de raisonnement de l’agent, via AgentCore Gateway, afin de vérifier chaque action avant qu’elle n’accède aux systèmes.
* AgentCore Evaluations fournit une batterie d’évaluateurs pour mesurer la qualité des agents (précision, taux de succès, qualité des appels d’outils, sécurité, etc.) avant et après mise en production. Les résultats sont remontés dans CloudWatch, ce qui ouvre la porte à une véritable observabilité des agents.
* AgentCore Memory & Knowledge apporte une mémoire de long terme plus structurée aux agents, en enregistrant des « épisodes » (contexte, raisonnement, actions, résultats) pour que les agents puissent capitaliser sur leurs expériences passées.
En complément, AWS Lambda Durable Functions ajoute un mécanisme de gestion d’états et de workflows longue durée pour les applications multi-étapes, y compris les flux d’agents. L’idée est très proche des Durable Functions d’Azure : permettre à un agent ou à un orchestrateur de reprendre un workflow à tout moment sans ré-implémenter la gestion d’état dans chaque service.
Pris ensemble, Policy + Evaluations + Memory + Durable Functions constituent un socle de « TRiSM agentique » (Trust, Risk & Security Management) maison, qui répond directement aux critiques souvent adressées aux approches agents trop bricolées.
Sécuriser un écosystème d’agents IA
Côté sécurité, AWS a annoncé l’extension de GuardDuty Extended Threat Detection à Amazon EC2 et Amazon ECS, en plus des IAM, S3 et EKS déjà supportés. GuardDuty Extended Threat Detection corrèle les signaux de multiples sources (CloudTrail, VPC Flow Logs, DNS, runtime, détection de malware) pour détecter des séquences d’attaque multi-étapes et fournir des findings unifiés de haut niveau.
En parallèle, AWS Security Hub devient généralement disponible avec des capacités d’analytics quasi temps réel, corrélant automatiquement les signaux de GuardDuty, Inspector, Macie et de son propre CSPM pour prioriser les risques et fournir des vues historiques et des tendances.
Enfin, CloudWatch se voit renforcé pour l’observabilité des applications IA et agentiques, avec des dashboards dédiés aux agents et aux modèles, capables de suivre les latences, erreurs, usages de tokens et résultats d’évaluations AgentCore.
Pour les DSI, l’enjeu est de comprendre que la même logique de corrélation et d’observabilité qui s’appliquait aux micro-services s’étend désormais aux agents, avec un risque de complexité accrue, mais aussi la possibilité de centraliser opérations, sécurité et qualité IA dans un même outillage.

Au terme de cette édition 2025, la vision agentique d’AWS ressemble moins à un grand récit inspirant qu’à un plan industriel. Là où d’autres parlent d’expériences utilisateur, AWS parle de chaînes de production : silicium optimisé pour le coût par token, data-plane unifié autour de S3, forge de modèles, runtime agentique, outils pour développeurs, modernisation, sécurité et observabilité. L’agent IA n’est pas un gadget ; c’est une main-d’œuvre logicielle qu’il faut recruter, former, outiller, encadrer et auditer comme n’importe quelle équipe.
Cette approche répond finalement assez frontalement aux défis du moment : comment absorber l’explosion de la dette technique, sécuriser un SI toujours plus distribué, industrialiser la création d’applications et d’assistants IA sans exploser les coûts ni la surface de risque ? La réponse d’AWS, c’est un « pipeline agentique » complet : on fabrique les modèles, on les spécialise, on branche les données, on encadre les agents par des politiques, on les mesure en continu et on les branche sur les processus existants. Avec, en toile de fond, l’idée d’un SDLC où développement, sécurité et opérations sont, au moins en partie, pris en charge par des agents spécialisés.
Reste la question de la maturité d’une telle offre face à Microsoft et Google. Ce qui est sûr c’est que les progrès réalisés en un an sont flagrants. Il y a un an, les agents IA tenaient davantage du concept que d’une solution déployable. Mais depuis quelques semaines il apparaît clairement que, sans parler de maturité, l’écosystème IA agentique dispose désormais de fondations plus concrètes. Sur l’infrastructure, les données et le tooling de base, la proposition d’AWS est déjà solide : la pile est profonde, cohérente et exploitable (et même exploitée) en production par des organisations très avancées. Sur la couche purement agentique, AWS a clairement changé de dimension cette année avec AgentCore, Nova Act, Frontier Agents même si beaucoup d’éléments demeurent en preview, très AWS-centrés et bien évidemment encore trop peu éprouvés à grande échelle. AWS a peut-être moins de « magie » apparente qu’un ChatGPT, un Gemini 3 ou un Nano Banana Pro, mais l’hyperscaler construit, brique par brique, la chaîne de montage de cette IA agentique promise depuis le début de l’année et qui semble enfin prendre de la substance à l’aube de l’année 2026.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











