


Data / IA
Muse Spark : pourquoi Meta tourne la page LLama ?
Par Laurent Delattre, publié le 16 avril 2026
Premier modèle issu de Meta Superintelligence Labs, Muse Spark marque une rupture stratégique majeure pour le champion historique de l’IA ouverte. Décryptage d’un virage qui interroge l’ensemble de l’écosystème.
Meta a récemment dévoilé Muse Spark, premier modèle de sa nouvelle série Muse, et premier produit tangible de Meta Superintelligence Labs (MSL), la division IA créée autour d’Alexandr Wang. En soi, l’annonce d’un nouveau modèle de fondation par un géant de la tech n’aurait rien de fracassant, quand bien même ce géant s’appelle Meta.
Mais après avoir largement structuré le marché des modèles « ouverts » avec Llama, le groupe choisit désormais de réserver son meilleur moteur à son propre écosystème produit, avec une approche très propriétaire, tout en promettant d’ouvrir plus tard, en open-weight, certaines déclinaisons.
Le changement n’est pas anodin. Meta passe d’une logique d’influence sur l’écosystème IA à une logique de contrôle direct de la valeur.
De FAIR à MSL : la tumultueuse saga de l’IA chez Meta
L’histoire de l’intelligence artificielle chez Meta commence en 2013, lorsque Mark Zuckerberg recrute Yann LeCun (Prix Turing 2019 et figure tutélaire du deep learning) pour fonder FAIR, le laboratoire de recherche fondamentale en IA de Facebook. Pendant plus d’une décennie, FAIR incarne un modèle singulier dans l’industrie : un lab de recherche pure, adossé à l’un des plus grands groupes technologiques mondiaux, mais doté d’une liberté académique rare. Yann LeCun y poursuit ses travaux sur l’apprentissage auto-supervisé, les réseaux antagonistes génératifs et la vision par ordinateur, sans obligation de rendement produit immédiat. Le dispositif donne à Meta une crédibilité scientifique considérable et attire des talents de premier plan.
C’est dans cet écosystème qu’émerge la famille Llama à partir de 2023. Llama, puis Llama 2 et Llama 3, deviennent en quelques mois la référence mondiale des modèles de langage ouverts. En libérant les poids de ses modèles, Meta a construit un écosystème massif de développeurs, a imposé ses standards architecturaux comme base de facto de l’IA ouverte, et a créé un contrepoids aux modèles propriétaires d’OpenAI et de Google. Début 2026, l’écosystème Llama revendiquait 1,2 milliard de téléchargements, soit environ un million par jour. L’architecture de HuggingFace elle-même a été essentiellement construite autour du modèle Llama.
Llama a été pionnier moins parce qu’il était juridiquement “open source” au sens strict que parce qu’il a rendu crédible, à grande échelle, l’idée d’un modèle de haut niveau téléchargeable, adaptable, quantifiable et industrialisable hors des silos des hyperscalers. En pratique, Llama a servi de socle à une vague de fine-tuning, de dérivés, d’intégrations dans Hugging Face, Ollama, llama.cpp et les piles d’inférence locales ou souveraines. C’est ce qui explique son importance historique : Llama n’a pas seulement été un bon modèle, il a été la plateforme d’amorçage de l’écosystème open-weight moderne.

Mais un basculement s’est amorcé en avril 2025, avec le lancement de Llama 4. Trois modèles sont présentés : Scout (17 milliards de paramètres actifs), Maverick (400 milliards, architecture MoE à 128 experts) et Behemoth (2 000 milliards, encore en entraînement). Sur le papier, les performances annoncées sont impressionnantes. Dans les faits, le lancement vire au fiasco. Des accusations de manipulation de benchmarks éclatent presque immédiatement et Meta reconnaît avoir soumis à la plateforme d’évaluation LMArena une version « expérimentale » de Maverick, optimisée pour les préférences humaines, mais non disponible publiquement, une version distincte de celle que les développeurs pouvaient télécharger. LMArena elle-même a dû modifier ses règles d’évaluation à la suite de l’incident. Mark Zuckerberg aurait été « réellement furieux » et aurait « perdu confiance en tous ceux qui étaient impliqués » selon Yann LeCun. Le PDG de Meta décide alors de mettre à plat l’ensemble de l’organisation GenAI du groupe. Il investit 14,3 milliards de dollars dans Scale AI et recrute son fondateur et PDG, Alexandr Wang, 28 ans, pour diriger une nouvelle division baptisée Meta Superintelligence Labs. Nat Friedman, ex-PDG de GitHub, prend la tête du produit. Shengjia Zhao, cocréateur de ChatGPT, devient chief scientist. Sous cette nouvelle garde, la culture change radicalement : Yann LeCun, relégué au rôle de rapporteur hiérarchique de Wang, voit FAIR progressivement démantelé. En octobre 2025, Meta licencie 600 employés de la division Superintelligence Labs, dont des chercheurs de FAIR. Le 18 novembre 2025, Yann LeCun annonce son départ sur LinkedIn pour fonder AMI Labs, une startup parisienne dédiée aux « world models » (en levant 1,03 milliard de dollars en seed en mars 2026, la plus grosse levée d’amorçage jamais réalisée par une startup européenne).
Dans ce contexte de refondation complète – neuf mois de reconstruction de l’ensemble du stack IA de Meta depuis zéro, nouvelles infrastructures, nouvelle architecture, nouveaux pipelines de données – naissent un nouveau modèle et une nouvelle stratégie : Muse Spark.
Muse Spark : ce qu’il est, ce qu’il n’est pas
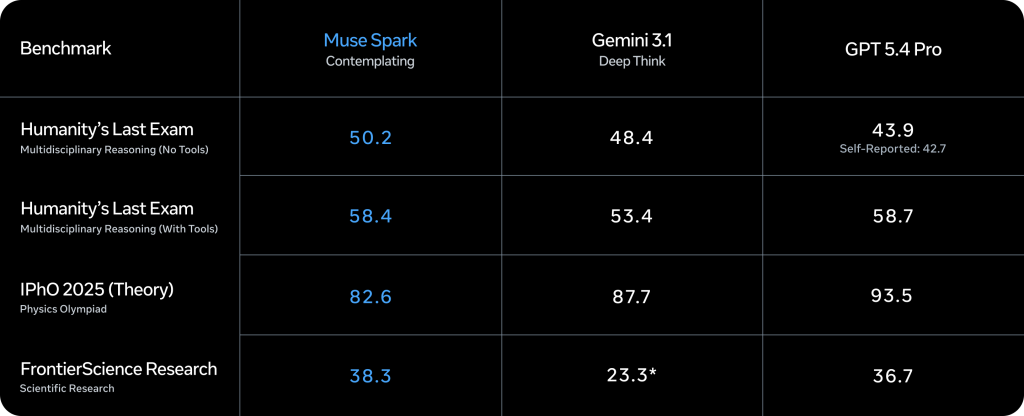
Muse Spark est un modèle de raisonnement nativement multimodal, capable de traiter du texte, des images et de la voix en entrée (pour l’instant, la sortie reste textuelle). Il intègre dès sa conception l’utilisation d’outils (tool-use), le raisonnement visuel en chaîne de pensée (visual chain of thought) et l’orchestration multi-agents. C’est cette dernière capacité qui constitue peut-être sa différenciation la plus marquée : le mode « Contemplating » (pensée approfondie) déploie plusieurs agents de raisonnement en parallèle pour traiter les problèmes complexes, là où l’approche classique du test-time scaling repose sur un agent unique qui « réfléchit plus longtemps ». Meta revendique des gains significatifs sur les benchmarks les plus exigeants, comme Humanity’s Last Exam (HLE) avec ce mode, tout en maintenant une latence comparable grâce au parallélisme.
Sur le plan des performances, le tableau est contrasté, mais globalement crédible. Muse Spark obtient un score de 52 sur l’Intelligence Index v4.0 d’Artificial Analysis, ce qui le place au quatrième rang mondial derrière Gemini 3.1 Pro et GPT-5.4 (tous deux à 57) et Claude Opus 4.6 (53). Le modèle brille en raisonnement scientifique (39,9 % sur HLE, troisième mondial), en compréhension visuelle (80,5 % sur MMMU-Pro, deuxième mondial) et surtout en IA de santé : avec 42,8 sur HealthBench Hard, Muse Spark devance GPT-5.4 (40,1) et écrase Gemini 3.1 Pro (20,6). Meta a travaillé avec plus de mille médecins pour entraîner cette spécialisation.
