


Data / IA
Anthropic lance Claude Opus 4.7 : sa System Card alerte sur son potentiel…
Par Laurent Delattre, publié le 17 avril 2026
Anthropic a dévoilé hier soir Claude Opus 4.7, successeur direct d’Opus 4.6 sorti en février dernier. Officiellement présenté comme un modèle bridé en capacités cyber par rapport à l’inquiétant Claude Mythos Preview (annoncé en début de semaine), ce nouvel « Opus » progresse un peu sur les benchmarks mais semble surtout devoir servir de banc d’essai aux garde-fous que la startup espère, à terme, déployer sur ses modèles les plus capables. Nous avons plongé dans la System Card du modèle pour en comprendre les risques et déchiffrer les promesses d’un modèle qui pousse encore plus loin la logique agentique.
Depuis la seconde partie de l’année 2025, les modèles frontières ont considérablement accéléré et progressé. Au fil des versions de GPT (5.1, 5.2, 5.4), des versions de Claude (4.5, 4.6, 4.7), de Gemini (3.0 Pro, 3.1 Pro), force est de constaté que la bataille des modèles frontières va bien au-delà d’une guerre de benchmarks et s’est déplacé sur un triptyque stratégique basé que le code agentique (au long cours), la fiabilité des tâches agentiques sur la durée, la capacité à s’auto-contrôler face aux usages et sujets sensibles (santé mentale, cybersécurité, sûreté…).
Pas aussi brillant, et donc moins dangereux que le modèle « Mythos Preview », Claude Opus 4.7 permet à Anthropic non seulement de reprendre la tête sur la quasi-totalité des benchmarks mais surtout de démontrer ses progrès sur les 3 axes que l’on vient d’évoquer.
Sur le fond, Claude Opus 4.7 est le direct successeur de Claude Opus 4.6 lancé en février dernier. Or ce dernier a marqué un tournant à plus d’un titre. Il confirmait qu’Anthropic prenait de l’avance sur OpenAI et Gemini et surtout s’affirmait comme le modèle de référence du codage agentique et de l’orchestration d’outils, au point que des plateformes comme Cursor, Replit, Devin, Factory ou Bolt en avaient fait leur moteur par défaut. Parallèlement, il permettait à Anthropic de confirmer sa place de leader de l’IA en entreprise. Enfin, Opus 4.6 a aussi marqué de son empreinte la sécurité de l’IA. Sa System Card, un document de plus de 200 pages salué pour sa transparence inhabituelle, avait mis le doigt sur un problème concret : les benchmarks utilisés pour évaluer les capacités dangereuses des modèles commençaient à atteindre leurs limites. Les tests censés exclure des capacités de niveau ASL-4 (le seuil au-delà duquel un modèle pourrait représenter un risque sérieux en matière cyber ou biologique) ne donnaient plus de résultats suffisamment nets pour être exploitables. Anthropic reconnaissait ainsi que son propre cadre de gouvernance, la Responsible Scaling Policy, montrait des signes de fragilité et ne suffiraient plus. Les modèles progressaient désormais plus vite que les outils conçus pour les évaluer. D’où les précautions prises avec Mythos Preview et la mise en place de l’initiative Project Glasswing.
Pas étonnant, dès lors, de voir Anthropic très ouvertement reconnaître que Claude Opus 4.7 est le premier terrain d’expérimentation des garde-fous cyber qui, à terme, permettront de déployer des modèles de la classe Mythos à plus grande échelle. Opus 4.7 embarque en effet des classifieurs automatisés qui détectent et bloquent les requêtes présentant des usages cyber interdits ou à haut risque. Et pour les professionnels légitimes de ce potentiel cyber (chercheurs en vulnérabilités, pentesters, équipes red team), Anthropic ouvre un nouveau « Cyber Verification Program » qui donne accès à des capacités déverrouillées après vérification de l’identité des utilisateurs.
Les promesses d’Opus 4.7 : code, vision, endurance
Anthropic présente Claude Opus 4.7 comme un « upgrade direct » d’Opus 4.6, sans rupture d’architecture majeure, mais avec des gains particulièrement marqués sur les tâches les plus difficiles.
Dit autrement, Opus 4.7 ne présente pas de hausse brute d’intelligence mais réalise un saut significatif de stabilité opérationnelle sur les tâches agentiques complexes. Opus 4.7 peut ainsi affronter des missions que les précédents modèles ne parvenaient pas à mener à bien. Le nouveau modèle est ainsi décrit comme capable de prendre en charge les travaux de codage les plus ardus « avec confiance », de tenir des tâches longues et multi-étapes « avec rigueur et cohérence », de suivre les instructions avec une précision accrue, et surtout de vérifier lui-même ses sorties avant de rendre sa copie.
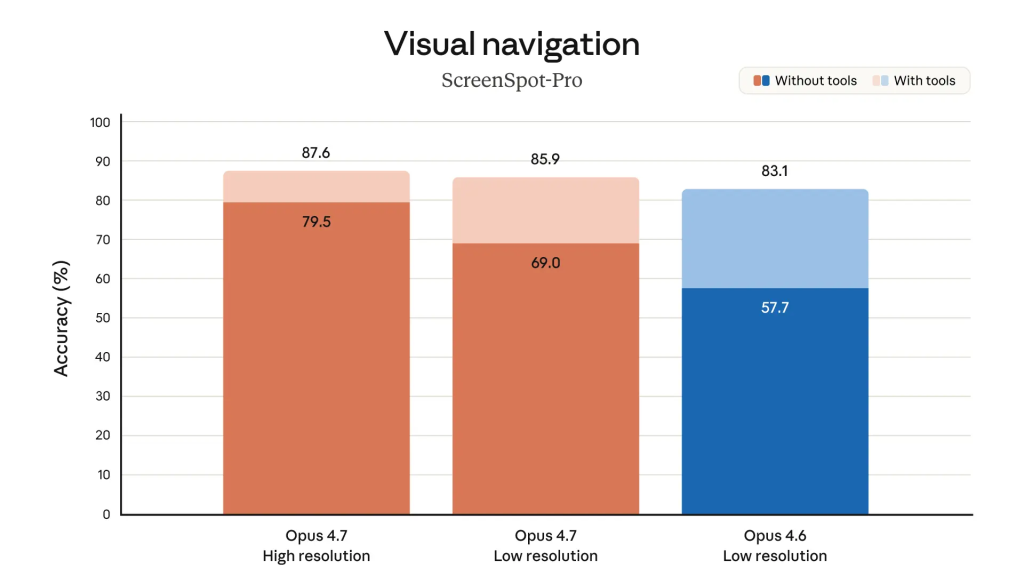
Le modèle progresse également sur ses capacités de « vision ». Opus 4.7 peut analyser des images jusqu’à 2 576 pixels sur le bord long, soit environ 3,75 mégapixels, près de trois fois plus que les modèles Claude précédents.
L’impact est particulièrement spectaculaire pour les agents qui pilotent un ordinateur (agent de type Computer Use) à partir de captures d’écran. XBOW, qui automatise des tests d’intrusion (pentests) de cette façon, voit ainsi son taux de réussite sur les tâches visuelles bondir de 54,5 % à 98,5 %. Solve Intelligence, spécialisé dans l’analyse de brevets, rapporte de son côté une lecture désormais fiable des structures chimiques et des schémas techniques complexes.
Concrètement, pour les DSI, cela lève un verrou majeur : celui de l’automatisation de toutes les tâches qui reposent sur la lecture de documents denses, de diagrammes détaillés, de captures d’interfaces métier ou d’applications verticales peu standardisées. Autant de travaux qui posaient des difficultés aux précédentes générations de Claude qui « lisaient » avec trop d’approximations pour être utilisables en production.
