


Data / IA
Forge, Small 4, Leanstral : Mistral AI accélère en mode « entreprise-first »
Par Laurent Delattre, publié le 20 mars 2026
Mistral AI accélère son pivot vers l’IA d’entreprise en articulant modèles ouverts, personnalisation profonde et vérification formelle. Avec Forge, Small 4 et Leanstral, la startup française cherche moins à séduire le grand public qu’à s’imposer comme l’infrastructure cognitive incontournable des organisations européennes.
Alors que les géants de l’IA américains que sont OpenAI, Anthropic, Google, Microsoft et NVidia ont beaucoup monopolisé l’attention des médias ces dernières semaines et particulièrement secoué les terrains de jeu des modèles frontières et de l’IA agentique, Mistral AI réalise une contre-attaque médiatique en annonçant d’un seul coup trois innovations majeures qui, bien plus qu’enrichir son portfolio pourtant déjà bien rempli, viennent surtout éclairer un virage stratégique profond : celui d’une startup française qui, plutôt que de courir après la viralité grand public d’un ChatGPT ou d’un Claude, fait le pari de devenir la colonne vertébrale de l’IA des entreprises et organisations publiques.
Avec Mistral Small 4, Leanstral, et surtout Forge, la jeune pousse française, principal espoir de la résistance européenne aux rouleaux compresseurs IA venus de Chine et des USA, continue d’assembler avec discipline une pile complète et cohérente dédiée à l’IA d’entreprise : un socle généraliste ouvert et efficient, une capacité à fabriquer des modèles profondément adaptés aux savoirs internes, et un agent de code orienté preuve et vérification.
Forge : quand l’IA absorbe le savoir institutionnel

Le nom parle de lui-même : il ne s’agit plus d’ajuster un modèle générique par fine-tuning ou par RAG (Retrieval-Augmented Generation), mais bien de permettre aux entreprises de « forger » leurs propres modèles « from scratch » à partir des données propriétaires d’une organisation telles que sa documentation interne, ses bases de code, ses procédures opérationnelles, ses historiques de décisions.
Avec son nouveau service Forge, Mistral AI ne se contente plus de fournir des modèles mais fournit aux entreprises les moyens de créer simplement leurs propres modèles. Forge n’est pas un outil de personnalisation et de fine tuning de modèles parmi d’autres : c’est un service de conception et création de modèles mais aussi une infrastructure sur laquelle Mistral entend bâtir une relation de long terme avec ses clients.
Le dispositif couvre l’intégralité du cycle de vie d’un modèle : pré-entraînement pour construire une compréhension du domaine, post-entraînement pour affiner les comportements sur des tâches spécifiques, et apprentissage par renforcement pour aligner les agents sur les politiques, les critères d’évaluation et les objectifs opérationnels de l’entreprise.
Encoder le vocabulaire, les contraintes et les schémas de raisonnement de l’entreprise dans le modèle lui-même, au lieu de laisser toute l’intelligence métier flotter à la périphérie dans du RAG ou des prompts, promet d’obtenir des IA plus ancrées dans le Business de l’organisation, donc plus pertinentes et plus optimisées. De quoi s’assurer que les POC passent plus aisément à l’échelle.
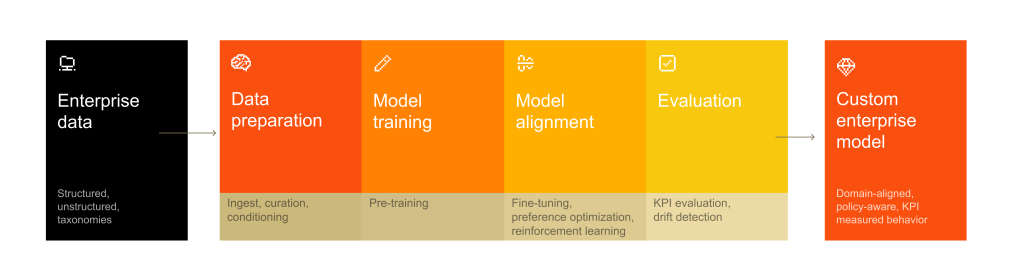
Forge prend en charge à la fois les modèles denses et les architectures en mélange d’experts (MoE), ainsi que les entrées multimodales. L’offre se distingue aussi par un volet « Forward-Deployed Engineers » (FDE) : des ingénieurs Mistral sont directement intégrés chez le client pour accompagner la constitution des jeux de données, la création de pipelines de données synthétiques et la mise au point des évaluations. Construire un modèle ne s’improvise pas et demande un accompagnement que Mistral AI veut, au moins dans un premier temps, assurer.
