


Data / IA
IBM TechXchange 2025 : l’ère de l’autonomie agentique gouvernée est arrivée
Par Laurent Delattre, publié le 17 octobre 2025
Finie la phase de test : IBM pousse l’IA dans le réel ! Avec watsonx, Project Bob et Infragraph, tout devient orchestré, gouverné et branché sur la donnée, du mainframe au cloud.
TechXchange est la conférence annuelle mondiale organisée par IBM pour rassembler sa communauté de développeurs, d’ingénieurs, d’architectes IT et de décideurs techniques autour des dernières innovations de l’entreprise. L’événement, lancé en 2023, se distingue par son orientation résolument technique et collaborative, loin du format plus classique et marketing d’IBM Think. L’édition 2025 s’est tenue la semaine dernière à Orlando. Rythmée par une quinzaine d’annonces clés, la conférence aura surtout rappelé que l’ère de l’expérimentation est terminée. L’éditeur a centré ses annonces sur les moyens d’aider les entreprises à franchir le gouffre qui sépare les projets pilotes des déploiements critiques. Avec un focus sur l’IA agentique bien sûr, mais aussi sur la donnée et sur la sécurité. Avec un mainframe Z toujours bien présent.
« Nous avons des IA débiles que l’on rend utiles quand on les connecte bien » expliquait en juin dernier Luc Julia lors d’une Master Classe organisée par AI Builders. L’histoire ne dit pas si IBM trouve aussi les IA si débiles, mais l’éditeur s’est clairement aligné sur la seconde partie de la phrase. Avec une volonté affichée, celle de démocratiser l’accès aux lakehouses de données et d’orchestrer efficacement et simplement l’univers d’agents IA qui exploite et manipule la donnée. Le focus de ce TechXchange 2025 était clairement la data et l’IA agentique, non pas comme deux entités différentes mais comme deux composantes intrinsèquement liées. Pas étonnant que l’essentiel des annonces et démonstrations aient, dès lors, tourner autour de watsonx.data et de watsonx.orchestrate…
Démocratiser l’accès aux lakehouses
Ce n’est pas une surprise, IBM a fait de watsonx.data l’un des piliers centraux de sa stratégie pour industrialiser l’IA en entreprise. Ce qui est en revanche plus surprenant, c’est l’annonce du lancement d’une version gratuite et locale de la solution.
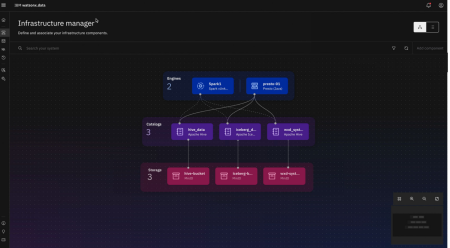
watsonx.data Developer Edition se destine aux développeurs, data engineers et data scientists. Cette édition gratuite permet de monter rapidement un environnement “lakehouse” complet, intégrant des moteurs comme Spark ou Presto, avec des jeux de données d’exemple, le support du format de table Apache Iceberg, et l’intégration avec watsonx.ai pour les flux de travail IA, le tout sans dépendance au cloud ni licence temporelle. On y retrouve une prise en charge unifiée des données structurées et non structurées, avec des enrichissements sémantiques, l’intégration de documents, l’extraction d’entités, la vectorisation, etc. Cette édition DEV est conçue pour faciliter le prototypage, tester des idées, et préparer une montée en production sans couture vers les versions d’entreprise.
Parallèlement, l’édition complète de watsonx.data s’enrichit du récent rachat de DataStax pour étendre son champ aux workloads opérationnels hyper-rapides et aux applications temps-réel.
Parallèlement, l’intégration OEM avec Unstructured.io s’attaque à la réalité désordonnée des documents d’entreprise, créant des pipelines robustes du chaos de connaissances internes au contexte prêt pour l’IA. Cette intégration est cruciale car moins de 1% des données d’entreprise sont actuellement utilisées pour des initiatives d’IA générative, et 90% des données d’entreprise sont non structurées et dispersées dans des emplacements divers. IBM affirme que cette intégration permet des applications d’IA générative 40% plus précises et performantes.
Enfin, IBM annonce des capacités de données agentiques pour watsonx.data qui utilisent les LLM pour simplifier la création de pipelines de données, éliminant la friction des flux de travail et la prolifération d’outils. Le système peut automatiser la découverte de données et le lignage, transformant les informations brutes en IA précise à travers les environnements sur site et cloud.
