


Data / IA
IBM Think 2026 : passer des copilotes à l’IA qui fait tourner l’entreprise
Par Thierry Derouet, publié le 06 mai 2026
À Think 2026, IBM ne promet pas de gagner la guerre du meilleur modèle d’IA. Big Blue défend une autre bataille, moins spectaculaire mais plus décisive pour les DSI : celle de l’industrialisation. Données temps réel, orchestration d’agents, sécurité applicative, mainframe, cloud hybride et souveraineté : IBM veut devenir le chef d’orchestre de l’IA d’entreprise.
Il y a dans le discours d’IBM une forme de retour au réel. Dans une industrie qui s’épuise parfois à comparer les modèles comme on comparerait des moteurs de Formule 1, Arvind Krishna, le CEO d’IBM, ramène l’IA dans l’atelier. Pas dans la démonstration. Pas dans le chatbot. Dans les processus, les données, les infrastructures, les vieux systèmes, les contraintes de conformité et les organisations qui ne se réécrivent pas d’un clic.
À l’occasion de Think 2026, le CEO d’IBM et Rob Thomas, Senior Vice President Software et Chief Commercial Officer, ont défendu une thèse simple : l’IA d’entreprise sort de l’âge des pilotes pour entrer dans celui de l’exploitation à grande échelle. « L’IA est bien une affaire de productivité », résume Arvind Krishna. Mais, selon lui, le sujet ne s’arrête pas à l’efficacité opérationnelle. Les entreprises qui réussiront devront transformer ces gains en nouveaux revenus et en nouveaux modèles économiques.
La phrase centrale du briefing est peut-être ailleurs : « Il faut agir là où se trouvent les données. Or plus de 70 % des données restent encore dans l’entreprise, dans des systèmes centraux et essentiels pour elle. » C’est là que se loge la différence IBM. Là où d’autres acteurs partent du cloud, du modèle ou de l’interface, Big Blue part du SI réel. Celui qui contient encore le mainframe, les applications critiques historiques et actuelles, les données réglementées, les environnements hybrides, les processus qu’il faut automatiser sans les casser.
L’IA ne sera pas une collection de copilotes
IBM appelle cela un « modèle opérationnel de l’IA ». La formule pourrait sembler sortie d’un manuel de consultant. Elle traduit pourtant une intuition juste : l’IA d’entreprise ne pourra pas être administrée comme une succession de copilotes posés sur les métiers. Elle devra être exploitée comme un système critique. Un discours qui fait écho aux derniers conseils du Gartner pour contrôler la prolifération agentique et au CIO Compass de Sopra Steria Next sur la fin de la GenAI Spectacle.
Rob Thomas utilise une image éclairante. L’électricité, rappelle-t-il, a d’abord apporté l’ampoule dans les usines. C’était utile. Cela améliorait la sécurité. Cela permettait de travailler autrement. Mais la vraie rupture est venue plus tard, lorsque l’électricité a alimenté les moteurs et rendu possible la chaîne de montage. « Aujourd’hui, beaucoup d’usages de l’IA en entreprise relèvent encore de l’ampoule : résumés d’e-mails, création de documents, préparation de réunions. C’est utile, mais cela ne redéfinit pas réellement la manière dont l’entreprise fonctionne. »
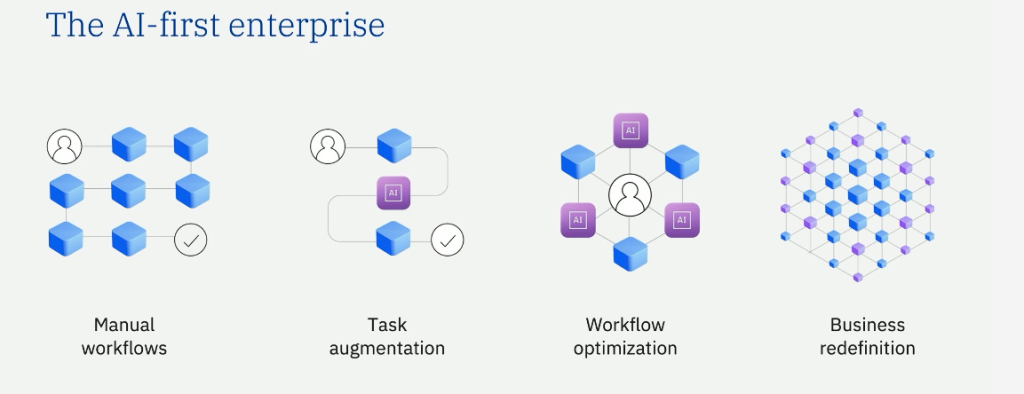
Cette analogie donne la clé de lecture de Think 2026. IBM ne veut plus parler seulement d’outils d’assistance. Il veut parler d’IA appliquée aux processus de bout en bout : achats, ressources humaines, comptes fournisseurs, conformité, développement logiciel, remédiation de vulnérabilités, exploitation des infrastructures hybrides. En clair, l’IA qui cesse d’éclairer le poste de travail pour entrer dans la mécanique de l’entreprise.
