Data / IA
IA : Les modèles à raisonnement vont aussi rapidement atteindre un plafond !
Par Laurent Delattre, publié le 13 mai 2025
Le plafond de verre des LLM classiques semblait brisé, mais les modèles à raisonnement comme OpenAI o3 ou les modèles « thinking » foncent à leur tour vers leurs propres limites. Les LLM frontières vont de nouveau buter sur de nouvelles limites physiques, méthodologiques et économiques. Et ceci, dès l’an prochain !
Durant des années, les chercheurs en IA ont cru qu’il suffirait de multiplier les paramètres des modèles et les GPU nécessaires à leur apprentissage pour continuer de faire progresser exponentiellement l’intelligence des grands modèles frontières de l’IA générative.
Mais en 2024, tous les spécialistes de l’IA ont découvert l’existence d’un plafond technologique (cf. La dure quête du prochain LLM frontière). Les GPT 5, Claude Opus 3.5, Gemini Ultra 1.5 qui avaient coûté des centaines de millions en R&D et apprentissage ne tenaient pas leurs promesses et n’apportaient que des améliorations marginales qui ne justifiaient pas les surcoûts nécessaires à leur inférence.
Les chercheurs en IA sont alors partis sur d’autres pistes pour continuer à faire évoluer leur modèle frontière et notamment sur les concepts de reinforcement learning (apprentissage par renforcement), chain-of-thoughts (chaîne de pensée) ou encore le deliberative alignment (alignement délibératif). Des recherches qui ont mené à la création des modèles à raisonnement comme « OpenAI o1 » et « OpenAI o3 » et à des modèles hybrides embarquant un mode « Thinking » (Grok 3, Claude Sonnet 3.7 ou encore Gemini 2.5).
La recherche sur les grands modèles de langage (LLM) semblait alors, avec ces modèles à raisonnement (cf. Les modèles à raisonnement : la nouvelle frontière de l’IA), avoir franchi un nouveau cap et avoir brisé le plafond de verre laissant espérer une nouvelle et longue période de croissance pour les modèles IA.
Mais une analyse d’Epoch AI parue cette semaine vient de donner une douche froide à ces espoirs : la voie des « reasoning models » mène aussi à un plafond de verre et se heurte, elle aussi, à des limites physiques et économiques qui pourraient se manifester dès l’an prochain !
Des modèles qui raisonnent mais vont avoir bientôt du mal à progresser
Depuis un an, des laboratoires comme OpenAI ont obtenu des gains spectaculaires d’intelligence et de pertinence sur les benchmarks mathématiques et de programmation en ajoutant une phase d’apprentissage par renforcement aux LLM classiques. Entre o1 et o3, OpenAI affirme avoir multiplié par dix la puissance de calcul dédiée à cette seconde phase, propulsant les performances d’o3 très au‑delà de celles de son prédécesseur. Pour Josh You, analyste chez Epoch AI, « les gains issus de l’entraînement standard des modèles quadruplent chaque année, tandis que ceux liés au renforcement progressent encore dix fois plus vite ; pourtant ces courbes devraient se rejoindre d’ici 2026 ». Autrement dit, la cadence de progression des modèles à raisonnement pourrait se normaliser au même rythme que celle des LLM classiques.
La contrainte n’est pas seulement matérielle. L’entraînement par renforcement exige des jeux de problèmes de plus en plus volumineux et variés, ainsi qu’un important travail expérimental pour calibrer récompenses, prompts et chaînes de pensée. Ces coûts de R & D, invisibles dans les rapports de calcul brut, pèsent lourd : « Si un surcoût permanent lié à la recherche subsiste, il est possible que les modèles de raisonnement ne passent pas à l’échelle autant qu’escompté », alerte Josh You. Dario Amodei, CEO d’Anthropic, tenait un discours similaire dès janvier 2025 : dépenser 1 million de dollars plutôt que 100 000 suffit encore à engranger d’énormes progrès, mais le palier des « centaines de millions » se profile rapidement.
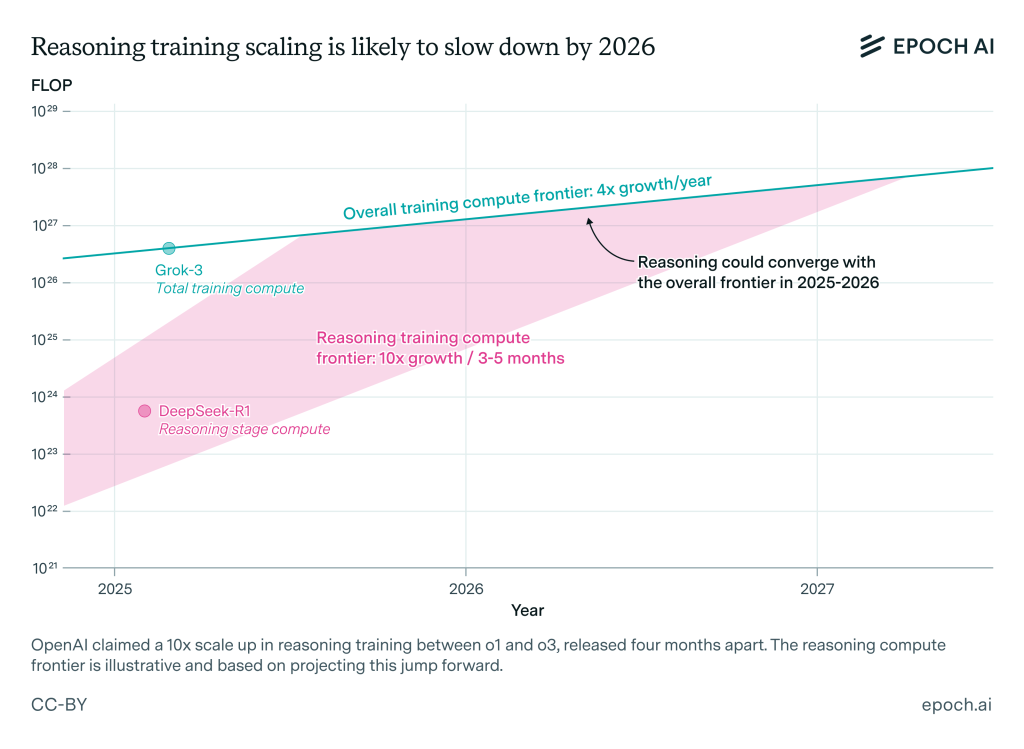
Les premières données publiques confirment que nous restons, pour l’instant, à un ordre de grandeur ou deux en‑deçà du front de calcul maximal observé sur des modèles généralistes (≈10²⁶ FLOP). Néanmoins, DeepSeek‑R1 et Llama‑Nemotron Ultra démontrent qu’il est déjà possible d’atteindre 10²³ FLOP lors de la phase de raisonnement, soit un coût de plusieurs millions de dollars – sans pour autant éliminer les phénomènes d’hallucination, que certains tests montrent même aggravés chez ces architectures (cf. En fait, les IA à raisonnement peuvent halluciner plus que les IA classiques).
Pour les DSI et responsables de projets IA, les progrès fulgurants de ces derniers mois pourraient donc s’essouffler aussi vite qu’ils sont apparus, alors même que les dépenses énergétiques et les risques opérationnels (coût d’inférence, latence, véracité des réponses) continuent d’exploser. Les prochains mois diront si les laboratoires de R&D parviennent à briser ce nouveau plafond de verre. Mais, pour l’heure, la dynamique s’oriente vers un ralentissement inévitable, transformant la question du « quand » en un « comment » durable et économiquement soutenable.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :