


Data / IA
IBM THINK 2025 : ce que les DSI doivent en retenir…
Par Laurent Delattre, publié le 12 mai 2025
À l’occasion de son évènement international IBM Think 2025, l’éditeur s’est évertué à mettre l’IA à l’épreuve de l’échelle industrielle : agents autonomes, gouvernance des données, vectorisation et infrastructures sécurisées s’imbriquent pour passer du POC à la production. Voici ce qu’il faut retenir des annonces d’IBM…
Sans surprise, puisque la thématique monopolise toutes les conférences IT depuis deux ans, IBM a fait de Think 2025 une grande conférence sur l’IA et cherché à en faire une démonstration de maturité industrielle de l’IA. Dès la keynote, le PDG Arvind Krishna a posé le diagnostic : « L’ère de l’expérimentation en matière d’IA est terminée ; l’avantage concurrentiel vient désormais d’intégrations ciblées capables de produire des résultats business mesurables ».
Dit autrement, si vous n’êtes pas encore à l’heure des déploiements en production, vous avez un problème.
« Nous nous préparons à voir naître plus d’un milliard de nouvelles applications génératives au cours des quatre prochaines années » explique le CEO du groupe. Tout en rappelant néanmoins que seuls 25 % des projets IA délivrent pour l’instant le ROI attendu, les DSI luttant contre l’enchevêtrement de données, de modèles en perpétuelles évolutions, d’APIs et de clouds.
À Think 2025, toute la promesse d’IBM consiste donc à aider les entreprises à passer du concept de l’IA à la création de valeur, grâce à une plateforme « watsonx » unifiée mêlant outils de gestion du cycle de vie des IA, modèles spécialisés, gouvernance et même infrastructure hybride.
Voici ce qu’il faut retenir des principales annonces de cette édition 2025 d’IBM Think.
L’IA à l’ère agentique
C’est la star de cet IBM Think 2025 et la pierre angulaire de la stratégie IA de l’éditeur : watsonx Orchestrate ! Au centre de toutes les attentions, la solution évolue pour aider les entreprises à franchir la frontière qui sépare le simple assistant conversationnel de l’« agent » autonome, capable d’agir et de coopérer. « Vous pouvez désormais bâtir votre propre agent d’entreprise en moins de cinq minutes » promet Arvind Krishna en présentant le nouvel Agent Builder de watsonx Orchestrate, un studio no‑code mais extensible jusqu’au pro‑code qui assure que cette célérité ne sacrifie rien à la gouvernance.
Autre nouveauté, un catalogue « Agent Catalog » réunit, au cœur de watsonx Orchestrate, plus de 150 agents préconfigurés et outils prêts à l’emploi (RH, ventes, achats, …), interconnectés à plus de 80 applications tierces, telles que Microsoft, Oracle, Adobe, Salesforce, ServiceNow ou Workday. Ces agents sont proposés par IBM et par ses partenaires.
Pour les processus critiques, IBM propose et développe également des Domain Agents spécialisés : les HR Agents automatisent la gestion des congés et des avantages en s’appuyant sur Workday HCM, les Procurement Agents orchestrent procure‑to‑pay et qualification fournisseur via Coupa ou Dun & Bradstreet, tandis que les Sales Agents synchronisent prospection et « enablement » dans Salesforce et Seismic. IBM a annoncé préparer d’autres « Domain Agents » pour le support (Custom care), la finance, etc. L’éditeur prépare aussi des « Utility Agents » pour la recherche Web, les calculs mathématiques formels, etc.
La plateforme watsonx Orchestrate introduit surtout deux briques techniques attendues des DSI : l’orchestration multi‑agents (M-A Orchestration), qui répartit dynamiquement et coordonne les tâches complexes entre plusieurs agents, et l’observabilité intégrée (Agent Observability) pour tracer, gouverner et optimiser chaque exécution IA.
« Les agents vont redéfinir la manière de construire les applications ; ils doivent évoluer sans couture dans le maillage de données et de systèmes d’une DSI moderne », insiste Arvind Krishna.
Sous le capot, IBM standardise la communication grâce aux protocoles MCP (le protocole de connexion aux sources inventé par Anthropic et devenu standard de fait depuis son adoption par OpenAI et Google) et ACP (le protocole open source destiné à permettre la communication entre agents intelligents autonomes qui a été créé par IBM et BeeAI, qui est concurrent du A2A de Google, et qui privilégie la prédictibilité sur la flexibilité avec son approche centralisée façon Broker).
IBM a également lancé pour watsonx Orchestrate un nouveau kit de développement Agent SDK pour créer des agents maison.
Objectif affiché de ce foisonnement d’annonces : accélérer dans les entreprises le passage du POC à la production en automatisant de bout en bout la prospection, l’onboarding fournisseurs ou le support employé, tout en plaçant gouvernance et sécurité au cœur des workflows.