Cette ligne prolonge ce qu’IBM avait déjà commencé à raconter lors de Think 2025. À l’époque, Big Blue insistait déjà sur le passage du POC à la production, avec des agents autonomes, une gouvernance des données et des infrastructures sécurisées. Think 2026 ajoute une doctrine plus explicite : les briques ne suffisent plus, il faut un modèle d’exploitation complet.
Watsonx Orchestrate, ou la peur du désordre agentique
La première brique de cette stratégie est watsonx Orchestrate. IBM ne le présente plus seulement comme une plateforme d’agents, mais comme un plan de contrôle. L’enjeu n’est plus seulement de créer un agent, mais de gouverner des centaines, puis des milliers d’agents issus de plusieurs fournisseurs, développés par plusieurs équipes, connectés à plusieurs systèmes et capables d’agir dans des environnements sensibles.
Rob Thomas le dit sans ambiguïté : « Orchestrate n’est plus seulement une technologie IBM. Il s’agit d’accueillir la meilleure technologie agentique, quelle que soit son origine. » Il cite notamment ServiceNow, Salesforce ou Adobe parmi les partenaires dont les agents peuvent rejoindre l’écosystème. La promesse consiste donc à fédérer les agents plutôt qu’à enfermer l’entreprise dans un seul modèle ou un seul éditeur.
Cette évolution résonne fortement avec les débats ouverts récemment autour de l’IA agentique. Nous l’écrivions à propos des SaaS, CRM et ERP à l’heure des agents : l’agent IA ne veut plus seulement assister l’utilisateur, il veut accéder aux capacités des applications, appeler des API, manipuler des workflows, déclencher des actions. Mais si les agents traversent les applications, une question devient centrale : qui les gouverne ? Qui contrôle leurs droits ? Qui observe leurs actions ? Qui en porte la responsabilité ?
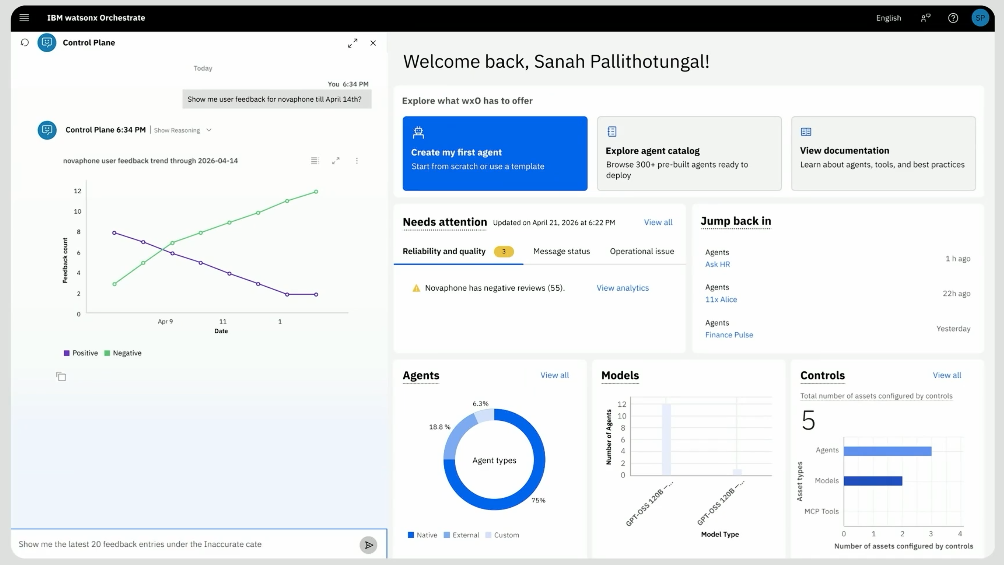
Sur ce terrain, IBM n’est pas seul. Microsoft positionne Agent 365, officiellement en disponibilité générale depuis la fin avril, comme un plan de contrôle des agents, capable d’observer, gouverner et sécuriser des agents Microsoft, SaaS, locaux ou issus d’autres clouds. Google Cloud a présenté à Next 2026 une vision très ambitieuse de l’entreprise agentique en production (Gemini Enterprise Agent Platform), soutenue par une infrastructure pensée pour industrialiser des flottes d’agents. OpenAI avance également vers les cockpits d’orchestration de l’IA agentique avec sa solution Frontier. AWS, avec Bedrock AgentCore, adopte une approche plus modulaire