Plus que jamais, watsonx.data répond à une approche “data-first” pour toutes les entreprises en quête d’une infrastructure de données ouverte, hybride, performante et gouvernée pour servir de base fiable à l’IA.
L’IA Agentique : de l’Expérimentation à la Gouvernance
En 2025, quand on parle d’IA on parle forcément d’IA agentique. Et IBM n’a pas dérogé à la règle. Son « watsonx.orchestrate » était la vraie star de cette conférence alors que dans le même temps Google Cloud lançait de son côté son « Gemini Enterprise » visant également à orchestrer les agents IA.
Orchestrate est le moteur central d’IBM pour déployer des agents à l’échelle, orchester l’automatisation de processus métiers complexes et interconnecter données, systèmes et modèles. IBM annonce l’arrivée de nouvelles capacités pour Orchestrate, visant à renforcer les workflows agentiques et les agents métiers (domain agents) prêts à l’usage.
Le catalogue d’Orchestrate, déjà riche de 500 agents et outils agentiques, s’étend avec des agents pour les domaines de la vente (sales) et des achats (procurement), désormais livrés « prêts à l’emploi ».
Parallèlement, IBM souligne la disponibilité générale de l’Agent Builder et du Flow Builder, des environnements no-code permettant aux utilisateurs métiers de concevoir ou personnaliser leurs agents et workflows en quelques minutes.
Parallèlement, les workflows agentiques sont désormais disponibles en disponibilité générale, permettant aux développeurs de créer des processus standardisés et réutilisables pour séquencer plusieurs agents et outils. Cette approche remplace les scripts fragiles par une orchestration durable de niveau entreprise.
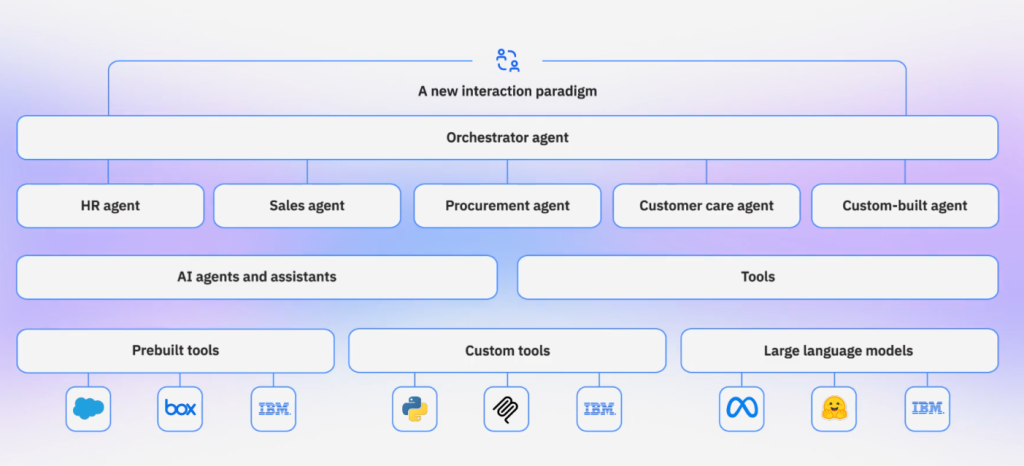
Mais la nouveauté majeure s’appelle AgentOps ! Décrit comme le « contrôle aérien pour les systèmes IA autonomes », AgentOps fournit une visibilité de bout en bout et une gouvernance pour les agents IA en environnements de test et de production, créant des pistes d’audit pour chaque comportement d’agent, de la sollicitation au résultat. Autrement dit, cette couche de gouvernance et d’observabilité, intégrée au cœur même de watsonx Orchestrate, agit comme un « enregistreur de bord » pour les agents IA, traçant les logs d’action, les appels d’API, et les métadonnées de décision, afin de rendre les comportements agentiques auditable et contrôlable. En cas de dérive ou d’erreur, il devient possible de revenir en arrière (rollback) sur des actions d’agent avec une granularité proche de celle du code logiciel.
Autre nouveauté importante, IBM annonce l’intégration de Langflow dans watsonx Orchestrate. Désormais très populaire, Langflow est un environnement open source visuel qui permet de concevoir, tester et orchestrer des flux d’agents et d’applications d’IA générative sans coder à l’aide d’une interface visuelle de type « glisser-déposer ». Cette démocratisation de la création d’agents réduit les temps de construction de plusieurs heures à quelques minutes, permettant aux équipes métier de participer directement à l’automatisation de leurs processus.
Project Infragraph ou le contrôle infrastructurel à l’IA
Lors de TechXchange 2025, IBM a levé le voile sur Project Infragraph, né du rachat de HashiCorp. Infragraph concrétise la vision d’IBM d’un plan de contrôle unifié et intelligent pour l’observabilité de l’infrastructure. Ce système transforme les métadonnées d’infrastructure en un graphe de connaissances unifié et interrogeable, offrant une vue en temps quasi réel des ressources d’infrastructure et de la posture de sécurité à travers les environnements hybrides et multi-cloud.

L’idée centrale : remplacer les outils fragmentés et les processus manuels par un plan de contrôle intelligent unique, capable d’offrir une vue relationnelle en temps réel de toute l’infrastructure : ressources, applications, services, configurations, propriétés, contexte de sécurité. Au lieu de maintenir des dizaines d’outils distincts avec leurs propres vues sur l’infrastructure, les équipes obtiennent une source unique de vérité qui connecte tous les composants d’infrastructure sous un modèle de données et de politique cohérent.
Les utilisateurs pourront ainsi interroger le graphe, explorer en profondeur les clusters, identifier des ressources vulnérables en temps quasi réel et visualiser les relations entre l’état opérationnel d’un composant, son contexte (dépendances, environnement, exposition réseau, politiques appliquées) et l’équipe responsable de sa gestion.
Un exemple pratique : lorsqu’une vulnérabilité critique (CVE) émerge, Infragraph fournit instantanément une vue complète pour identifier les composants affectés, vérifier la remédiation et visualiser l’exposition à travers les clusters de ressources (par exemple, les conteneurs au sein d’un VPC), réduisant considérablement le temps moyen d’évaluation et de résolution des risques.
Le projet sera livré en version bêta privée en décembre 2025 via la HashiCorp Cloud Platform (HCP), avec des plans d’intégration futurs avec Red Hat Ansible, OpenShift, watsonx Orchestrate, IBM Concert, Turbonomic et Cloudability.
IBM veut en effet ainsi offrir un écosystème unifié où l’infrastructure, la sécurité et les applications opèrent sous un modèle cohérent. Pour IBM, InfraGraph est la condition sine-qua-non pour permettre aux agents IA de fonctionner en toute sécurité et de manière autonome avec une compréhension complète du contexte. C’est la fondation qui rend possible des agents IA “agentiques” capables de raisonner sur l’infrastructure, proposer des runbooks ou déclencher des actions automatisées tout en gardant contrôle, auditabilité et sécurité.
Project BOB : le refactoring par l’IA
Autre annonce majeure et particulièrement remarquée, Project BOB est un ambitieux assistant IA de développement conçu pour révolutionner l’ingénierie logicielle et métamorphoser les pratiques de refactoring de logiciels.
Project BOB constitue tout un environnement de développement (avec un IDE complet) orienté « IA-First » qui insuffle l’IA sur l’ensemble du cycle de développement logiciel.
BOB n’est pas juste un outil de suggestion de code : il est pensé pour comprendre l’intention du développeur, le contexte du dépôt et les contraintes de sécurité et conformité du système. BOB peut générer, tester, refactoriser, moderniser et sécuriser du code de manière autonome ! Une de ses fonctions phares, le « literate programming », permet d’énoncer des modifications souhaitées en langage naturel que Bob traduit en modifications de code.
Dit autrement, BOB opère sur tout le cycle du logiciel, depuis l’écriture et le débogage jusqu’aux tests, à la sécurité, au CI/CD et au déploiement. La solution coordonne plusieurs LLM, comme Anthropic Claude, Mistral Medium, Meta Llama et IBM Granite, en sélectionnant les capacités appropriées au contexte de la tâche tout en maintenant la continuité entre les sessions.
IBM affirme que plus de 6 000 développeurs l’utilisent déjà en interne, avec des gains de productivité moyens de 45 %, une augmentation de 22 à 43% des commits de code, et des économies de temps de 90% sur des tâches comme la génération de tests et les mises à jour de dépendances. Plus révélateur encore, 95% des premiers utilisateurs ont employé Bob pour l’accomplissement complet de tâches plutôt que pour la simple génération de code.
BOB prend en charge la modernisation Java de bout en bout, avec des mises à niveau automatisées, des migrations de frameworks et des refactorisations multi-étapes sur des monolithes et services distribués. Mais ce n’est pas tout. BOB est aussi doué pour aider à moderniser les applications Mainframe Z et IBM i. Le système est optimisé pour les langages courants tels que Java, JavaScript/TypeScript et Python, avec un support prévu pour d’autres langages prochainement.
Enfin, Project BOB intègre également toutes les problématiques de sécurité avec des pratiques DevSecOps natives comme la détection de vulnérabilités, les vérifications de conformité et les analyses de sécurité directement dans l’IDE.
Granite 4.0, petits mais costauds
Au fil des années, IBM a considérablement renforcé sa famille de modèles, légers et en open-weight, Granite. Ces modèles égalent ou surpassent des modèles de taille similaire de fournisseurs concurrents tout en offrant une efficacité de coût 3x à 23x supérieure aux grands modèles frontières dans les preuves de concept.

Lors de TechXchange, IBM a inauguré une nouvelle génération. Les modèles Granite 4.0 sont des modèles hybrides (combinant Mamba et transformeurs) qui réduisent drastiquement les besoins en mémoire tout en maintenant des performances élevées — jusqu’à 70 % de gain mémoire dans certains scénarios. Ces modèles sont désormais disponibles sur watsonx.ai et via de nombreux partenaires (Dell, Hugging Face, Docker, etc.).
De plus, Granite 4.0 est la première famille de modèles ouverts à obtenir la certification ISO 42001, et les checkpoints sont signés cryptographiquement pour garantir leur provenance.
Au-delà du modèle lui-même, IBM a annoncé que sa famille Granite participe désormais activement à des produits majeurs présentés à l’événement. Par exemple, Project Bob, l’IDE IA d’IBM en préversion, s’appuie sur Granite (aux côtés d’autres modèles) pour automatiser tâches, revue de code et modernisation logicielle. Par ailleurs, pour les environnements mainframe, watsonx Assistant for Z supportera des modèles Granite, permettant l’inférence faible latence directement sur IBM.
Spyre est enfin là !
Et puisque l’on parle des mainframes, IBM a officiellement lancé son très attendu accélérateur Spyre. Pourquoi très attendu ? Parce qu’il est le moteur IA optionnel promis par IBM pour insuffler la puissance IA à ses mainframes Z17 et ses serveurs Power11.

Chaque Spyre embarque un SoC de 5 nm intégrant 32 cœurs spécialisés (25,6 milliards de transistors) conçu pour exécuter des modèles génératifs et agents IA proches des données. Chaque Spyre est pensé pour fonctionner en cluster avec d’autres cartes Spyre. Ainsi, une configuration de 8 cartes Spyre offre 1 To de mémoire, 1,6 TB/sec de bande passante mémoire et plus de 2,4 Pétaops de performance (soit 2400 TOPS).
Les systèmes Z ou LinuxONE pourront embarquer jusqu’à 48 cartes Spyre (via PCIe), tandis que les serveurs Power11 seront limités à 16 cartes Spyre. Selon IBM, grâce à Spyre, la plateforme IBM Z peut traiter jusqu’à 450 millions d’opérations d’inférence par jour en utilisant plusieurs modèles IA simultanément.
IBM prévoit une disponibilité générale (GA) le 28 octobre 2025 pour les plateformes z17 et LinuxONE 5, et un déploiement pour Power11 début décembre. Spyre vise à permettre aux entreprises de garder leurs modèles et inférences sur site, notamment pour des usages sensibles (fraude, conformité, support), sans devoir externaliser les données.
Les outils logiciels de la gamme IBM (watsonx Assistant for Z, AI Toolkit pour IBM Z / LinuxONE, Machine Learning for z/OS) ainsi que les modèles Granite 4.0 seront optimisés pour tirer parti de l’accélération Spyre.
Derrière le feu d’artifice d’innovations, IBM a finalement profité de son TechXchange 2025 pour éclairer sa vision où l’IA agentique ne vaudra que ce que vaudra la discipline de la donnée et la gouvernance opérationnelle qui l’encadrent. Le pari stratégique est celui d’une « autonomie gouvernée » : des agents capables d’agir sur des systèmes critiques, mais tenus par des plans de contrôle, des graphes de connaissance d’infrastructure, des modèles ouverts et traçables, et une exécution au plus près des données, y compris sur mainframe. Dit autrement, IBM ne veut pas se contenter de vendre les briques de l’ère agentique mais tente d’ériger l’échafaudage qui empêche la maison IA de s’écrouler quand on passe du POC à la mise en production. Aux DSI, maintenant, d’installer ces fondations mais également la culture qui l’accompagne pour permettre à cette autonomie agentique sous contrôle de délivrer ses promesses, sans transiger sur la sécurité, la traçabilité et la souveraineté.
À LIRE AUSSI :