Libérer la donnée pour l’IA
Le principal frein à l’IA en entreprise reste la donnée elle‑même – trop souvent éclatée, non structurée, inaccessible. « Nous sommes à un point d’inflexion : les entreprises ont besoin de modèles non seulement puissants, mais aussi efficaces, personnalisés et responsables », rappelle Dinesh Nirmal, vice‑président Produits IBM Software.
Pour Edward Calvesbert, chef produit de watsonx.data, la clé est limpide : « Si tout le monde utilise les mêmes modèles entraînés sur les mêmes corpus publics, comment se différencier ? L’avantage vient de l’exploitation de vos propres données d’entreprise ; sans elles, vous ne vous démarquerez pas ! »
Et pour simplifier cette fusion entre l’IA et les données de l’entreprise, la nouvelle version de watsonx.data fait donc sa mue en lakehouse hybride et ouvert, séparant calcul et stockage, adoptant Iceberg et Presto, et intégrant nativement la gouvernance et la traçabilité d’une data fabric.
Deux modules autonomes complètent l’ensemble : watsonx.data integration, un guichet unique pour orchestrer pipelines et formats, et watsonx.data intelligence, qui emploie l’IA pour extraire des insights dans les contrats, mails ou présentations. Selon IBM, l’intégration étroite des données d’entreprise (structurées et surtout non structurées) dans le pipeline RAG permet de mieux “ancrer” les générations de réponse dans la réalité métier : plus de bonnes réponses, moins de flous, et donc un gain mesurable d’efficacité pour les agents IA qui en dépendent. Cette intégration améliorerait la précision des modèles RAG de 40 %.
Parallèlement, pour abattre les murs applicatifs, IBM a dévoilé webMethods Hybrid Integration, une couche unifiée qui fédère APIs, files, events et partenaires B2B dans les environnements multi‑cloud. Selon Forrester, une telle solution promet 176 % de ROI sur trois ans et 67 % de gain de temps sur les projets simples.
Enfin, Db2 est toujours bien vivant et sa version « 12.1.2 » devient « vector‑ready » : embeddings natifs, recherche de similarité, table Iceberg CRUD… Db2 se met à l’IA ! Le SGBD va même jusqu’à intégrer un Database Assistant en langage naturel pour guider les DBAs.
Le tout s’imbrique dans watsonx.data afin que les workloads transactionnels participent aux pipelines génératifs sans déplacer les données.
Pour terminer, signalons que l’acquisition annoncée de DataStax doit apporter un moteur NoSQL et la recherche vectorielle à grande échelle à tout l’univers watsonx.data.
En dotant sa plateforme de données d’un tissu d’intégration, de capacités vectorielles et d’une gouvernance de bout en bout, IBM entend transformer le « poids mort » que représentent les 90 % de données non structurées en véritable carburant pour l’IA agentique et générative des DSI.
Une infrastructure mainframe taillée pour l’IA
Et IBM entend profiter de cette révolution de l’IA pour recaser des mainframes spécialisés dans ce domaine. Après tout, les mainframes sont des architectures avec des bandes passantes fabuleuses et particulièrement utiles à l’IA.
À peine deux semaines après avoir lancé son tout nouveau « z17 », IBM le décline déjà en un « mainframe Linux » spécialement pensé et conçu pour les besoins croissants en matière d’intelligence artificielle, de sécurité et de durabilité : le LinuxONE Emperor 5.

« LinuxONE Emperor 5 peut traiter jusqu’à 450 milliards d’opérations d’inférence par jour tout en offrant un chiffrement post‑quantique, » affirme ainsi le constructeur. Le système combine le NPU embarqué dans les CPU Telum II qui l’anime, les cartes accélératrices IA « Spyre » d’IBM (la machine peut en accueillir 48), les technologies de conteneurs confidentiels et une consommation annoncée 44 % plus basse que l’équivalent x86 sur cinq ans. Associé à Red Hat OpenShift et aux GPU AMD/NVIDIA supportés dans Fusion HCI, LinuxONE Emperor 5 vise tout particulièrement les charges d’inférence massives en environnement hautement sécurisé, de la détection de fraude en temps réel à l’analyse bancaire réglementaire.
Informatique générative et quantique
Pas d’évènement IBM Think sans une plongée futuriste avec IBM Research. Les chercheurs du groupe préparent « le generative computing », autrement dit l’informatique générative. Pour IBM, ce « Generative Computing » est présenté comme la prochaine évolution de l’IA en entreprise. « Un LLM est désormais un véritable environnement de calcul », explique Sriram Raghavan, VP IA, avant de préciser : « Le generative computing permet de passer du prompt à la programmation réelle ». Aujourd’hui, l’interaction se fait par prompt engineering : un texte libre envoyé à l’API du modèle. Cette méthode est jugée brute, non portable et difficile à sécuriser. Et Sriram Raghavan d’alerter : « Nous allons voir fleurir des livres entiers de prompts, une situation intenable » . Pour des DSI soumises à des exigences de traçabilité, d’audit et de performance, il faut des interfaces plus robustes. Avec le « Generative Computing », IBM propose de remplacer l’API traditionnelle par un runtime dédié, doté d’abstractions de programmation : Appels structurés décrivant explicitement la tâche et les contraintes ; Vérifications automatiques contre hallucination, biais et prompt injection ; Adaptateurs bien entraînés pour appliquer des contrôles de sécurité à l’exécution.
Concrètement, un nouveau runtime « Granite » va s’intercaler entre l’application et le modèle. Il sera chargé d’orchestrer la génération, d’appliquer les garde‑fous et de fournir un format commun pour changer de modèle sans réécrire le code ! Ce Granite Runtime va faire sa première apparition cet été avec la nouvelle famille de modèles Granite 4.0, qui comportera une variante assez compacte pour tenir sur un GPU grand public. Les premiers tests montrent une inférence 2 à 5 fois plus rapide que les transformers équivalents.
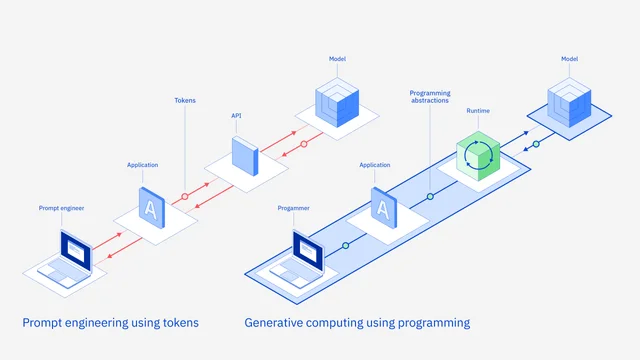
Pour IBM Research, le Generative Computing transforme le LLM en composant logiciel contrôlable, gouverné et interchangeable, une étape nécessaire pour faire de l’IA générative un socle industriel plutôt qu’un simple gadget de conversation.
Parallèlement, IBM Research poursuit son exploration scientifique de l’informatique quantique. Jay Gambetta, VP Quantum, affirme ainsi : « Nous pensons que l’avantage quantique deviendra réalité en 2026. »
Pour y parvenir, l’entreprise mise sur le Quantum System II, ordinateur modulaire lancé l’an dernier, conçu pour encaisser la correction d’erreurs et rester opérationnel un an sans recalibrage des réglages. Il se veut accessible « comme un serveur ordinaire via une simple API ».

IBM revendique déjà 75 machines quantiques construites, dont treize en libre accès cloud, et plus de 250 partenaires industriels ou académiques qui testent des cas d’usage en chimie des matériaux, optimisation financière ou recherche pharmaceutique. Sur le plan algorithmique, la démonstration du procédé sample‑based quantum diagonalization réalisée avec RIKEN a permis de simuler l’état fondamental d’un complexe [4Fe‑4S] de 77 qubits, au‑delà des limites du calcul classique, preuve que le « quantum‑centric supercomputing » (alliance hybride des supercalculateurs HPC et des qubits) est déjà à l’œuvre. IBM prévoit de concrétiser ces avancées d’abord en chimie et matériaux, puis en optimisation, avant d’aborder d’autres problématiques scientifiques, et prépare activement la génération de processeurs Starling attendue pour 2029. Avec un objectif : franchir, d’ici 2029, le cap du calcul quantique tolérant aux fautes, c’est‑à‑dire disposer de processeurs capables d’exécuter des qubits logiques auto‑corrigés et donc d’enchaîner des calculs industriels sans que la décohérence ne vienne invalider le résultat.
Bref, ce Think 2025 aura marqué une étape importante dans l’industrialisation de l’IA chez IBM et ses clients. « Ce moment IA n’est pas une évolution incrémentale : il transforme fondamentalement le business » avertit ainsi Arvind Krishna. Selon lui, l’économie chahutée et les manque de perspectives géopolitiques n’entament pas l’appétit des entreprises : « Tout le monde double la mise sur l’IA, mais recherche désormais un retour sur investissement tangible. »
Les défis restent néanmoins lourds : coûts, gouvernance, rareté des talents… Mais le message est bien reçu : l’IA agentique, soutenue par une donnée unifiée et une infrastructure sécurisée, devient l’outil stratégique pour traverser la crise, gagner en efficacité et préparer les ruptures de demain. Et des ruptures, il va y en avoir de nombreuses… mais ça, ça sera pour un prochain IBM Think !
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