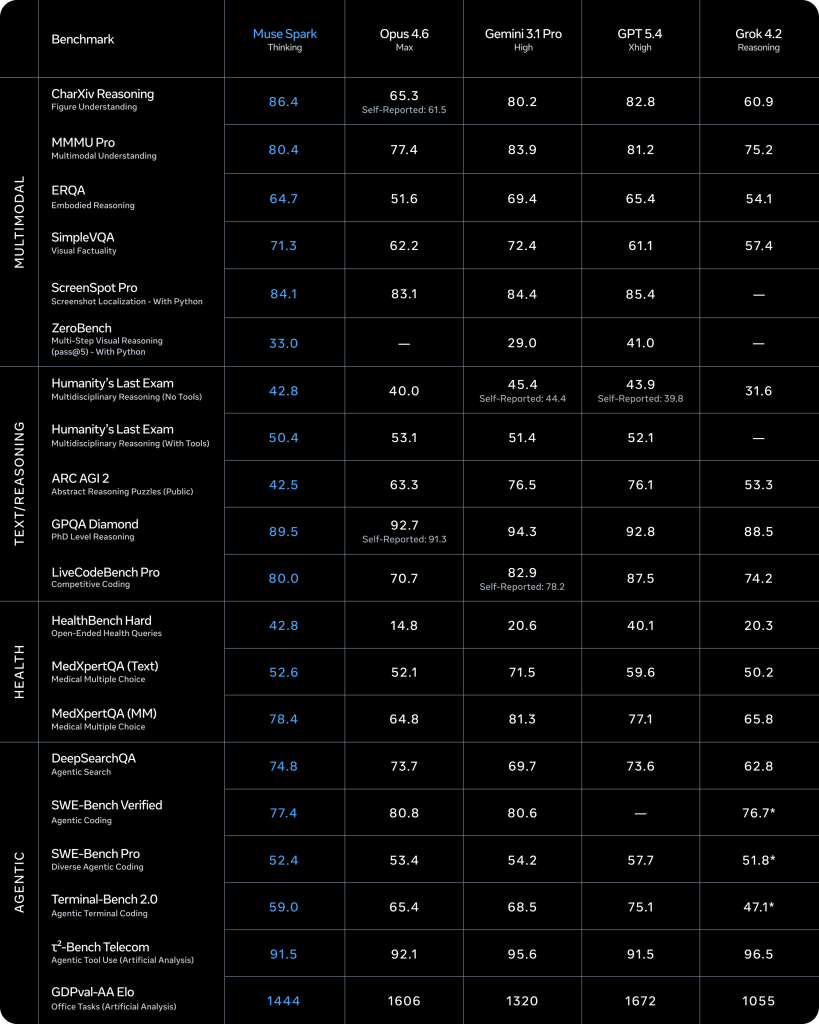
En revanche, les faiblesses sont tout aussi nettes. Sur le raisonnement abstrait (ARC-AGI-2), Muse Spark score à 42,5 contre 76,1 pour GPT-5.4 et 76,5 pour Gemini. Le codage constitue un autre point faible : 59,0 sur Terminal-Bench 2.0 contre 75,1 pour GPT-5.4, et 52,4 sur SWE-Bench Pro contre les 80,8 % de Claude Opus 4.6. L’agentic computing, c’est-à-dire la capacité à accomplir des tâches bureautiques de bout en bout de manière autonome, affiche un retard d’environ 200 points d’ELO sur GPT-5.4 (GDPval-AA). Meta a d’ailleurs explicitement reconnu ces lacunes en annonçant que le codage et les systèmes agentiques constituaient des priorités d’investissement pour les prochaines versions.
