DOSSIERS
Hadoop, une boîte à outils qui requiert des compétences très différentes
Par La rédaction, publié le 22 février 2012
De l’expert en programmation parallèle à l’utilisateur métier avancé, en passant par les spécialistes Java ou SQL… tous ont à intervenir autour d’Hadoop, dont la complexité dépend de la brique technologique par laquelle on le sollicite.
Hadoop est-il plus complexe à installer et à manipuler que les plates-formes traditionnelles portées, elles aussi, sur l’analyse de données ? La question exige de distinguer trois aspects intrinsèques de cette pile open source : le déploiement de son infrastructure technique, le développement d’applications et l’exploitation de données.
Sur le premier volet, Charles Zedlewski, vice-président produit de Cloudera, ardent promoteur d’Hadoop, fait valoir l’argument de la simplicité : « Il faut être un sacré bon ingénieur pour bâtir soi-même le socle technique d’un programme développé en interne et destiné au traitement en masse de données. Car cela demande de paramétrer des outils de parallélisation, de montée en charge, de fail-over. Avec Hadoop, tous ces services sont nativement proposés dans le framework. » En l’occurrence, par deux de ses éléments phare : un modèle de programmation (MapReduce) et un système de fichiers (HDFS), tous deux hautement distribués.
C’est juste, confirme Julien Cabot, responsable de l’activité finance chez Octo Technology. Pour autant ce dernier rappelle que « des compétences fines en architecture réseaux et serveurs sont requises. Notamment pour déployer les clusters dans Hadoop. Ce dernier point a tendance à être sous-estimé sous prétexte que la pile open source repose sur du matériel banalisé. »
Le big data à la croisée de quatre monde (Source : Octo Technology)
En matière de développement, les choses semblent là plus ardues. Car exploiter pleinement le potentiel d’Hadoop implique de bâtir des applications conformes au modèle de programmation distribué MapReduce. « De très bons développeurs spécialisés en Java ou dans la conception de requêtes décisionnelles ne maîtriseront pas forcément cette programmation parallèle. Celle-ci relève aujourd’hui d’ingénieurs spécialisés dans les grilles de calcul. On les trouve généralement dans le secteur bancaire, mais ils sont peu nombreux sur le marché », poursuit Julien Cabot. D’ailleurs les fournisseurs d’Hadoop incitent un maximum d’éditeurs (compétents notamment dans l’analytique ou l’intégration de données) à aligner leurs applications et leurs outils sur MapReduce. Histoire de masquer la complexité aux utilisateurs.
MapReduce est-il plus compliqué que SQL ou Excel ? Charles Zedlewski en convient volontiers. Mais il insiste sur le fait que ce framework de développement est bien plus simple que MPI, un langage de programmation largement utilisé par les chercheurs, lui aussi parallèle.
Le « data scientist », un mouton à cinq pattes
MapReduce n’est pas la seule porte d’entrée d’Hadoop. Les données stockées dans son système de fichiers distribué HDFS peuvent également être accessibles par Pig, un langage procédural adapté aux traitements de flux de données parallélisés Pig. Un langage de haut niveau certes, mais qui, là encore, requiert des compétences bien spécifiques.
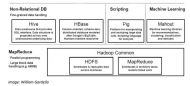
Les composants techniques d’Hadoop
Plus accessible en revanche, Hive. Cet autre module de la pile Hadoop transforme des requêtes SQL en programmes MapReduce (même si ici les requêtes ne sont pas optimisées par la parallélisation). Il s’adresse potentiellement aux utilisateurs avancés, spécialisés dans le décisionnel. « Avec Hive, Hadoop peut être vu comme un infocentre qui stockerait des données de détail en énorme quantité. Sans qu’il y ait besoin de paramétrer des axes d’analyse ou des datamart », précise Julien Cabot.
Et qui pour manipuler ces données, les investiguer, déceler des corrélations jusque là insoupçonnées ? Le fameux « data scientist ». Un mouton à cinq pattes, à la fois très métier mais également capable de mener ces explorations de données, a minima techniques. Dans le cadre d’une étude réalisée par EMC, 83 % des entreprises interrogées s’attendent à connaître une pénurie de « data scientist ». Dans ce contexte, la prolifération d’Hadoop dépendra pour beaucoup de la disponibilité de telles compétences sur le marché.