


Data / IA
Nouvelles tendances IA : Google lance Gemma 4 et Microsoft inaugure 3 nouveaux modèles MAI
Par Laurent Delattre, publié le 07 avril 2026
Coïncidence de calendrier, Google et Microsoft ont simultanément lancé en fin de semaine dernière de nouveaux modèles qui en disent longs sur leurs stratégies actuelles et la quête des entreprises à dénicher de nouveaux outils pour mieux servir leur nécessaire industrialisation de l’IA et des cas d’usage déployables à l’échelle, sécurisés et à la valeur justifiée.
L’histoire récente de l’IA chez Google et Microsoft raconte deux cheminements inverses et pourtant symétriques. Google a longtemps misé l’essentiel de ses efforts sur les grands modèles propriétaires. Avec Gemini, le géant de Mountain View a construit une famille de LLM frontières destinés à alimenter ses propres produits – Search, Workspace, Cloud – et à rivaliser avec GPT-5 d’OpenAI et Claude d’Anthropic. Les modèles ouverts, incarnés par la lignée Gemma, ont longtemps fait figure de sous-produits : des déclinaisons allégées, publiées sous licence restrictive, davantage conçues pour animer l’écosystème de recherche que pour rivaliser sur le terrain commercial. Mais avec l’annonce de Gemma 4, Google change radicalement de posture.
Dans le même temps, Microsoft parcourait le trajet inverse. Pendant que son partenaire OpenAI explorait les frontières des modèles massifs (de GPT-4 à GPT-5 en passant par les modèles de raisonnement o1 et o3), les équipes de Redmond se concentraient sur les petits modèles Phi. Ces derniers (Phi-2, Phi-3, Phi-4) ont démontré que des modèles ouverts, compacts et bien entraînés pouvaient rivaliser avec des architectures bien plus volumineuses sur de nombreuses tâches. Avec le lancement des modèles MAI (Microsoft AI) et de l’équipe « MAI Super Intelligence », l’éditeur prend désormais son envol sur les grands modèles propriétaires et gagne son autonomie face à OpenAI. Il lance trois nouveaux modèles majeurs couvrant la voix, la transcription et la génération d’images. Des modèles très précis pour servir des besoins d’entreprise qui ne le sont pas moins.
Dit autrement, les deux géants de la Tech et de l’IA renforcent chacun la zone qu’il mettait jusque-là davantage en arrière-plan, au moins médiatiquement. Cette inversion des polarités n’est pas anecdotique. Elle traduit une maturation du marché où chaque acteur, après avoir consolidé un avantage initial, cherche désormais à combler ses angles morts stratégiques.
Gemma 4 : plus doué, plus ouvert
Gemma 4 marque une rupture à plusieurs niveaux. D’abord par sa licence : là où les précédentes versions de Gemma imposaient des restrictions d’usage commercial et de redistribution, Gemma 4 est publié sous Apache 2.0, la même licence permissive qu’utilisent des concurrents comme Mistral Small 4 ou Alibaba Qwen 3.5. Plus aucun plafond d’utilisateurs actifs, plus de politique d’usage acceptable imposée par Google. C’est un signal fort envoyé à l’écosystème open source : Google ne fait plus semblant d’être ouvert, il le devient réellement. Même si on parle bien ici de modèles en « open weight » plus que de modèles en « open source » selon la définition officielle de l’OSI.
La famille « Gemma 4 » se décline en quatre tailles soigneusement architecturées. Les modèles E2B et E4B (le « E » signifiant « effective parameters ») sont optimisés pour l’exécution locale en périphérie : smartphones, Raspberry Pi, NVIDIA Jetson Orin Nano. Ils exploitent une technique baptisée Per-Layer Embeddings (PLE) qui maximise l’efficacité paramétrique en ajoutant un signal d’embedding secondaire à chaque couche du décodeur. Explication : dans un LLM classique, l’embedding initial des tokens (la représentation vectorisée des informations) est surtout injecté à l’entrée du modèle, puis l’information est transformée de couche en couche. Avec les PLE, chaque couche reçoit en plus un rappel direct de la représentation d’origine. L’objectif est de mieux préserver le signal utile tout au long du traitement, d’améliorer la qualité des sorties et d’obtenir davantage de performances sans augmenter autant le nombre de paramètres.
Multimodaux, ces modèles embarquent nativement un encodeur audio de type Conformer USM, capable de reconnaissance vocale et de traduction depuis la parole, le tout avec une fenêtre de contexte de 128 000 tokens.
