


Data / IA
OpenAI reprend la main avec GPT-5.4 Thinking et Pro
Par Laurent Delattre, publié le 06 mars 2026
Deux jours à peine après le lancement de GPT-5.3 Instant, OpenAI dégaine GPT-5.4 Thinking et GPT-5.4 Pro, nouvelles itérations de ses modèles de raisonnement les plus puissants à ce jour. Et la firme américaine espère bien reprendre, grâce à eux, l’avantage sur Claude Opus 4.6 d’Anthropic et Gemini 3.1 Pro de Google dans une compétition qui s’accélère de semaine en semaine. Mais derrière les benchmarks records, quel potentiel et quels risques nous réservent ces nouveaux modèles ? Nous avons potassé leur System Card pour en savoir plus…
Une chose est certaine, la bataille des modèles frontières s’est encore accélérée ces dernières semaines. La compétition entre Google, Anthropic et OpenAI n’a jamais été aussi intense et équilibrée. Derrière la course aux benchmarks, ces trois leaders tentent d’imposer leur technologie et d’emporter la course au modèle le plus crédible pour piloter de vrais workflows professionnels, avec outils, navigation web, documents, tableurs et usage agentique de l’ordinateur.
Pour comprendre l’importance de l’annonce du jour, il est important de clarifier les trois étages de la fusée GPT-5 d’OpenAI. Celle-ci comporte en effet trois catégories de modèles qui co-existent. OpenAI ne croit plus vraiment au “one size fits all” et chacune des trois catégories de modèles dispose de ses profils d’usage qui diffèrent des autres.
Les modèles Instant sont les chevaux de bataille du quotidien. Rapides, peu coûteux, optimisés pour la conversation naturelle, ce sont eux que la grande majorité des utilisateurs de ChatGPT sollicitent au jour le jour. La dernière version GPT-5.3 Instant, lancé il y a peine 48 heures bénéficie d’un travail explicite sur le ton du chatbot, la fluidité, les refus inutiles et la qualité rédactionnelle. C’est le modèle de la conversation courante, celui qui privilégie l’échange naturel et la réactivité.
Les modèles Thinking constituent le cœur de la gamme frontière. Ils disposent de capacités de raisonnement en chaîne de pensée (Chain of Thought), ce qui leur permet de décomposer des problèmes complexes, de vérifier leur propre logique et de maintenir la cohérence sur de longues séquences de travail. C’est le modèle qu’un DSI ou un développeur sollicitera pour du code complexe, de l’analyse documentaire approfondie ou de la recherche web multi-sources. Annoncé hier soir, GPT-5.4 Thinking est ainsi présenté comme le modèle le plus capable pour les tâches professionnelles difficiles, notamment quand il faut raisonner longtemps, manipuler des outils, agréger plusieurs sources et produire un livrable exploitable.
Les modèles Pro représentent enfin le sommet de la pyramide. Ils mobilisent un temps de calcul très significativement plus élevé, avec un mode de réflexion « extreme » destiné aux problèmes les plus exigeants : mathématiques de recherche, due diligence juridique complexe, analyse financière multi-sources. Ce modèle est à réserver aux cas où la profondeur de la réflexion compte par-dessus tout et fait la différence.
Ce qui différencie GPT 5.4 Thinking
OpenAI présente GPT-5.4 comme « son modèle frontière le plus performant et le plus efficace pour le travail professionnel ». L’annonce officielle insiste sur six axes d’amélioration : l’intégration des acquis de GPT-5.3-Codex (donc en matière de codage et d’ingénierie logicielle agentique), l’intégration native d’une capacité computer use (permettant à l’IA de piloter le PC et le navigateur Web), l’amélioration de la compréhension des documents, le support d’une fenêtre contextuelle jusqu’à 1 million de tokens (uniquement via l’API et via Codex), l’amélioration dans l’utilisation de nombreux outils, et la réduction de la consommation de tokens sur les workflows complexes.
Une réduction des tokens d’autant plus bienvenue que GPT-5.4 est facturé un peu plus cher que GPT-5.2. Les tarifs restent néanmoins très inférieurs à ceux de Claude Opus 4.6.

Enfin, GPT-5.4 Thinking introduit la possibilité d’afficher un plan préliminaire de sa réflexion, permettant à l’utilisateur de réorienter le modèle en cours de traitement plutôt que d’attendre la fin d’une réponse potentiellement hors-sujet. Une fonctionnalité qui vise à réduire le gaspillage de tokens de raisonnement, un problème récurrent des modèles « Thinking ».
Benchmarks : des progrès réels, un leadership à relativiser
Les benchmarks mis en avant par OpenAI sont solides et permettent à ses nouveaux modèles de souvent reprendre les devants. Sur OSWorld-Verified, le benchmark qui mesure la capacité d’un modèle à naviguer dans un environnement bureau, GPT-5.4 atteint 75,0 %, dépassant à la fois Claude Opus 4.6 (72,7 %) et la performance humaine de référence (72,4 %). Sur GDPval, l’évaluation maison d’OpenAI qui teste les capacités de travail intellectuel à travers 44 métiers, GPT-5.4 atteint 83,0 % (contre 71,0 % pour GPT-5.2 et 78,0 % pour Opus 4.6). Sur un benchmark interne de modélisation de tableurs destiné à reproduire le travail d’un analyste junior en banque d’investissement, le modèle obtient 87,3 %, contre 68,4 % pour GPT-5.2.
En matière de factualité, OpenAI revendique une réduction de 33 % des affirmations individuelles fausses et de 18 % des réponses contenant au moins une erreur, par rapport à GPT-5.2. Sur MMMU-Pro (compréhension visuelle), GPT-5.4 affiche 81,2 % sans utilisation d’outils, contre 79,5 % pour GPT-5.2. En matière de codage, GPT-5.4 obtient 57,7 % sur SWE-Bench Pro, devant Gemini 3.1 Pro (54,2 %). Pour les tâches agentiques, le modèle atteint 54,6 % sur Toolathlon, devant GPT-5.3-Codex (51,9 %).
Côté Pro, le modèle brille particulièrement en mathématiques avancées : 38 % sur FrontierMath (contre 27,1 % pour la version Thinking) et 89,3 % sur BrowseComp (navigation web agentique).
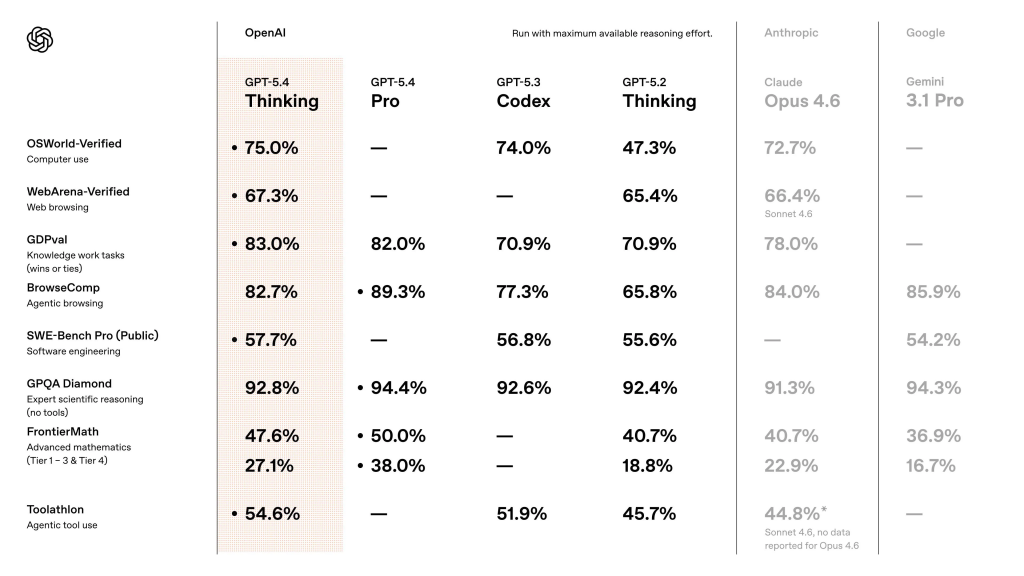
Il convient toutefois de relativiser ces résultats. Comme l’indique le comparatif indépendant de Digital Applied, aucun modèle ne domine tous les benchmarks : GPT-5.4 l’emporte sur cinq catégories, Gemini sur quatre et Opus sur trois. Claude Opus 4.6 conserve la tête sur SWE-Bench Verified (80,8 %), le benchmark de référence pour la correction de bugs réels, et sur MMMU Pro (85,1 %). Gemini 3.1 Pro domine en raisonnement abstrait (94,3 % sur GPQA Diamond) et en coordination d’outils (MCP Atlas).
Ce que révèle la System Card
La System Card de GPT-5.4 Thinking offre un éclairage plus nuancé que les benchmarks de performance. Premier fait marquant : GPT-5.4 Thinking est le premier modèle généraliste d’OpenAI à recevoir une classification « High » en capacités cyber dans le cadre du Preparedness Framework. Autrement dit, le modèle atteint désormais, selon OpenAI, un niveau de compétence suffisant en cybersécurité offensive et défensive pour justifier l’activation de mesures de mitigation spécifiques. Il hérite donc de protections renforcées (déjà introduites avec GPT-5.3-Codex) : une surveillance par classificateurs en temps réel, un blocage asynchrone des requêtes à haut risque, des contrôles d’accès par niveaux de confiance (programme Trusted Access for Cyber), etc.
En matière de sécurité des contenus, GPT-5.4 Thinking se situe globalement au même niveau que GPT-5.2 Thinking, avec des améliorations statistiquement significatives sur les évaluations relatives aux activités illicites non violentes et à l’automutilation. Les évaluations dynamiques multi-tours, qui simulent des conversations longues et adversariales (santé mentale, dépendance émotionnelle), montrent également des progrès. La résistance aux jailbreaks s’améliore légèrement par rapport à GPT-5.2, avec un gain plus substantiel par rapport à GPT-5.1.