Ce que Muse Spark n’est pas, en revanche, mérite d’être souligné avec autant de netteté. Contrairement à LLama, ce n’est pas un modèle ouvert : les poids ne sont pas téléchargeables, l’architecture et le nombre de paramètres n’ont pas été divulgués, et aucun paper technique détaillé n’accompagne le lancement. Il n’est pas non plus, à ce stade, un modèle accessible aux entreprises via API publique : Meta propose une API en « private preview » à des partenaires sélectionnés, ce qui le rend paradoxalement plus verrouillé que les modèles payants d’OpenAI ou d’Anthropic, immédiatement disponibles via API. Enfin, il n’est pas un successeur de Llama : c’est une lignée entièrement nouvelle, construite depuis zéro, qui coexistera avec les modèles Llama existants mais ne les remplacera pas, tout au moins à court terme.
Encore bien des angles morts
Techniquement, le principal atout de Muse Spark réside dans son efficience. Le modèle n’a utilisé que 58 millions de tokens en sortie pour compléter l’évaluation complète de l’Intelligence Index d’Artificial Analysis, contre 120 millions pour GPT-5.4 et 157 millions pour Claude Opus 4.6. À l’échelle de Meta, qui déploie son IA auprès de trois milliards d’utilisateurs quotidiens, cette frugalité en tokens change radicalement l’économie d’exploitation. L’entreprise affirme d’ailleurs que Muse Spark est aussi performant que ses anciens modèles de taille intermédiaire pour un ordre de grandeur de compute en moins.
Comme le modèle n’est pour l’instant destiné qu’à animer Meta AI, l’IA conversationnelle de WhatsApp et Facebook (mais aussi Instagram, Messenger et les lunettes connectées Meta), il est trop tôt pour en évoquer les éventuelles perspectives pour les entreprises et les DSI. On notera quand même que l’architecture multi-agents du mode Contemplating est intéressante et pourrait se révéler fort pertinentes sur les cas d’usage d’entreprise nécessitant un raisonnement complexe : planification de projets, analyse croisée de données hétérogènes, investigation multidomaine. Muse Spark peut en effet lancer plusieurs sous-agents en parallèle, chacun explorant une facette du problème, avant de synthétiser.
La hiérarchie des modèles ouverts a changé

La sortie de Muse Spark intervient dans un paysage des modèles ouverts qui a profondément évolué depuis l’apogée de Llama. En avril 2026, ce paysage n’est plus un duopole Meta-Mistral : c’est une compétition à six acteurs majeurs, dont deux chinois.
Alibaba (Qwen 3.5/3.6) mène désormais sur les benchmarks de codage avec une licence Apache 2.0, Zhipu AI (GLM-5) domine le classement global des modèles ouverts sur BenchLM.ai, Google a surpris avec Gemma 4 (performances de niveau GPT-4 dans un modèle de 14 Go déployable sur hardware grand public), DeepSeek reste compétitif sur le rapport qualité-prix, Mistral (Small 4) s’impose comme le champion européen de l’efficience, et même OpenAI a lancé un modèle open weights (gpt-oss-120b) souvent utilisé en référence. Bref, l’écosystème ne manque pas de modèles ouverts. De là à dire que Meta ne manquera pas…
Néanmoins, Muse Spark ne signifie pas nécessairement que Meta abandonne définitivement les modèles ouverts. Le géant américain dit espérer open-sourcer de futures versions, des déclinaisons plus compactes.
Parallèlement, des versions plus grandes et plus multimodales du modèle sont déjà en préparation. Meta l’affirme, Muse Spark n’est pas un aboutissement : c’est un point de départ. L’éditeur le présente explicitement comme le « premier échelon d’une trajectoire de scaling », un modèle « small and fast by design » destiné à valider une approche scientifique avant de passer à l’échelle.
Mais ce qu’il traduit surtout, c’est une mue de Meta. Le groupe veut redevenir un acteur du premier cercle en capturant directement l’usage auprès de ses 3 milliards d’utilisateurs, et non plus en irriguant l’écosystème IA ouvert.
En attendant, les DSI qui avaient construit une stratégie IA ouverte sur l’écosystème Llama doivent désormais évaluer des alternatives.
À LIRE AUSSI :
À LIRE AUSSI :