Les premiers partenaires de Forge sont d’ores et déjà annoncés : ASML (qui avait conduit le tour de table Series C de Mistral à 11,7 milliards d’euros de valorisation), Ericsson, l’Agence spatiale européenne, les laboratoires nationaux DSO et HTX de Singapour, et le cabinet de conseil italien Reply.
Forge arrive sur un terrain déjà contesté. AWS propose Nova Forge avec une logique très proche de celle de Mistral AI et la promesse de permettre à chaque entreprise de créer son propre modèle frontière dérivant des modèles Nova. OpenAI, de son côté, a étendu depuis longtemps son programme de modèles personnalisés et ses capacités de fine-tuning assisté.
Mistral n’invente donc pas la catégorie. En revanche, il la reformule avec son ADN : ouverture, approche agent-first, architectures denses ou MoE, multimodalité, sur lequel vient se greffer un discours de souveraineté qui fait de plus en plus mouche, géopolitique oblige. La collaboration annoncée fin février avec Accenture, centrée sur la « performance, le contrôle et la personnalisation », montre que Forge vise d’abord les grands comptes et les transformations sectorielles lourdes (c’est aussi vrai d’AWS Nova Forge). Logique : entraîner ou réentraîner un modèle à ce niveau suppose une maturité encore rare sur les données, les évaluations, l’infrastructure et la gouvernance.
Mistral Small 4 : un modèle, trois cerveaux

Forge a besoin de briques de base sur lesquelles construire. C’est précisément le rôle de Mistral Small 4, le premier modèle de l’écurie Mistral à unifier dans une seule architecture les capacités de trois familles auparavant distinctes : Magistral (raisonnement), Pixtral (multimodal) et Devstral (codage agentique). Les utilisateurs n’ont plus à choisir entre un modèle rapide, un moteur de raisonnement profond et un assistant multimodal : un seul modèle fait les trois, avec un effort de raisonnement configurable via un paramètre dédié (« reasoning_effort » permettant d’arbitrer entre faible latence et raisonnement plus profond).
Sur le plan technique, Small 4 repose sur une architecture MoE à 128 experts, dont 4 actifs par token, pour un total de 119 milliards de paramètres mais seulement 6 milliards de paramètres actifs par token (8 milliards en comptant l’embedding et la couche de sortie). La fenêtre de contexte atteint 256 000 tokens.
Mistral affirme avoir ainsi réduit de 40 % le temps de complétion de bout en bout et tripler le débit par rapport à Mistral Small 3, tout en gardant une empreinte d’infrastructure relativement contenue pour cette classe de modèle (à minima 4 GPU NVIDIA HGX H100, ou 2 GPU HGX H200, ou encore 1 seul GPU DGX B200, mais mieux vaut doubler pour des performances optimales).
Les benchmarks publiés par Mistral montrent que Small 4 avec raisonnement activé atteint des scores comparables ou supérieurs à GPT-OSS 120B sur les benchmarks AA LCR, LiveCodeBench et AIME 2025, tout en générant des sorties significativement plus courtes. Sur LCR par exemple, Small 4 obtient un score de 0,72 avec seulement 1,6K caractères de sortie, là où les modèles Qwen nécessitent 3,5 à 4 fois plus de texte pour des performances comparables. En entreprise, cela se traduit par une latence réduite, une meilleure expérience utilisateur et surtout des coûts d’inférence comprimés ! A l’heure où les entreprises commencent à se soucier du « coût par token », cet argument financier à du poids.