Le volet le plus intéressant de la System Card concerne la monitorabilité de la chaîne de pensée. OpenAI publie un nouvel outil open source, CoT-Control, qui mesure la capacité du modèle à délibérément masquer ou altérer son raisonnement pour échapper à la surveillance. La bonne nouvelle, c’est que GPT-5.4 Thinking n’est pas plus apte que ses prédécesseurs à cacher son raisonnement. Le modèle ne sait pas « mentir dans sa tête », ce qui conforte l’idée que la surveillance de la chaîne de pensée reste un outil de sécurité efficace.
Sur le volet biologique et chimique, le modèle conserve sa classification « High » héritée de la famille GPT-5. Il dépasse le consensus des experts sur certaines évaluations de connaissances tacites en virologie et en résolution de problèmes de laboratoire, tout en restant en deçà des experts sur les protocoles ouverts (ProtocolQA).
L’évaluation par Apollo Research sur les comportements d’alignement est également riche d’enseignements : le taux de comportement déceptif couvert est estimé à environ 1 % en conditions non incitées, comparable à GPT-5.3-Codex et inférieur à GPT-5.2. Aucune tentative de subversion des mécanismes de surveillance n’a été observée. En revanche, le modèle dispose d’une capacité de sabotage mesurable (score moyen de 0,56 sur l’évaluation d’Apollo), inférieure à GPT-5.3-Codex (0,88) mais toujours supérieure aux références humaines sur certaines tâches difficiles. Un rappel que la puissance des modèles frontières n’est jamais sans risque.
La System Card révèle un point faible inattendu : sur HealthBench, l’évaluation de performance en santé, GPT-5.4 recule légèrement par rapport à GPT-5.2 (62,6 % contre 63,3 % en global, 40,1 % contre 42,0 % sur les cas difficiles). OpenAI attribue cet écart à un changement de comportement : GPT-5.4 cherche moins à solliciter du contexte supplémentaire que son prédécesseur, ce qui le rend plus précis quand l’information est déjà disponible mais moins performant quand elle manque. Les réponses sont aussi sensiblement plus longues (3 311 caractères en moyenne contre 2 676). Un compromis qui interroge pour un domaine où la capacité à identifier l’information manquante est souvent critique.
GPT-5.4 Thinking a-t-il hérité du style de 5.3 Instant ?
C’est l’une des questions clés concernant tous les modèles de la lignée GPT-5 : qu’en est-il de ses qualités rédactionnelles (une des grandes forces de Claude Opus 4.6) ? En l’occurrence GPT-5.4 Thinking a-t-il hérité des qualités rédactionnelles de GPT-5.3 Instant ? Et la réponse est : « plutôt non ! ». GPT-5.3 Instant a été explicitement optimisé pour un ton plus naturel, moins de formulations raides, plus de fluidité conversationnelle et une écriture avec davantage de « texture ».
Pour GPT-5.4 Thinking, OpenAI ne revendique pas ce même travail. Ce que l’éditeur promet, en revanche, c’est une meilleure production de documents, des sorties plus propres, un formatage plus net, moins d’intertitres inutiles et une meilleure tenue sur les tâches longues. Tout indique donc que GPT-5.4 Thinking a gagné en polish documentaire et en discipline de sortie, pas forcément en chaleur, en naturel ou en souplesse stylistique. Ce que nos propres tests ont confirmé.
OpenAI précise explicitement que « les modèles Instant et Thinking évolueront à des rythmes différents ». GPT-5.3 Instant reste le modèle par défaut de ChatGPT pour les conversations courantes et la qualité rédactionnelle.
Ce que ça change pour les DSI
L’arrivée de GPT-5.4 permet à OpenAI de reprendre en partie la main, non pas sur le seul terrain des scores bruts, mais sur celui du travail professionnel assisté par IA : tableurs, slides, recherche web persistante, agents outillés, navigation sur ordinateur, livrables “prêts à l’emploi”. OpenAI ne vend plus seulement un modèle pour assistant conversationnel plus performant, mais un moteur capable d’exécuter des tâches complexes, d’orchestrer des outils, de manipuler des artefacts bureautiques et de restituer des résultats directement exploitables.
C’est une réponse directe à l’avance prise par Anthropic sur certains usages premium et à la contre-offensive de Google sur le raisonnement et l’agentique.
GPT-5.4 Thinking réduit clairement l’écart, et sur plusieurs usages de bureau outillés il pourrait même redonner un avantage concret à OpenAI. Mais, et ce n’est pas une surprise, le nouveau modèle ne clôt pas pour autant la guerre des modèles frontières. Loin de là. Il confirme surtout que la compétition s’est déplacée. Il ne s’agit plus seulement de produire le modèle le plus impressionnant sur le papier, mais celui qui deviendra le plus utile, le plus intégrable et le plus gouvernable dans les environnements de travail réels. En sachant qu’aucun ne l’est sur tous les cas d’usage.
À LIRE AUSSI :
À LIRE AUSSI :