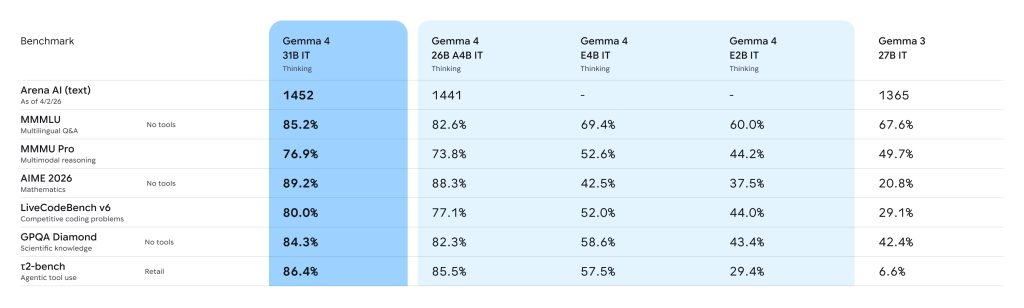
Le modèle 26B-A4B adopte une architecture Mixture-of-Experts (MoE) avec 128 petits experts. Pour chaque token traité, le routeur sélectionne 8 experts parmi les 128, plus 1 expert « partagé » qui est systématiquement activé, quel que soit le token. Donc, 9 experts travaillent sur chaque token, les 119 autres restent inactifs. Résultat : seuls 3,8 milliards de paramètres sont sollicités à chaque passe, pour un total de 25 milliards. En pratique, cela revient à exécuter un modèle de 4 milliards de paramètres tout en atteignant 97 % des performances du modèle dense de 31 milliards.
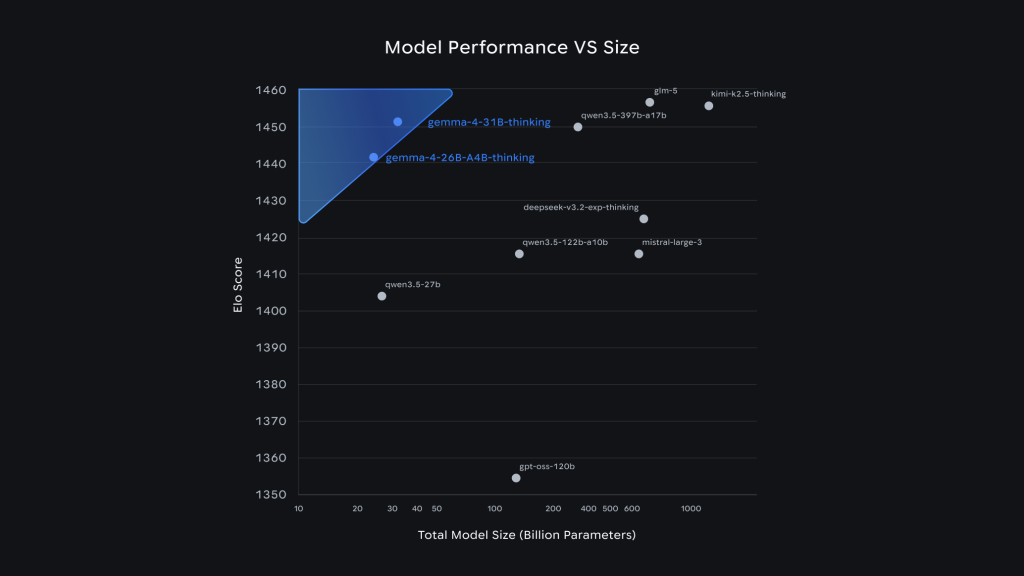
Le 31B, justement, est le quatrième modèle proposé, le vaisseau amiral de la famille Gemma 4 : un modèle dense qui se classe troisième sur le leaderboard Arena AI parmi les modèles ouverts, avec un score ELO d’environ 1 452. Sur les benchmarks, les progrès sont spectaculaires. Le 31B passe de 20,8 % à 89,2 % sur AIME (mathématiques) et de 29,1 % à 80 % sur LiveCodeBench (code) par rapport à Gemma 3. Le score BigBench Extra Hard bondit de 19,3 % à 74,4 %.
Tous les modèles de la famille partagent des innovations architecturales notables : une attention hybride alternant fenêtre glissante locale et attention globale complète, un double système de position rotative (Dual RoPE) pour les fenêtres de contexte longues allant jusqu’à 256 000 tokens, et un cache KV partagé entre couches pour réduire mémoire et calcul. La multimodalité est native : texte, images à résolution variable, vidéo jusqu’à 60 secondes, et audio sur les modèles edge.
Mais au-delà des chiffres, c’est la densité fonctionnelle qui impressionne : appels de fonctions natifs, sortie JSON structurée, planification multiétapes, mode de raisonnement étendu configurable et même détection de boîtes englobantes pour l’automatisation d’interfaces. Gemma 4 n’est plus un petit modèle pour la recherche : c’est une plateforme agentique complète, capable de rivaliser avec des modèles propriétaires sur le terrain des applications réelles.
Microsoft MAI prend de l’ampleur et de l’ambition
Sans renier ni OpenAI ni ses familles ouvertes Phi, Microsoft fait progressivement monter MAI en puissance comme marque de ses modèles maison. En septembre dernier, Microsoft avait annoncé les previews de MAI-Voice-1 et MAI-1-Preview (concurrent de GPT-5).
Aujourd’hui, le groupe américain sort des phases previews pour officialiser l’arrivée de trois modèles spécialisés dans Foundry et MAI Playground : MAI-Transcribe-1, MAI-Voice-1 et MAI-Image-2. Ce regroupement compte presque autant que les modèles eux-mêmes. Ce qui se joue ici, c’est la transformation de MAI en suite de briques propriétaires spécialisées, prêtes à être consommées dans Foundry et injectées dans Copilot, Bing, PowerPoint et d’autres produits.
MAI-Transcribe-1 est probablement le signal le plus fort de cette stratégie. Microsoft le présente comme son meilleur modèle de traduction « speech-to-text », couvrant 25 langues, robuste aux accents, aux bruits ambiants et aux conditions réelles. Sur le benchmark FLEURS, référence du secteur pour la transcription multilingue, il affiche le taux d’erreur mot (Word Error Rate) le plus bas parmi tous les modèles concurrents évalués, autour de 3,8 à 3,9 %, contre environ 7,6 % pour Whisper Large v3 d’OpenAI. Il devance également Scribe v2, GPT-Transcribe et Gemini 3.1 Flash-Lite de Google sur les 25 langues les plus utilisées.
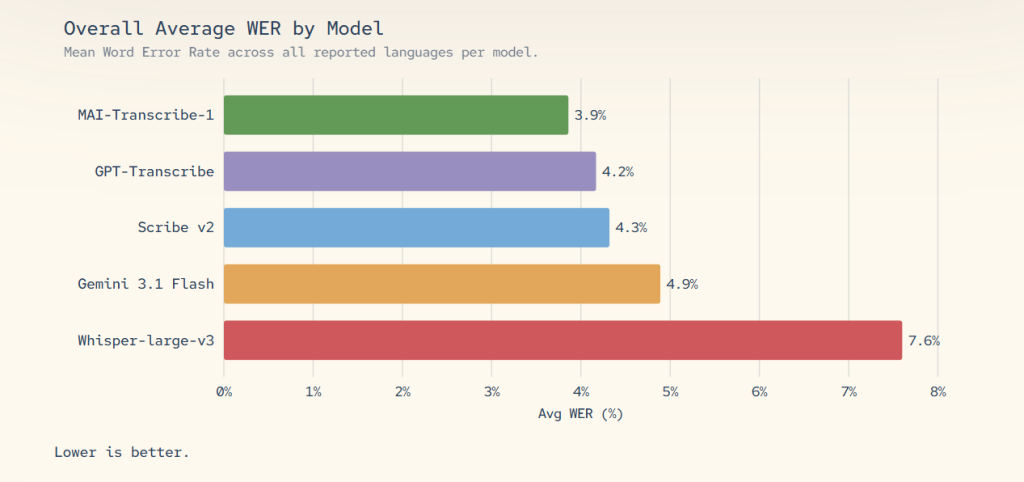
Au-delà de la précision, Microsoft met en avant l’efficacité opérationnelle : la vitesse de transcription en lot est 2,5 fois supérieure à l’offre Azure Fast existante, et le coût GPU serait réduit de moitié par rapport aux alternatives leaders. Proposé à 0,36 dollar par heure d’audio sur Microsoft Foundry, le modèle cible directement les cas d’usage d’entreprise : transcription de réunions, sous-titrage en temps réel, analyse de centres d’appel, dictée et agents vocaux. Il est déjà déployé dans Copilot Voice Mode et en cours d’intégration dans Microsoft Teams. Le modèle gère l’identification automatique de langue, mais Microsoft indique aussi que le temps réel, la séparation des locuteurs et le guidage contextuel sont prévus, mais encore à venir.
MAI-Voice-1 est plus révélateur encore de la stratégie MAI : non pas offrir une rupture absolue, mais une tentative d’assembler une offre first-party crédible sur une modalité monétisable. Sa promesse : produire 60 secondes d’audio en une seule seconde sur un GPU unique, avec une richesse d’expression, une gamme émotionnelle et une préservation de l’identité du locuteur, inédites sur les contenus longs. La fonctionnalité la plus notable est la création de voix personnalisées à partir de quelques secondes d’enregistrement audio seulement, via la fonctionnalité Personal Voice d’Azure Speech. Cette capacité de clonage vocal, encadrée par un processus d’approbation conforme aux politiques d’IA responsable de Microsoft, ouvre des perspectives considérables pour les agents conversationnels, les podcasts automatisés et l’accessibilité.
Néanmoins, la concurrence dans ce domaine est vive. ElevenLabs s’est imposé comme la référence de la synthèse vocale réaliste avec des capacités de clonage et une expressivité qui ont séduit les créateurs de contenu. Amazon Polly propose une alternative industrielle, solide mais moins naturelle.
OpenAI permet déjà d’instruire la manière de parler d’un modèle TTS. Google pousse en entreprise ses solutions Gemini-TTS, Chirp 3 HD et Instant Custom Voice. Alors, pour se différencier, Microsoft joue à la fois l’intégration à son écosystème et le prix. MAI-Voice-1 alimente déjà Copilot Audio Expressions et Copilot Podcasts, et s’inscrit dans la galerie de plus de 700 voix d’Azure Speech. Il est également intégré à Microsoft Foundry et aux garde-fous avancés que propose cette plateforme. À 22 dollars par million de caractères, Microsoft joue la carte du rapport qualité-prix face aux 30 dollars pour Chirp 3 HD et 60 dollars pour Instant Custom Voice chez Google Cloud. Reste un bémol très limitant : seul l’anglais est actuellement disponible, avec plus de langues à venir.
Avec MAI-Image-2, Microsoft vise un autre étage de la pile créative des entreprises : celui de l’image générative intégrée aux usages bureautiques et marketing. L’éditeur affirme que le modèle a hissé MAI parmi les trois premiers laboratoires text-to-image du classement Arena.ai, qu’il est au moins deux fois plus rapide dans Foundry et Copilot à qualité comparable, et qu’il excelle particulièrement sur le photoréalisme, les tons de peau, la lumière naturelle et le texte dans l’image. Son model card décrit un modèle diffusion/flow matching doté d’une fenêtre contextuelle de 32.000 tokens, capable de générer des images allant jusqu’à 1024×1024 pixels.

Là encore, Microsoft entre dans un marché déjà densément occupé : OpenAI avec GPT Image, Google avec Imagen 4 et Gemini 3.1 Flash Image -Nano Banana), Black Forest Labs avec FLUX.2, Midjourney V8 Alpha, ou encore Adobe Firefly, qui se présente désormais comme une surcouche multi-modèles.
Pour se différencier, MAI-Image-2 joue la carte de l’intégration dans l’écosystème Microsoft (il va animer Bing Image et PowerPoint) et Azure, avec une promesse de rapport coût/performance compétitif : 5$ par million de tokens en entrée, 33$ par million de tokens en sortie, soit entre 3et 15 centimes l’image selon sa qualité et ses détails.
Ces trois lancements matérialisent la nouvelle stratégie de la division Microsoft AI avec une logique d’intégration verticale et de cohérence de pile technologique ainsi qu’une trajectoire d’indépendance vis-à-vis d’OpenAI commençant par des modèles aux usages très spécialisés. Ces modèles MAI propulsent Copilot, Bing, PowerPoint et Azure Speech : ils ne sont pas expérimentaux, ils sont déjà en production. Leur mise à disposition sur Microsoft Foundry, la plateforme commerciale de Microsoft pour le déploiement d’IA, envoie un message clair aux développeurs et aux entreprises : ces modèles sont désormais prêts pour vos applications critiques.
Au final, ces annonces montrent que le marché de l’IA n’est clairement plus binaire, entre grands modèles propriétaires d’un côté et petits modèles ouverts de l’autre. Il s’organise désormais en couches : des modèles ouverts performants pour le contrôle et la portabilité, des modèles propriétaires spécialisés pour la performance et l’intégration, des grands modèles génératifs et des plateformes complètes dans le cloud pour l’orchestration. L’heure est aux piles IA hybrides, mêlant grands modèles propriétaires, petits modèles locaux, modèles spécialisés, modèles privés… La vraie compétition ne porte plus sur « quel est le meilleur modèle », mais sur quelle est la combinaison de modèles la plus adaptée aux besoins, sous quelle licence et avec quelle dépendance, au service de quelle expérience et avec quelle économie sur la facture des apps IA ?
À LIRE AUSSI :
À LIRE AUSSI :