et infrastructurelle : n’importe quel framework, n’importe quel modèle, mais avec des services de runtime, mémoire, identité, politique, registre et observabilité pour passer en production. Mistral, avec Workflows, insiste sur les validations humaines, la traçabilité et la reprise sur incident. Tous promettent donc l’ouverture. Mais chacun l’organise autour de son propre centre de gravité.
IBM prend le même virage, mais depuis son territoire historique : l’hybride, le legacy, le mainframe, la conformité et les grands comptes.
IBM ne fuit pas la guerre des modèles, il la contourne
Le point le plus révélateur du briefing est peut-être l’aveu stratégique d’Arvind Krishna : « IBM ne construit pas de modèles fondation. Nous travaillons avec la plupart des fournisseurs de modèles, dont Anthropic et OpenAI. » Dans une industrie obsédée par la hiérarchie des modèles, IBM assume une place différente. L’entreprise ne cherche pas à être l’OpenAI des grands comptes. Elle veut être l’acteur qui choisit, combine, gouverne et optimise les modèles selon les usages.
C’est une manière élégante de sortir d’une bataille qu’IBM n’a pas vocation à gagner seule. La course aux modèles impose des niveaux de capex considérables, dominés par les hyperscalers et les grands laboratoires d’IA. IBM préfère jouer une autre carte : grands modèles propriétaires lorsque c’est nécessaire, modèles plus petits lorsqu’ils suffisent, modèles open weight comme Llama ou Mistral lorsque le contexte s’y prête, modèles IBM Granite lorsqu’ils répondent au besoin, et déploiement on-premises lorsque l’environnement l’exige.
Cette approche répond à une question que les DSI connaissent déjà : le meilleur modèle n’est pas toujours le bon modèle. Le bon modèle est celui qui répond au bon usage, au bon coût, avec le bon niveau de confidentialité, de performance, de souveraineté et de contrôle. À l’heure où OpenAI relance la bataille de l’IA agentique avec GPT-5.5, IBM déplace donc la discussion. L’unité de décision n’est plus seulement le modèle. Elle devient le processus.
Bob, Concert et le retour brutal du DevSecOps
Avec IBM Bob, Big Blue veut aussi installer l’IA agentique dans le développement logiciel. Bob est présenté comme un partenaire de développement conçu pour l’entreprise, multi-modèle, compatible cloud et on-premises, avec des capacités de contrôle des coûts. IBM affirme l’avoir déployé en interne auprès de plus de 80 000 utilisateurs, avec des gains déclarés de productivité de 45 %.
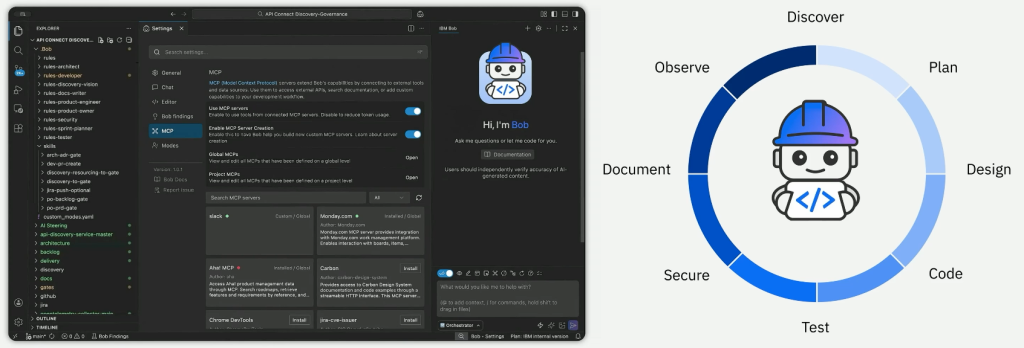
Mais l’annonce la plus intéressante n’est pas seulement dans la génération de code. Elle est dans l’intégration avec Concert Secure Coder, qui doit identifier les vulnérabilités, proposer un plan de remédiation, appliquer des correctifs, vérifier le résultat et générer une pull request. L’idée est séduisante : transformer les arriérés de sécurité, souvent traités en mode pompier, en chaîne de remédiation gouvernée et mesurable. Concert Secure Coder est disponible en préversion publique, dans IBM Bob et dans VS Code. Il identifie et priorise les risques pendant l’écriture du code. Il sait générer des remédiations automatiques pour corriger du code vulnérable mais il sait aussi patcher OS, middlewares, packages et images.
Les deux produits sont complémentaires : Bob est le copilote/partenaire agentique de développement ; Concert Secure Coder est la brique de sécurisation continue qui s’insère dans le flux de développement et remonte les risques dans Concert. Dit autrement, Bob fabrique, transforme et orchestre le logiciel ; Concert Secure Coder sécurise ce que Bob et les développeurs produisent. Bob accélère le mouvement. Secure Coder évite que cette accélération se transforme en dette de sécurité.
Reste la question que tout DSI ou RSSI posera immédiatement : que se passe-t-il si un agent corrige mal ? Si un patch introduit une faille logique ? Si une remédiation provoque une panne ? Rob Thomas prend soin de borner la promesse : « Aujourd’hui, rien n’est complètement sans intervention humaine. Concert est utilisé comme une augmentation. » L’outil peut identifier, proposer, préparer. Mais la boucle humaine demeure.
Ce détail est essentiel. Dans les environnements critiques, l’humain dans la boucle n’est pas un archaïsme. Il est encore la condition d’acceptabilité de l’automatisation. IBM a compris que l’agentique ne se déploiera pas durablement si elle donne le sentiment de déplacer la responsabilité dans une boîte noire.
Le sujet rejoint aussi celui du mainframe. Avec IBM Bob Premium for Z, IBM étend sa logique d’assistance au développement aux environnements Z. Face à l’emballement récent autour des outils de modernisation du COBOL, notamment après les annonces d’Anthropic que nous analysions dans COBOL, IA et affolement boursier, IBM adopte une position défensive mais cohérente. Rob Thomas le rappelle : « La valeur n’est pas seulement dans le code COBOL lui-même. Elle est dans la logique métier qu’il contient. »
Autrement dit : moderniser, oui. Réécrire à l’aveugle, non. Ce message s’inscrit dans la continuité du lancement du mainframe IBM Z17, où Big Blue défendait déjà l’idée que le mainframe n’est pas un vestige, mais une plateforme de résilience, de transaction et désormais d’IA.
Sans donnée temps réel, pas d’agent fiable
Le troisième pilier de Think 2026 est la donnée. IBM vient de finaliser l’acquisition de Confluent et veut intégrer Kafka et Flink à watsonx.data pour fournir un contexte temps réel aux systèmes agentiques. Derrière l’annonce se cache une évidence souvent oubliée : un agent ne vaut pas grand-chose s’il agit sur une donnée obsolète, cloisonnée ou sortie de son contexte.
« Votre IA n’est aussi bonne que vos données », résume Rob Thomas. C’est banal. C’est pourtant le cœur du problème. La plupart des entreprises ne manquent pas de modèles. Elles manquent de données propres, accessibles, contextualisées, gouvernées et disponibles au bon moment. L’agentique rend cette faiblesse plus visible encore : lorsqu’un agent agit, la mauvaise donnée ne produit plus seulement une mauvaise réponse, mais potentiellement une mauvaise décision.
IBM ajoute à cette couche un moteur SQL accéléré par GPU, co-développé avec NVIDIA, destiné à réduire les coûts et les temps de traitement sur de grands volumes de données. Le cas Nestlé est mis en avant : un datamart couvrant 186 pays aurait permis une réduction de coûts de 83 % et une amélioration par 30 du ratio prix-performance. Le chiffre est impressionnant. Il mérite, comme toujours, d’être interrogé : périmètre exact, coûts intégrés, reproductibilité, effort de transformation préalable ? Mais il dit bien où IBM place la bataille : non dans la beauté du modèle, mais dans le coût industriel de son alimentation.
Sovereign Core : souveraineté d’exécution ou souveraineté complète ?
Avec IBM Sovereign Core, annoncé en janvier dernier et désormais disponible, Big Blue ajoute la souveraineté à son récit. La solution repose bien évidemment sur Red Hat OpenShift et vise des déploiements on-premises, opérés localement, avec des partenaires comme Dell, AMD et Mistral. Rob Thomas décrit un cas d’usage initial centré sur l’IA : permettre à une entreprise ou à un gouvernement d’accéder rapidement à des modèles, à du logiciel et à de la puissance de calcul dans son propre datacenter.
Le positionnement est intéressant, parce qu’il n’est pas exactement celui des offres de cloud souverain classiques. Là où SAP s’appuie sur Bleu en France pour clarifier sa trajectoire souveraine, IBM met en avant une souveraineté d’exécution : des règles intégrées au niveau de l’infrastructure, une portabilité applicative, une exploitation locale, une capacité à fonctionner dans des environnements isolés.
Bref, IBM Sovereign Core est un socle logiciel, fondé sur Red Hat, permettant de bâtir des environnements souverains où le plan de contrôle, l’identité, les clés, les journaux, la conformité et l’exécution IA restent dans la frontière définie par le client. Pendant qu’AWS, Google, Microsoft et Oracle « souverainisent » leur cloud, IBM veut « souverainiser » l’architecture de l’entreprise cliente elle-même.
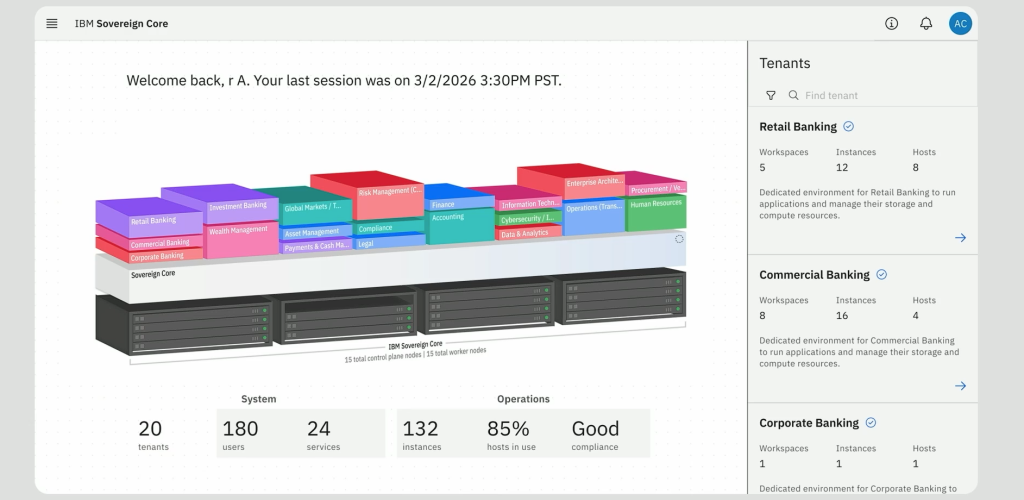
C’est une voie pragmatique. Mais elle appelle une lecture critique, notamment en France. Le marché français ne se contente pas toujours d’un discours architectural sur la souveraineté. Il attend des qualifications, des garanties contractuelles, des preuves d’exploitation, parfois un alignement avec SecNumCloud. Entre souveraineté d’exécution et souveraineté juridiquement opposable, il y a une distance que les DSI devront mesurer.