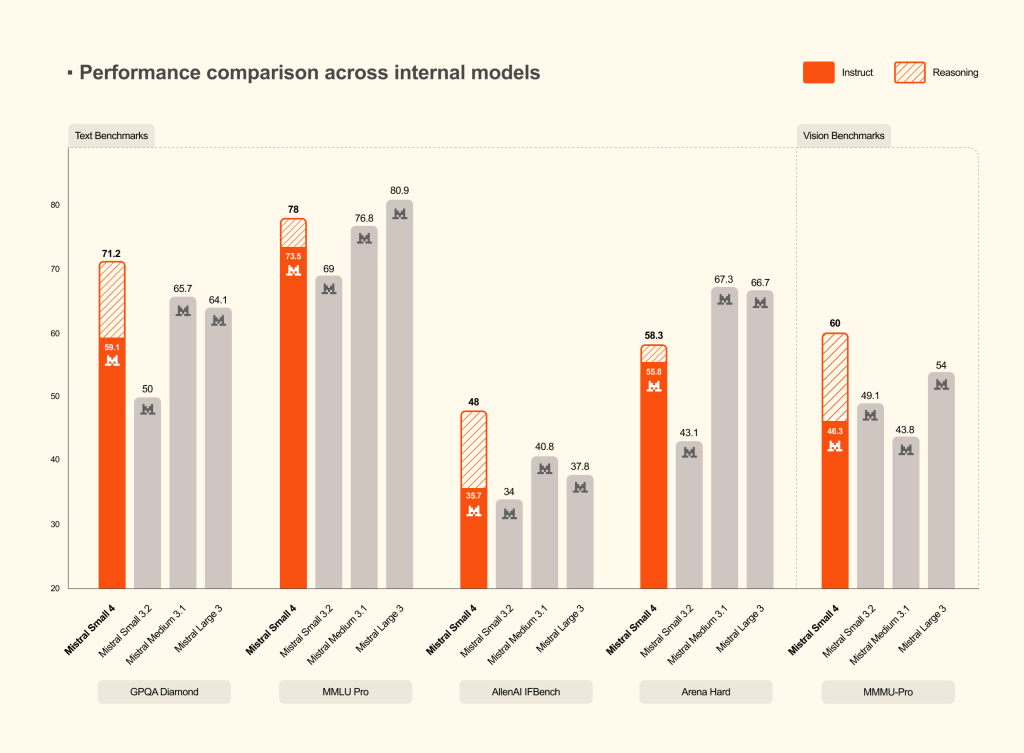
Publié sous licence Apache 2.0, Small 4 s’inscrit dans l’ADN open source de Mistral et rejoint la bibliothèque de modèles ouverts que les clients de Forge pourront personnaliser. Comme l’explique Timothée Lacroix, cofondateur et directeur technologique de Mistral AI : « Les compromis que nous faisons lorsque nous construisons des modèles plus petits impliquent qu’ils ne peuvent pas être aussi bons sur chaque sujet que leurs homologues plus grands. La capacité à les personnaliser nous permet de choisir ce que nous soulignons et ce que nous laissons de côté ». En d’autres termes, Small 4 n’est pas seulement un modèle à déployer : c’est aussi un modèle à s’approprier.
Mistral Small 4 est disponible dès à présent sur La Plateforme (l’API Mistral), sur Mistral AI Studio, sur Hugging Face, sur NVIDIA NIM. Il peut aisément être personnaliser pour un domaine spécifique via NVIDIA NeMo mais aussi via son intégration à vLLM, llama.cpp, SGLang, Transformers…
Leanstral : quand l’IA prouve ce qu’elle code

La troisième annonce est la plus pointue, mais peut-être la plus visionnaire. Leanstral est le premier agent de code open source conçu pour Lean 4, un assistant de preuve formelle capable d’exprimer des objets mathématiques complexes et des spécifications logicielles rigoureuses.
Autrement dit, ce modèle de codage ne se contente pas de générer du code : il prouve que ce code respecte bien une spécification donnée.
L’enjeu est fondamental à l’ère de l’IA agentique. Aujourd’hui, le principal goulet d’étranglement de la productivité des agents de code n’est pas la génération elle-même mais la vérification humaine. Plus les agents deviennent capables, plus le temps de contrôle et révision par l’humain explose. Leanstral propose une réponse radicale à ce défi : plutôt que de déboguer de la logique générée par la machine, l’humain dicte ce qu’il veut et l’agent prouve formellement que son implémentation est correcte.
Avec seulement 6 milliards de paramètres actifs (dans une architecture MoE de 120 milliards), Leanstral est remarquablement efficient. Sur le benchmark FLTEval créé par Mistral – qui mesure la capacité à compléter des preuves formelles et à définir de nouveaux concepts mathématiques dans des Pull Requests réelles du projet FLT -, Leanstral surpasse des modèles open source bien plus volumineux comme GLM5 (744B) ou Kimi-K2.5 (1T) dès le premier passage. Et avec pass@2, il atteint un score de 26,3, battant Claude Sonnet 4.6 (23,7) pour un coût de seulement 36 dollars contre 549 dollars pour Sonnet. Seul Claude Opus 4.6 le devance nettement avec son score de 39,6, mais pour un coût de 1 650 dollars, soit 92 fois plus cher !
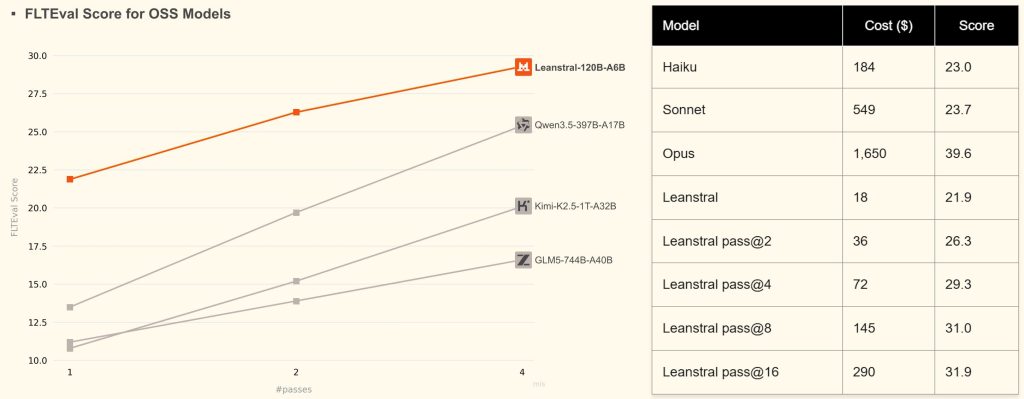
L’intérêt pour l’entreprise dépasse la seule communauté des mathématiciens. La preuve formelle concerne aussi la vérification de logiciels critiques comme les systèmes embarqués, les protocoles de sécurité, la conformité réglementaire, le code financier. En publiant Leanstral sous Apache 2.0 et en l’intégrant directement dans Mistral Vibe (son environnement de « vibe coding »), Mistral pose les premières fondations d’un écosystème où le code généré par l’IA pourra être formellement démontré et certifié. Un argument qui devrait désormais particulièrement intéresser les secteurs réglementés où la révolution de l’ingénierie logicielle dopée à l’IA peine à se concrétiser.
Au fond, ces trois annonces disent une même chose : Mistral parie que le marché de l’IA d’entreprise entre dans une deuxième phase. La première consistait à brancher des assistants génériques sur des cas d’usage internes. La suivante consistera à reconstruire des logiciels, des workflows et des briques de décision autour de modèles spécialisés, d’agents outillés et d’une gouvernance beaucoup plus serrée. Quand son cofondateur Arthur Mensch affirme que l’IA doit être un « outil d’émancipation, pas de domination », il ne formule pas seulement une posture politique ; il énonce aussi une stratégie produit. Fournir aux entreprises les moyens de ne pas dépendre entièrement d’un cloud, d’un modèle fermé, d’un éditeur unique ou d’un simple copilote générique.
Et la stratégie porte déjà ses fruits. Mistral AI est en passe de dépasser le milliard de dollars de revenus récurrents annuels (ARR) en 2026, contre 400 millions annualisés début 2026 et seulement 20 millions un an plus tôt.
Bien sûr, la concurrence est rude, féroce même. OpenAI combine désormais modèles ouverts, modèles personnalisés et Codex, AWS pousse Nova Forge dans son empire cloud, Anthropic a pris une vraie longueur d’avance dans l’agentique avec Claude Code et Claude Cowork.
Mais Mistral dispose d’un assemblage rare : licence Apache 2.0, culture open source, architectures efficientes, discours crédible sur la souveraineté, ancrage européen, relais industriels, et même un puissant canal de transformation avec Accenture. De quoi lui permettre de ne pas simplement être “le champion européen de l’IA” mais l’un des acteurs qui comptent vraiment quand les entreprises cesseront d’acheter des assistants pour commencer à rebâtir leur logiciel autour des modèles agentiques.
À LIRE AUSSI :
À LIRE AUSSI :