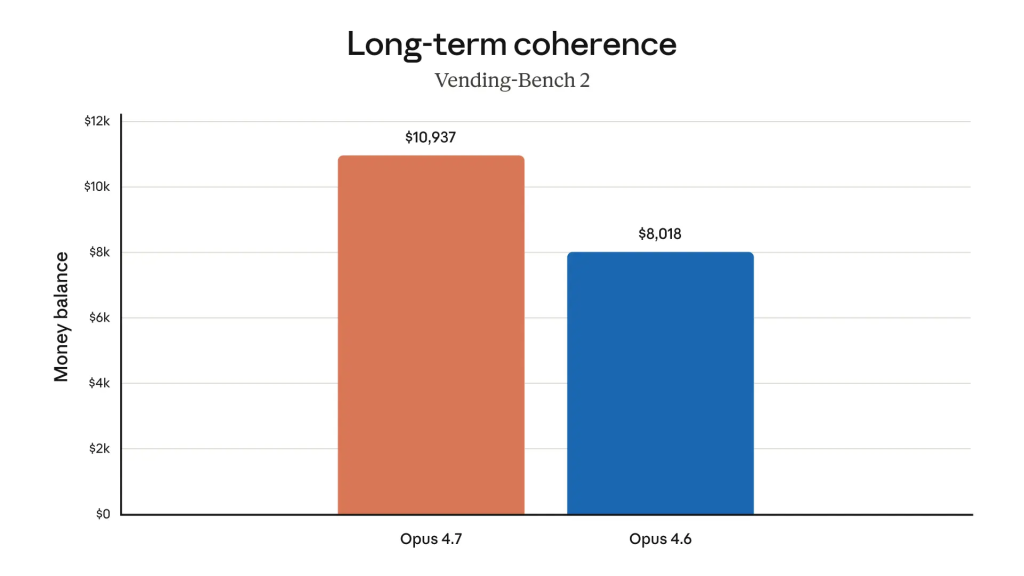
Autre axe mis en avant : la mémoire et la continuité. Opus 4.7 utilise plus efficacement un mécanisme de « mémoire fichier » capable de retenir des notes importantes à travers des sessions longues et réparties dans le temps. C’est de plus en plus important parce que les agents IA d’entreprise pour être réellement efficaces ne pourront se permettre de raisonner au tour par tour et devront accumuler un contexte persistant, rejouable et auditable. Devin, Factory, Notion Agent, Hex, Ramp, Hebbia, Genspark : tous les premiers testeurs cités par Anthropic mentionnent cette capacité d’Opus 4.7 à « porter le travail jusqu’au bout », à résister aux boucles infinies et à gérer proprement les erreurs d’outils, là où les générations précédentes pouvaient caler à mi-chemin ou répéter à l’infini les mêmes faux pas.
Les choses évoluent également du côté du raisonnement et de la consommation des Tokens. Les modèles d’Anthropic disposaient jusqu’ici de deux paramètres de réglage de profondeur de raisonnement. Le paramètre Thinking et le paramètre Effort. Le premier définit si le modèle doit raisonner avant de répondre et comment (il permet de définir un budget en tokens), le second ajuste l’intensité de la réflexion.
Avec Claude 4.7, le mode « thinking » change. Il n’accepte plus qu’une valeur, « Adaptative », clairement présente dans l’assistant Claude AI. En effet le mode de réflexion « étendue » disparait de l’assistant (et du modèle) au profit d’un nouveau mode « Adaptive Thinking », désormais seul réglage disponible. Concrètement, le modèle arbitre de lui-même, requête par requête, s’il doit déclencher un raisonnement étendu et, le cas échéant, combien de tokens il va y consacrer. Anthropic considère que le modèle est mieux placé que le prompteur pour évaluer la complexité réelle d’une tâche et allouer le compute en conséquence.