Ce débat rejoint celui que nous avons déjà ouvert autour de la souveraineté pragmatique, hybride et européenne. La souveraineté ne se résume plus à la localisation. Elle touche l’administration, les accès, les dépendances logicielles, les mises à jour, les droits extraterritoriaux, l’écosystème industriel et la capacité réelle d’une organisation à garder la main. IBM apporte une pièce au dossier. Pas nécessairement la conclusion.
Une vision solide, mais taillée pour le monde IBM
La force du discours d’IBM est aussi sa limite. Tout est cohérent, presque trop. L’IA opérationnelle renvoie à watsonx Orchestrate. Le développement agentique renvoie à Bob. La sécurité applicative renvoie à Concert. L’hybride renvoie à Red Hat OpenShift. La donnée temps réel renvoie à Confluent. Le legacy renvoie au mainframe. La souveraineté renvoie à Sovereign Core. Le conseil renvoie à IBM Consulting. Le puzzle est complet, mais il est dessiné depuis le territoire d’IBM.
Ce n’est pas forcément un défaut. IBM parle moins aux entreprises qui peuvent reconstruire vite dans un cloud moderne qu’à celles qui ne peuvent pas tout jeter : banques, assurances, administrations, santé, industrie, télécoms, défense, infrastructures critiques. Ces organisations n’ont pas besoin d’une énième démonstration d’agent brillant. Elles ont besoin de savoir comment brancher l’IA sur des systèmes existants sans perdre la maîtrise des coûts, des risques, des droits, de la conformité et de la responsabilité.
Il faut également garder une saine prudence sur les chiffres. IBM revendique plus de 5 milliards de dollars de gains de productivité internes grâce à l’IA. Arvind Krishna évoque des gains de 40, 50, 60, parfois 70 % sur certains processus de bout en bout. Ces chiffres impressionnent. Mais ils ne disent pas toujours ce qui relève de l’automatisation, de la réorganisation, de la réduction de tâches, de la réallocation des équipes ou d’une discipline managériale propre à IBM. Comme souvent avec l’IA, la productivité brute est plus facile à raconter que la transformation nette.
C’est précisément là que le discours d’IBM mérite d’être pris au sérieux sans être pris pour argent comptant. Il est moins flamboyant que celui des acteurs qui promettent une révolution par le modèle. Mais il est plus proche de la conversation réelle des DSI : comment passer de l’expérimentation à la production ? Comment éviter les agents incontrôlés ? Comment brancher l’IA sur des données vivantes ? Comment superviser des décisions automatisées ? Comment moderniser le legacy sans casser la logique métier ? Comment réduire le coût d’inférence ? Comment garder une souveraineté d’exécution ?
Le quantique, plus laboratoire mais pas encore marché de masse
IBM a aussi profité de Think 2026 pour rappeler son avance dans le quantique. L’annonce menée avec la Cleveland Clinic et RIKEN autour de la simulation d’une protéine de 12 635 atomes sert de jalon. Arvind Krishna y voit la preuve que le quantique « n’est plus seulement une expérience de laboratoire scientifique » et commence à produire des cas d’usage significatifs.

Mais le CEO d’IBM se garde bien d’en faire une grande opportunité commerciale immédiate. Aux partenaires, il conseille plutôt de se former, de développer quelques compétences et de préparer les clients. Pour les usages réellement transformateurs, notamment dans la pharmacie, il évoque plutôt un horizon 2028 ou 2029. Là encore, IBM marche sur une ligne fine : montrer que le quantique se rapproche, sans promettre aux DSI qu’il entrera demain dans leurs budgets courants.
La bataille du contrôle
Au fond, Think 2026 raconte moins l’arrivée de nouveaux produits que la tentative d’IBM de reprendre la main sur le récit de l’IA d’entreprise. Depuis deux ans, l’attention s’est déplacée vers les modèles, les copilotes, les agents, les interfaces conversationnelles. IBM répond par une vieille obsession remise au goût du jour : l’architecture.
Qui orchestre les modèles ? Qui gouverne les agents ? Qui contrôle les données ? Qui observe les environnements hybrides ? Qui valide les corrections de code ? Qui garantit que l’IA respecte les contraintes de souveraineté ? Qui sait encore moderniser les systèmes critiques sans confondre vitesse et précipitation ?
La vision d’IBM n’est pas la plus spectaculaire. Elle n’a pas l’éclat d’un nouveau modèle capable de battre tous les benchmarks. Elle parle de tuyauterie, de droits, de gouvernance, de supervision, de coûts, de workflows et de systèmes anciens. Bien sûr, AWS avec AgentCore, Google Cloud avec Gemini Enterprise Agent Platform et Microsoft avec Agent 365 en font de même, mais ils le font dans leur cloud, pas dans les datacenters de leurs clients.
Au final, dans l’IA d’entreprise, la question n’est déjà plus de savoir quel modèle pense le mieux.
Elle devient beaucoup plus rude : qui saura faire travailler les agents sans perdre le contrôle de l’organisation ?
Toutes les annonces IBM Think 2026 en un clin d’oeil
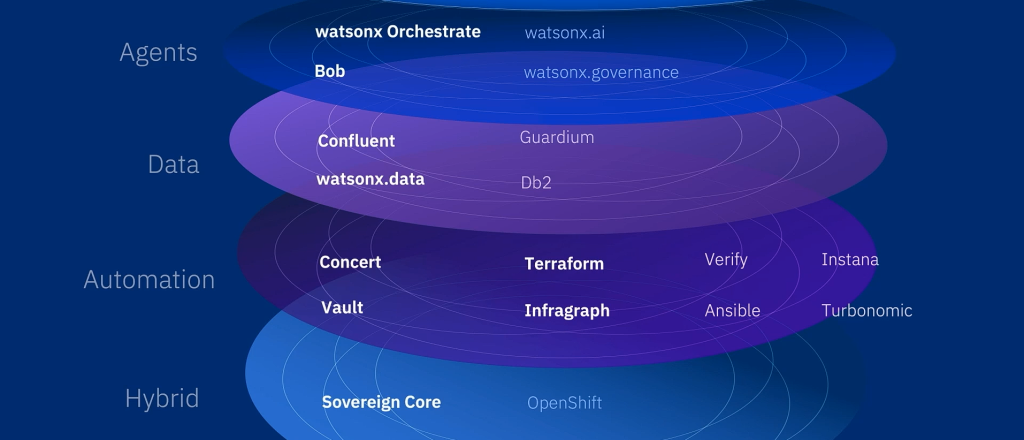
IBM Bob SaaS
IBM Bob devient une plateforme SaaS de développement agentique qui accompagne les équipes de bout en bout, de la conception au déploiement des logiciels, en intégrant génération de code, tests, sécurité, modernisation applicative et conformité aux standards d’entreprise.
IBM Concert Platform
IBM Concert s’impose comme une plateforme d’opérations agentiques capable d’agréger les signaux d’Instana, Turbonomic, SevOne ou Cloud Pak for AIOps pour corréler les incidents, automatiser les décisions et optimiser performance, coûts et résilience. Le module Concert Secure Coder s’insère dans les environnements BOB et VS Code pour ramener la sécurité au moment même où le code est écrit : il détecte les vulnérabilités, secrets, mauvaises configurations et risques open source dans l’IDE, propose des corrections contextualisées par l’IA et réinjecte ces signaux dans Concert afin de donner aux équipes sécurité et opérations une vision continue de l’exposition applicative.
IBM Sovereign Core
IBM Sovereign Core propose une pile logicielle souveraine portable, prête à l’emploi, basée sur Red Hat OpenShift, pour permettre aux entreprises, gouvernements et fournisseurs de services de déployer des environnements IA hybrides tout en gardant le contrôle des données, des opérations et de la gouvernance.
Confluent intégré au portefeuille IBM
Avec Confluent, IBM veut transformer les flux d’événements temps réel en données gouvernées, ouvertes et immédiatement exploitables par les applications, les analyses et les agents IA.
Watsonx Orchestrate devient un plan de contrôle agentique
IBM watsonx Orchestrate évolue vers un véritable plan de contrôle multi-agents destiné à superviser, gouverner et optimiser des écosystèmes d’agents hétérogènes à l’échelle de l’entreprise.
AI Editions for Core Software
IBM injecte assistants, agents et toolkits agentiques dans ses logiciels cœur – Db2, Cognos, MQ, CP4I, CP4BA, ACE, OMS, B2Bi, ELM ou Content Cortex – pour transformer les processus existants en workflows pilotables en langage naturel.
Vault Enterprise 2.0
HashiCorp Vault Enterprise 2.0 renforce la gestion des secrets en environnement hybride et multicloud, avec un objectif clair : réduire les identifiants longue durée, automatiser leur cycle de vie et industrialiser le chiffrement à grande échelle.
IBM zSecure Secret Manager
IBM zSecure Secret Manager automatise la gestion du cycle de vie des certificats sur z/OS afin de moderniser la sécurité mainframe sans casser les pratiques de confiance déjà en place dans les grandes organisations.
IBM Cyber Fraud
Fruit de développements réalisés par IBM pour ses clients bancaires et financiers depuis des années, IBM Cyber Fraud introduit une plateforme d’investigation anti-fraude assistée par IA, capable d’unifier données de paiement, fraude et cybersécurité pour accélérer les enquêtes et réduire le travail manuel.
HCP Terraform powered by Infragraph
Avec Infragraph, IBM et HashiCorp veulent transformer l’infrastructure hybride en graphe de connaissance vivant, capable d’offrir une vision centralisée du patrimoine technique et de préparer des remédiations automatisées.
Real-time Context on watsonx.data
IBM enrichit watsonx.data avec une couche de contexte temps réel permettant aux agents IA d’accéder à des données fraîches, sémantisées, gouvernées et interprétables dans leur contexte métier.
Agentic Data Integration
Agentic Data Integration permet aux métiers de formuler leurs besoins de données en langage naturel, pendant que des agents IA génèrent des pipelines gouvernés, contrôlés et validables par les équipes data.
IBM DataPower Interact Gateway
IBM DataPower Interact Gateway devient une passerelle de médiation IA conçue pour sécuriser, gouverner et observer les interactions entre agents, modèles, outils, API et données d’entreprise.
IBM Z Database Assistant
IBM Z Database Assistant apporte une couche d’intelligence opérationnelle à Db2 et IMS sur IBM Z pour surveiller la santé des bases, recommander des actions et passer d’une logique réactive à une gestion proactive.
Content Cortex
Content Cortex vise à transformer les contenus statiques d’entreprise — relevés, documents fiscaux, pièces administratives — en actifs gouvernés, indexés et exploitables par les workflows agentiques.
IBM SQL Data Insights Pro
IBM SQL Data Insights Pro ajoute une couche d’intelligence à Db2 for z/OS pour transformer les requêtes SQL en analyses explicables, détecter motifs et anomalies, et optimiser les performances sans déplacer les données.
Docling for IBM watsonx
Docling for IBM watsonx structure les documents en formats exploitables par l’IA, comme Markdown, JSON ou HTML, afin d’améliorer la recherche, le RAG et les workflows agentiques sans perdre le contexte documentaire.
OpenRAG on watsonx.data
OpenRAG sur watsonx.data assemble Docling, OpenSearch et Langflow dans un framework RAG ouvert destiné à connecter les agents IA aux connaissances dispersées de l’entreprise.
Watsonx.data avec serveur MCP intégré
Avec watsonx.data 2.3.2, IBM introduit un serveur MCP managé pour exposer les capacités de la plateforme data comme des outils standardisés, découvrables et gouvernés par des agents IA.
Accélération GPU pour watsonx.data
IBM lance une préversion technique privée du traitement de requêtes accéléré par GPU NVIDIA pour Presto C++ dans watsonx.data, afin d’accélérer l’analytique sans modifier les requêtes SQL ni les pipelines existants.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :