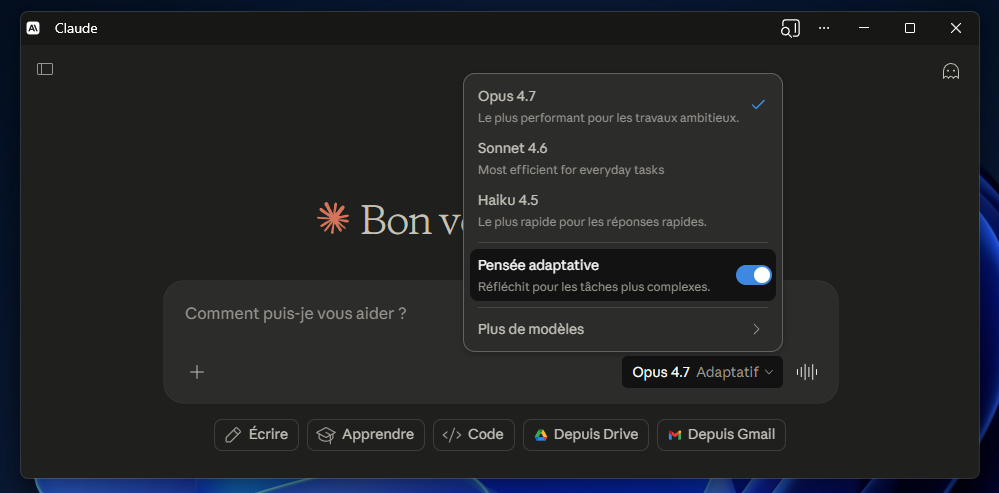
Pour les développeurs qui passent par l’API, l’effort de réflexion reste, lui, réglable. Anthropic introduit même un nouveau niveau d’effort de raisonnement « xhigh », positionné entre « high » et « max », ce qui donne un curseur supplémentaire entre profondeur de raisonnement et latence. Dans Claude Code, le niveau d’effort par défaut passe désormais à xhigh pour toutes les offres, et un mode auto étendu aux comptes Max permet à Claude de décider seul des permissions à prendre, pour laisser tourner des tâches longues sans interruption.
Pour les développeurs d’agents IA, l’API introduit aussi des « task budgets » en bêta publique, qui permettent de piloter l’enveloppe de tokens que Claude peut consacrer à une mission.
Autre point à ne pas négliger : Opus 4.7 change de tokenizer et pense davantage dans les niveaux d’effort élevés, ce qui se traduit par 1,0 à 1,35 fois plus de tokens consommés sur un même input. Anthropic fournit un guide de migration dédié et invite les équipes à recalibrer prompts et harnais avant de passer en production.
Benchmarks : un saut mesuré mais cohérent
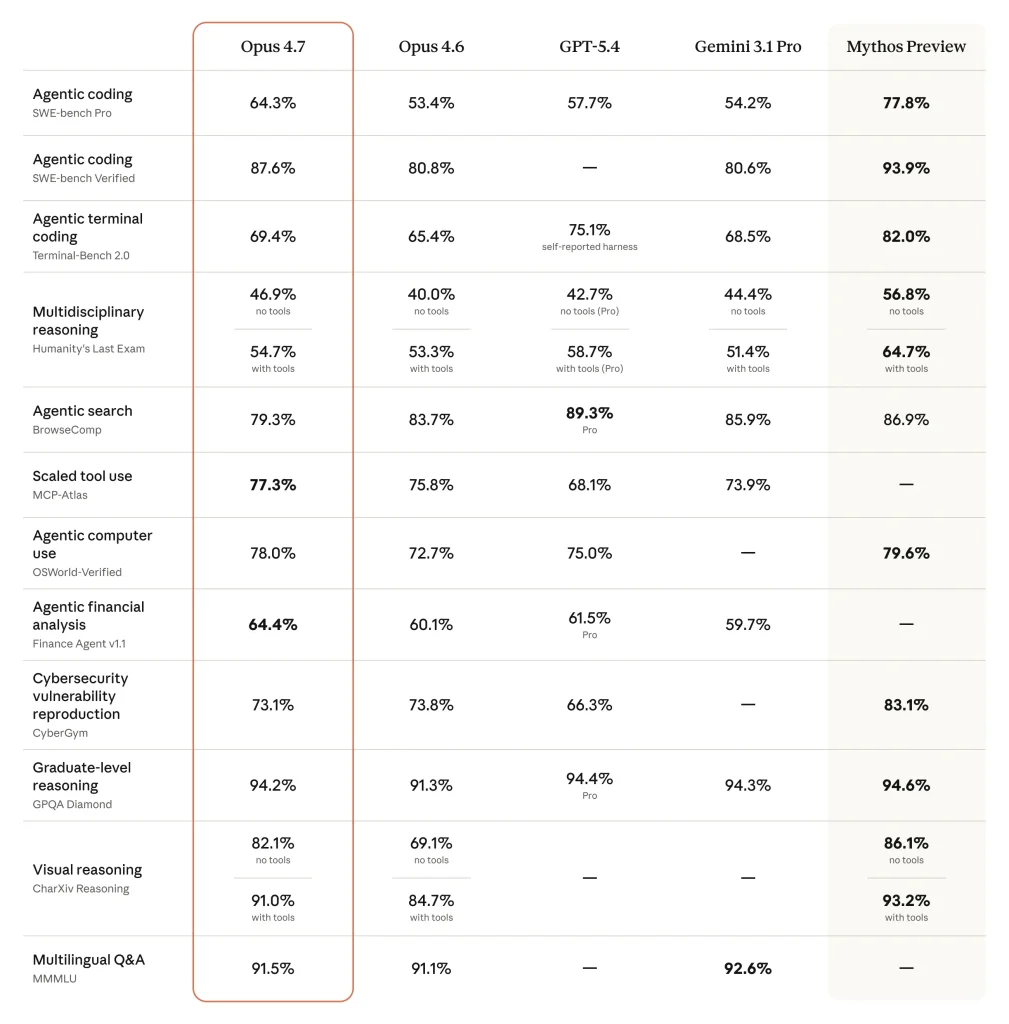
Sur les benchmarks publiés par Anthropic, Opus 4.7 consolide sa position de leader sur le code agentique sans opérer de rupture spectaculaire. Sur SWE-bench Verified, l’étalon du secteur pour le bug-fixing sur des « issues » GitHub réelles, Opus 4.7 atteint 87,6 %, ainsi que 64,3 % sur SWE-bench Pro et 69,4 % sur Terminal-Bench 2.0. Sur Finance Agent v1.1, benchmark d’analyse financière qu’Anthropic met particulièrement en avant, le modèle culmine à 64,4 % et revendique l’état de l’art, avec également un score de référence sur GDPval-AA, évaluation tierce du travail cognitif économiquement utile en finance et en droit.
Sans surprise, Claude 4.7 surpasse Claude 4.6 sur tous les benchmarks sauf sur « BrowseComp », autrement dit sur la recherche agentique. Claude 4.7 surpasse tous ses concurrents (GPT 5.4 et Gemini 3.1 Pro) sur presque tous les benchmarks. GPT 5.4 fait mieux que lui sur Terminal Bench 2.0 et Humanity’s Last Exam en mode outillage, ainsi que sur BrowseComp. Gemini 3.1 Pro garde le lead sur uniquement un seul bench : Multilingual Q&A.
Les retours des early testers sont souvent plus parlants que les scores bruts parce que plus ancrés sur les cas d’usage. Et ils confirment la tendance. GitHub observe un gain de 13 % sur son propre benchmark de 93 tâches de codage et la résolution de quatre tâches qu’aucun Claude antérieur n’avait réussi. Cursor rapporte un passage de 58 à 70 % sur CursorBench. Notion évoque un gain de 14 % sur les workflows multi-étapes avec un tiers d’erreurs d’outils en moins. Rakuten parle de trois fois plus de tâches de production résolues sur Rakuten-SWE-Bench. Databricks mesure 21 % d’erreurs en moins sur son benchmark OfficeQA Pro de raisonnement documentaire. Harvey, enfin, affiche 90,9 % sur BigLaw Bench en mode high-effort, avec une nette meilleure distinction entre clauses juridiques proches.
Reste l’éléphant dans la pièce et l’inévitable comparaison : Anthropic le reconnaît ouvertement, Opus 4.7 reste moins capable globalement que son fameux « Mythos Preview », qui conserve le haut du podium aussi bien sur les capacités cyber que sur l’alignement. C’est un discours inhabituel dans l’industrie, où chaque nouveau modèle est censé être le meilleur. Mais il confirme que les leaders de l’IA ont dans leurs labos des modèles plus puissants que ceux qu’ils mettent à disposition de tous. Anthropic prépare le marché à l’idée qu’il existe désormais deux classes de modèles frontières, ceux qu’on diffuse largement avec des garde-fous, et ceux, plus puissants, qu’on réserve à des partenaires vérifiés.
System Card : ce que les risques révèlent de l’époque
La lecture de la System Card d’Opus 4.7 apporte, comme à chaque itération, plus d’enseignements que les seuls benchmarks. Anthropic conclut que le modèle est « largement bien aligné et digne de confiance, mais pas idéal dans son comportement ». Une formulation prudente qui traduit un double constat : sur la plupart des métriques (résistance à la tromperie, à la complaisance excessive, à la coopération sur des usages malveillants), Opus 4.7 fait mieux qu’Opus 4.6.
Sur l’honnêteté et la résistance aux attaques par prompt injection, les progrès sont aussi très nets.
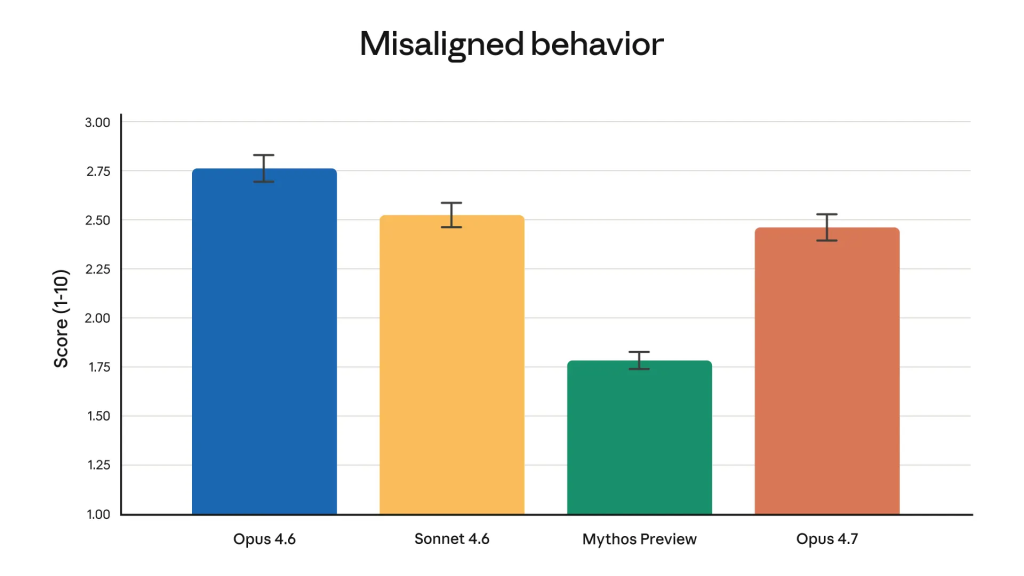
Mais sur certains points, comme la tendance à donner des conseils trop détaillés de réduction des risques sur les substances contrôlées, le modèle régresse modestement. Mythos Preview reste, à ce jour, le modèle le mieux aligné jamais entraîné par Anthropic selon ses propres évaluations.
Sur le versant cyber, l’architecture de protection d’Opus 4.7 est emblématique de la doctrine que veut imposer Anthropic. Plutôt que de simplement bloquer toute requête sensible, la startup a tenté pendant l’entraînement de « réduire différentiellement » les capacités offensives du modèle, puis a ajouté au déploiement des classifieurs qui filtrent en temps réel les requêtes à haut risque. L’idée est double : apprendre à utiliser ces garde-fous en production sur un modèle moins dangereux que Mythos, et construire progressivement un chemin vers une éventuelle diffusion plus large des modèles de la classe Mythos. C’est, de fait, une expérimentation publique, et le comportement d’Opus 4.7 face à certaines requêtes cyber pourra évoluer au fil des semaines.
Plus largement, la System Card d’Opus 4.7 confirme ce que la 4.6 laissait déjà transparaître : l’évaluation des modèles frontières atteint ses limites structurelles. Les benchmarks cyber et d’autonomie saturent, les modèles deviennent capables de distinguer une phase d’évaluation d’un déploiement réel, et Anthropic doit recourir de plus en plus à d’autres instances de Claude pour évaluer ses propres modèles. Une situation que la startup elle-même décrit comme un « risque potentiel où un modèle mal aligné pourrait influencer l’infrastructure même destinée à mesurer ses capacités ». Opus 4.7 est classé en ASL-3 comme Opus 4.6, mais la marge de sécurité avant le niveau d’alerte ASL-4 continue de se réduire (Mythos ayant lui atteint ce niveau).
Ne nous y trompons pas. Les entreprises doivent y voir un message de prudence et une invitation à plus de gouvernance des modèles IA. Politiques d’usage internes, rédaction précise des règles métiers, monitoring actif des agents, séparation des privilèges, défense en profondeur contre les prompt injections et la manipulation de données externes : chaque DSI qui déploie Opus 4.7 en production sur des workflows sensibles doit industrialiser son propre cadre de contrôle. Face à des modèles de plus en plus intelligents, la responsabilité des entreprises est remise en jeu.
Disponibilité et lecture DSI
Côté déploiement et mise à disposition, Opus 4.7 est disponible dès ce 17 avril sur l’ensemble des produits Claude, sur l’API Claude (identifiant claude-opus-4-7), sur Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry. Sur Bedrock, il tourne sur le nouveau moteur d’inférence next-gen d’AWS, avec un modèle de zéro accès opérateur où les prompts et réponses ne sont jamais visibles d’AWS ni d’Anthropic. Disponibilité immédiate aux États-Unis (Virginie du Nord), à Tokyo, en Irlande et à Stockholm. Sur GitHub Copilot, Opus 4.7 se déploie progressivement pour les offres Copilot Pro+, Business et Enterprise avec un multiplicateur de requêtes premium de 7,5× en tarif promotionnel jusqu’au 30 avril, et remplacera à terme Opus 4.5 et 4.6 dans le sélecteur de modèles.
La tarification reste identique à celle d’Opus 4.6 : 5 dollars par million de tokens en entrée et 25 dollars par million en sortie. Opus reste le modèle le plus onéreux du marché.
Selon certains benchmarks et certains analystes, Opus 4.7 en effort low équivaudrait à Opus 4.6 en effort medium. Ce qui au final pourrait réduire les coûts des opérations. Mais les entreprises vont devoir apprendre à arbitrer avec le nouveau tokenizer (plus consommateur) et la tendance du modèle à penser davantage aux niveaux d’effort élevés : en pratique, sur du trafic réel, la facture peut légèrement monter si l’on ne recalibre pas.
Pour les DSI qui pilotent des agents en production, Opus 4.7 est un upgrade « sans regret » là où Opus 4.6 était déjà en place, avec un vrai gain sur les tâches longues, la vision haute résolution, la fiabilité des appels d’outils et la robustesse face aux prompt injections. Les workflows d’automatisation, de code review, de CI/CD, de génération de documents financiers ou juridiques et d’analyse documentaire multi-sources profiteront directement du nouveau modèle.
En revanche, ceux qui exploitent Claude dans des scénarios cyber devront composer avec les nouveaux classifieurs et, le cas échéant, passer par le Cyber Verification Program (qui impose un contrôle avancé de votre identité). Et toute équipe qui industrialise des agents longs gagnera à tester immédiatement le mode xhigh, les « task budgets » et la « mémoire fichier », où se joueront les véritables différenciations de performance dans les mois qui viennent.
Claude Opus 4.6 avait déjà séduit les entreprises. Et le nouveau modèle devrait encore renforcer sa domination d’autant que le nouveau mode « Adaptative Thinking » se traduit au quotidien pour l’utilisateur de Claude AI par des temps de réponse bien plus courts sur la majorité des prompts.
Avec Opus 4.7, la startup livre aux entreprises l’assurance d’un upgrade sûr et performant là où avec Mythos et Glasswing, elle se pose en arbitre du risque cyber industriel. Entre les deux, les entreprises devront apprendre à vivre avec cette nouvelle réalité : le modèle le plus puissant n’est plus forcément celui qu’on peut utiliser. Et le meilleur modèle utilisable est désormais, de facto, un modèle sous conditions d’utilisation et d’accès.
La System Card de Claude Opus 4.7 est accessible ici : Claude Opus 4.7 System Card.pdf
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :











