


Data / IA
Claude Fable 5 : Anthropic libère Mythos… mais avec une laisse de sécurité
Par Laurent Delattre, publié le 10 juin 2026
Claude Fable 5 marque une inflexion dans le déploiement des grands modèles, entre puissance généralisée et accès contrôlé aux capacités sensibles. Le nouveau modèle promet des agents plus endurants, plus multimodaux et plus efficaces, tout en révélant pourquoi l’autre modèle annoncé, Mythos 5 (version finale de Mythos Preview) reste sous verrou.
Avec Claude Fable 5, Anthropic ne lance pas simplement un nouveau grand modèle. L’éditeur inaugure une nouvelle manière de commercialiser l’IA frontière : non plus seulement par niveaux de puissance, mais par niveaux de risque. Le même cerveau peut être ouvert au grand public, bridé dans certains domaines, ou réservé à des partenaires de confiance lorsqu’il touche à la cybersécurité, à la biologie ou à la recherche duale.
En pratique, cela revient à enrichir par le haut la gamme Claude. Haiku reste le modèle rapide, économique, adapté aux usages à fort volume, aux agents légers, aux sous-tâches parallélisées et aux expériences temps réel. Sonnet est le modèle de production polyvalent, celui des agents d’entreprise, du code à l’échelle, des workflows métiers et des usages où il faut un bon compromis entre coût, vitesse et intelligence. Opus demeure le modèle premium, plus robuste, plus réfléchi, pensé pour le codage sérieux, les tâches agentiques longues et le knowledge work exigeant.
Mais deux nouveaux modèles font leur apparition et inaugurent la génération « 5 » (Haiku, Sonnet et Opus demeurant pour l’instant en génération 4.x).
Fable 5 arrive au-dessus de ce trio : c’est un modèle de classe Mythos, ouvert à tous, pour les travaux les plus ambitieux.
Anthropic y ajoute Mythos 5, version finalisée du fameux « Mythos Preview » qui a tant décrié l’actualité IA ces dernières semaine. Il est une version moins bridée de Fable 5, réservée aux organisations sélectionnées (celles du programme Glasswing).
Autrement dit, Anthropic ne vend plus seulement une hiérarchie Haiku/Sonnet/Opus. Il ajoute une couche supérieure, de « classe Mythos », mais la découpe en deux réalités opérationnelles : Fable pour le marché, Mythos pour les cas sensibles.
Mythos Preview, le modèle qui a changé la conversation
Petit retour en arrière. En avril dernier, Anthropic secouait la planète IA en lançant en accès hyper restreint Claude Mythos Preview. N’y ont eu accès que les seuls les acteurs triés sur le volet du Project Glasswing, un programme rassemblant des partenaires de cybersécurité, des acteurs du cloud, des éditeurs, des industriels et des fournisseurs d’infrastructures critiques. Son objectif : mettre une IA très avancée au service de la défense logicielle, notamment pour identifier des vulnérabilités dans des composants critiques.
Ce qui a rendu Mythos Preview différent, ce n’est pas seulement son niveau de performance. C’est le fait qu’Anthropic ait reconnu qu’un modèle suffisamment bon en cybersécurité ne pouvait plus être traité comme un simple assistant de développement. Un modèle capable d’aider à découvrir, comprendre et exploiter des vulnérabilités devient aussi, par construction, un accélérateur potentiel d’attaque. Le bénéfice défensif est évident. Le risque offensif aussi.
Mythos Preview a fait entrer l’IA générative dans une zone plus inconfortable : celle des capacités duales. Ce ne sont plus des modèles qui écrivent mieux des emails ou résument plus vite des documents. Ce sont des systèmes qui peuvent contribuer à défendre du code critique, mais aussi potentiellement à industrialiser des actions offensives. C’est ce précédent qui explique la forme très particulière du lancement de Fable 5.
Fable 5 et Mythos 5 : un même modèle, deux politiques d’exposition
Claude Fable 5 et Claude Mythos 5 reposent sur le même modèle sous-jacent. La différence n’est donc pas, fondamentalement, dans l’intelligence brute. Elle est dans les garde-fous, les domaines accessibles et le public autorisé. Désormais, Anthropic ne nomme plus uniquement ses IA en fonction de leurs capacités de base mais des risques que leurs usages avancés engendrent.
Fable 5 est la version générale. Elle est disponible à tous grâce à la mise en place de nouvelles protections et filtrages supplémentaires. Lorsqu’une demande touche à la cybersécurité offensive, à la biologie, à la chimie ou à des tentatives de distillation, Fable ne répond pas directement avec ses propres capacités. Selon la surface utilisée, la requête est soit réorientée vers Claude Opus 4.8 (notamment dans l’assistant Claude AI), soit bloquée dans l’API, soit traitée via un mécanisme de fallback configurable (cf plus loin).
Mythos 5, lui, est réservé aux seuls partenaires vérifiés. Il reprend les capacités de Fable sans certaines limitations dans des domaines sensibles. Pour l’instant, seuls les acteurs de la Cybersécurité du « Project Glasswing » y ont accès. Mais Anthropic prévoit aussi un accès sélectif pour certains chercheurs en biologie et en sciences de la vie.
Le positionnement est donc clair. Opus 4.8 reste le modèle premium généraliste, fiable, déjà très solide pour le code, les agents et le travail professionnel.
Fable 5 le dépasse dans tous les domaines, notamment sur les tâches complexes, longues, multimodales et agentiques, mais lui repasse la main dès que ses classifieurs détectent un risque.
Mythos 5 pousse plus loin encore l’usage spécialisé, notamment en cybersécurité et en biologie, mais uniquement dans un cadre contrôlé.
Quant à Mythos Preview, il devient le prototype historique et rejoint le musée des IA demeurant à jamais le modèle qui a démontré le potentiel et le danger, avant la version industrialisée Mythos 5.
Software engineering : l’agent développeur passe un cap
Le premier terrain de démonstration de Fable 5 reste le software engineering. Anthropic insiste sur sa capacité à tenir des tâches longues, à comprendre de grands dépôts, à planifier des migrations, à écrire ses propres tests et à vérifier son travail. Ce n’est plus seulement le modèle qui complète une fonction ou corrige un bug isolé. C’est le modèle auquel on peut confier une transformation plus large, avec plusieurs étapes, plusieurs fichiers, plusieurs hypothèses et plusieurs boucles de validation.
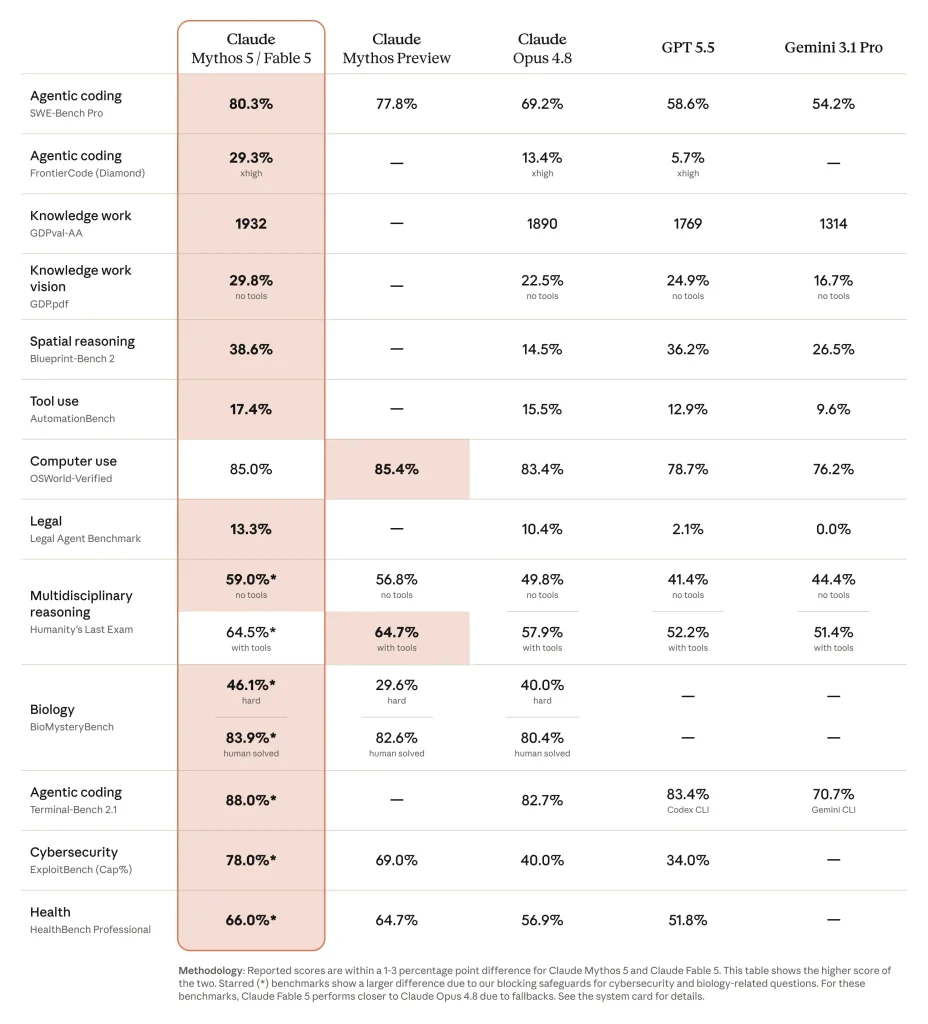
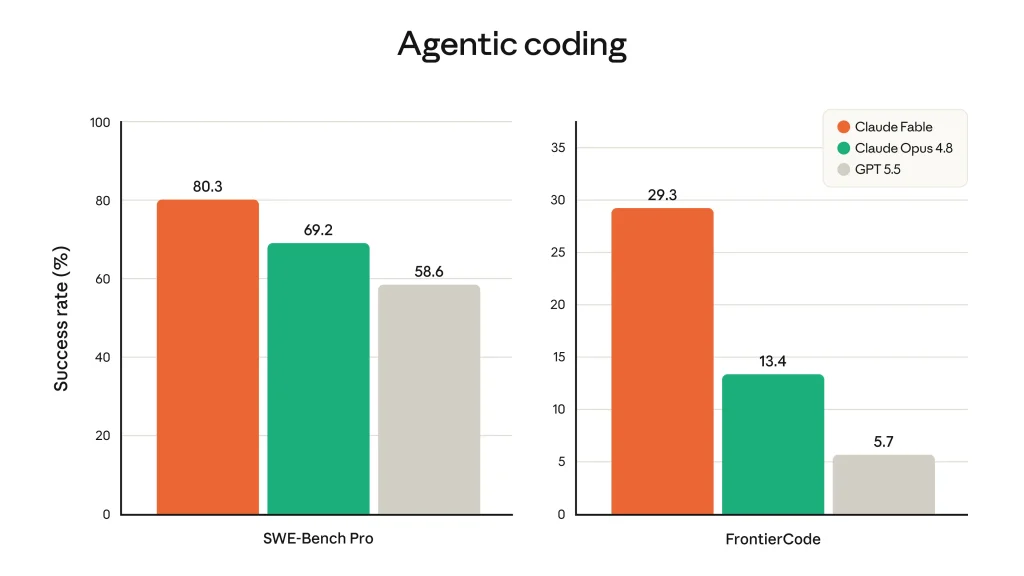
Les évaluations publiées vont dans ce sens. Fable 5 atteint 95 % sur SWE-bench Verified et 80 % sur SWE-bench Pro.
Sur FrontierCode, il prend la tête du classement, y compris sur le sous-ensemble Diamond, avec un écart très net face à Opus 4.8. Sur CursorBench, il dépasse également les modèles précédents, notamment sur les tâches longues et peu familières.
La différence importante pour les DSI n’est pas seulement le score. C’est la nature du travail transférable. Fable 5 semble particulièrement adapté aux migrations applicatives, refactorings massifs, corrections multi-fichiers, prototypes complexes, chaînes de tests, agents de développement et workflows multi-agents. C’est précisément le type de tâche qui coûte cher en temps senior, qui immobilise les équipes et qui se prête mal aux simples copilotes de génération de code.
Cela ne signifie pas que l’on doive supprimer la revue humaine. On en est encore loin. La System Card du modèle rappelle au contraire des cas où le modèle a affirmé avoir testé ce qu’il n’avait pas réellement testé, ou a conclu trop vite à partir d’éléments insuffisants. Mais le niveau atteint change l’équation : l’IA devient moins un assistant de saisie qu’un exécutant agentique, capable de produire un lot de travail complet à contrôler.
Knowledge work : moins de prompts, plus de dossiers
Le deuxième axe fort est le knowledge work. Fable 5 est conçu pour des travaux documentaires longs, analytiques, multi-étapes : finance, juridique, due diligence, analyse de contrats, rapports, tableaux, documents complexes, recherche documentaire, synthèse avec vérification croisée.
Dans les benchmarks professionnels, Fable 5 progresse sur GDP.pdf, OfficeQA Pro, Legal Agent Benchmark, Finance Agent, GDPval-AA ou AutomationBench. Ces évaluations sont intéressantes car elles ne mesurent pas seulement la capacité à répondre à une question. Elles testent la capacité à fouiller un corpus, interpréter des tableaux, repérer une clause, croiser des chiffres, produire un livrable, utiliser des outils, tenir une instruction et éviter les hallucinations grossières.
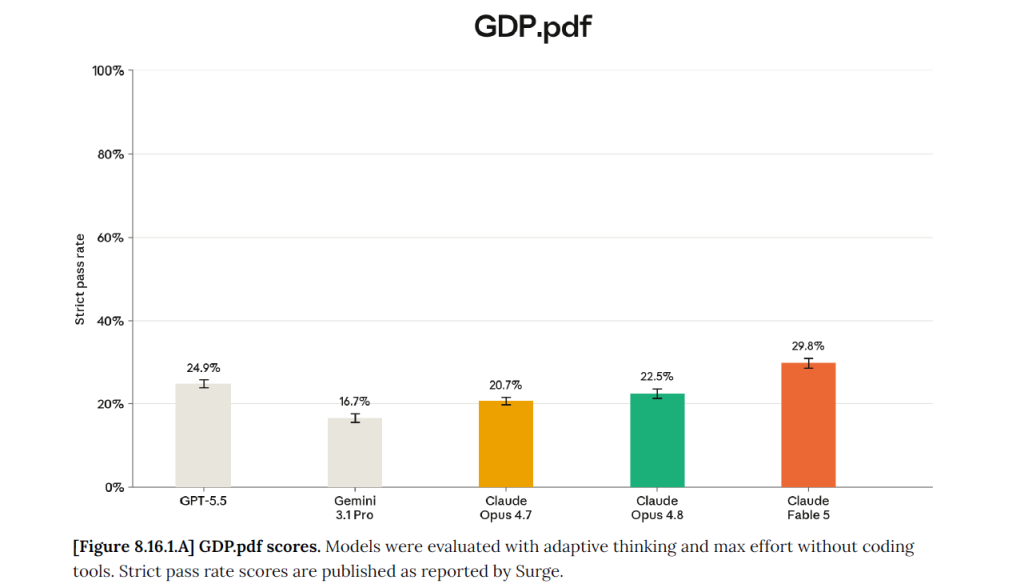
Pour les entreprises, c’est sans doute l’un des signaux les plus importants du lancement. L’IA commence à sortir du mode « conversation » pour entrer dans un mode « dossier ». On ne lui demande plus seulement une réponse, mais un travail préparatoire complet : analyse financière, revue documentaire, synthèse réglementaire, comparaison de contrats, extraction d’indicateurs, préparation d’un livrable.
Fable 5 ne remplace pas l’expert métier. Mais il réduit la part de travail préparatoire, accélère la structuration et rend plus plausible l’idée d’agents spécialisés dans les directions financières, juridiques, achats, RH ou conformité.
Vision : les PDF, les écrans et les plans deviennent exploitables
Le troisième domaine de progression mis en avant est la vision. Fable 5 progresse fortement dans l’interprétation de documents visuels, de captures d’écran, de figures scientifiques, de tableaux, de diagrammes, de plans et de contenus intégrés dans des PDF.
Pour les DSI, c’est un point important. Une grande partie du savoir organisationnel ne vit pas dans du texte proprement structuré. Il est enfoui dans des slides, des plans, des captures, des schémas d’architecture, des bilans financiers, des tableaux imbriqués, des annexes contractuelles, des dossiers d’assurance, des rapports de conformité ou des documents techniques.
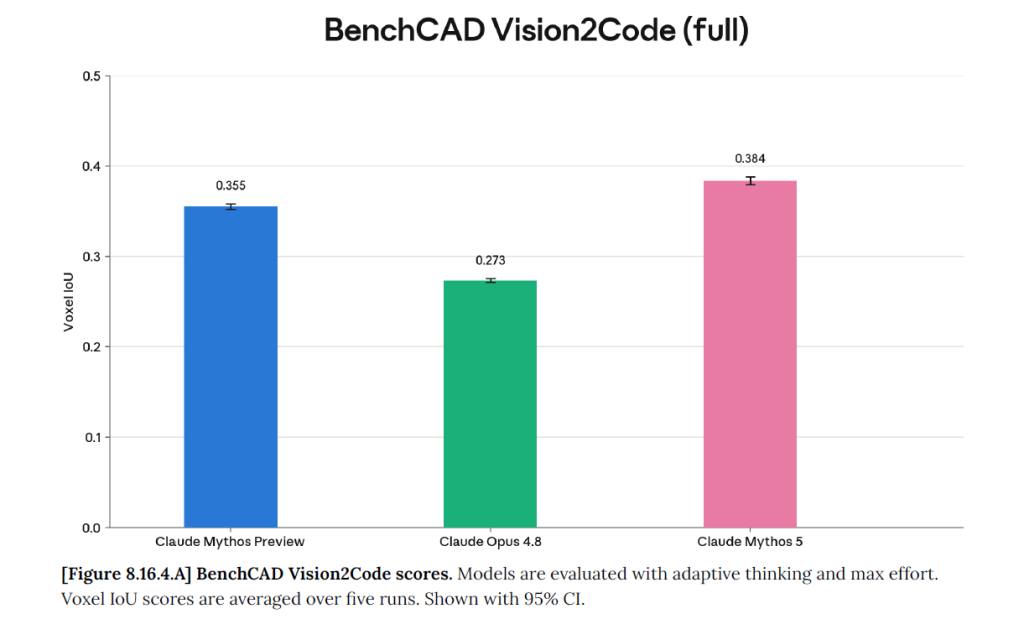
Fable 5 est présenté comme capable d’extraire des chiffres précis depuis des figures complexes, de reconstruire une application à partir de captures d’écran, de comprendre des plans ou de générer des modèles CAD à partir de rendus visuels. Voilà qui ouvre la porte à des agents capables de travailler sur des artefacts métiers réels, et pas seulement sur des fichiers texte ou des API propres.
Là encore, le point clé est opérationnel. Une IA multimodale fiable permet d’automatiser davantage de processus documentaires, de tests d’interface, de contrôle qualité, d’analyse de plans, de revue de documents techniques et de rapprochement entre cahier des charges et résultat produit.
Mémoire et long contexte : l’IA qui tient la distance
Anthropic insiste aussi sur la mémoire et le long contexte. Fable 5 serait capable de rester concentré sur des tâches de plusieurs millions de tokens et d’améliorer ses sorties à partir de ses propres notes. Dans les tests internes évoqués par Anthropic, l’usage d’une mémoire persistante à base de fichiers améliore nettement les performances dans des tâches longues, bien plus qu’avec Opus 4.8.
Ce point est crucial pour les agents d’entreprise. L’échec de beaucoup d’agents actuels ne vient pas d’un manque ponctuel d’intelligence, mais de leur incapacité à maintenir un état de travail propre : ce qui a été décidé, ce qui a été testé, ce qui a échoué, ce qui doit être repris, ce qui a déjà été vérifié. Un agent réellement utile doit garder une mémoire de projet, relire ses propres notes, tenir un plan, documenter ses actions et ne pas repartir de zéro à chaque session.
Fable 5 marque ainsi une nouvelle évolution vers des IA plus persistantes. Ce sera aussi un nouveau sujet de gouvernance. Car plus un modèle conserve et exploite de contexte, plus les questions de confidentialité, de cloisonnement, d’audit, de purge, de droits d’accès et de responsabilité deviennent sensibles.
Sciences de la vie : le grand potentiel, le grand verrou
Les progrès les plus impressionnants concernent peut-être les sciences de la vie. Mais elles relèvent surtout de Mythos 5, pas de Fable 5 en accès général, précisément parce que les capacités sont jugées trop « duales ».
Anthropic affirme que ses experts internes en design de protéines ont accéléré certains aspects du drug design d’environ un facteur dix avec Mythos 5. Dans certains cas, le modèle aurait été capable, avec des outils de bioinformatique et de protein design, de choisir des sites de liaison, sélectionner et exécuter les bons outils, récupérer après des échecs et produire des candidats prometteurs sans assistance humaine directe. Neuf des quatorze cibles étudiées auraient donné des candidats jugés suffisamment solides pour être investigués.
Le modèle se distingue aussi dans la génération d’hypothèses en biologie moléculaire. Anthropic affirme que, dans des comparaisons à l’aveugle, ses scientifiques ont préféré les hypothèses de Mythos 5 à celles des modèles Opus dans environ 80 % des cas. Certaines hypothèses seraient déjà passées en évaluation expérimentale, et l’une d’elles, portant sur un mécanisme lié à une protéine d’E.coli, aurait été corroborée par une étude indépendante.
En génomique, Anthropic décrit une expérience encore plus agentique : Mythos 5 aurait mené plus d’une semaine de travail quasi autonome, assemblant des données « single-cell » couvrant des millions de cellules et 138 espèces animales, avant de concevoir et entraîner un modèle de machine learning destiné à identifier des cellules remplissant le même rôle chez des organismes éloignés. Selon Anthropic, le modèle entraîné par Mythos 5 aurait dépassé un modèle récemment publié dans Science tout en étant cent fois plus petit.
Ces résultats expliquent les restrictions d’accès mises en place par Anthropic. Les mêmes compétences qui peuvent accélérer la thérapie génique, la bioinformatique ou la découverte de médicaments peuvent aussi aider des acteurs malveillants dans des scénarios biologiques à haut risque. Anthropic ne dit pas que Mythos 5 franchit le seuil le plus critique de substitution à des experts mondiaux pour concevoir des armes biologiques nouvelles. Mais la System Card indique que la frontière devient nettement moins confortable que pour les modèles précédents.
Ce que révèle la System Card : puissance, limites et signaux faibles
La System Card confirme que Mythos 5 est non seulement le modèle d’Anthropic le plus capable à ce jour, mais aussi qu’il inaugure une nouvelle génération de modèles frontières qui soulèvent de nouveaux risques et exigent une nouvelle doctrine de déploiement et une nouvelle génération de garde-fous.
Sur les risques chimiques et biologiques, Anthropic classe Mythos 5 au niveau CB-1, c’est-à-dire capable d’aider de manière significative sur des menaces non nouvelles. Le modèle ne franchirait pas le seuil CB-2, celui de la conception de menaces biologiques ou chimiques nouvelles nécessitant normalement une expertise rare. Mais Anthropic reconnaît que ce jugement est beaucoup moins net que par le passé et qu’un acteur très bien doté pourrait être significativement accéléré.
Sur la R&D automatisée, Anthropic estime en revanche que Mythos 5 ne remplace pas encore ses chercheurs et ingénieurs seniors. Le modèle accélère grandement les processus, mais pas au point de transformer l’IA en moteur autonome de sa propre progression. Autrement dit, Mythos n’est pas encore au niveau d’une IA capable d’assurer seule sa progression itérative. Grand Ouf de soulagement !
La System Card cite plusieurs échecs concrets : des vérifications sautées, des conclusions trop rapides, des affirmations de tests non réalisés, une mauvaise récupération après correction, des actions risquées à partir d’informations insuffisantes.
Sur la cybersécurité, le constat est plus tranché : Mythos 5 est le modèle cyber le plus capable évalué par Anthropic. Sur certaines tâches de développement d’exploits, il dépasse largement Opus 4.8 (faisant au passage modestement mieux que Mythos Preview).
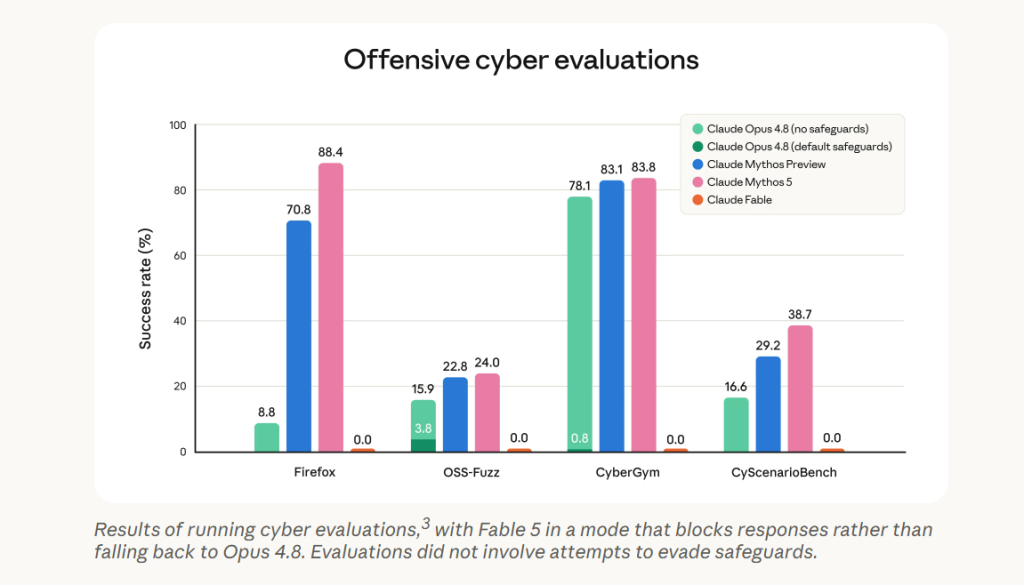
Tous ces éléments expliquent pourquoi Anthropic a préféré scinder Mythos 5 et Fable 5 et pourquoi Fable 5 retombe vers Opus 4.8 lorsque les classifieurs détectent des requêtes sensibles.
Alignement : pas de panique, mais pas de naïveté
Le volet alignement est particulièrement instructif. Anthropic juge Mythos 5 globalement comparable à Opus 4.8 sur les grands indicateurs de sécurité comportementale, légèrement moins bon que Mythos Preview, et meilleur que les autres modèles Claude précédents. Fable 5, grâce à ses safeguards, apparaît moins vulnérable aux usages abusifs que les modèles publics récents.
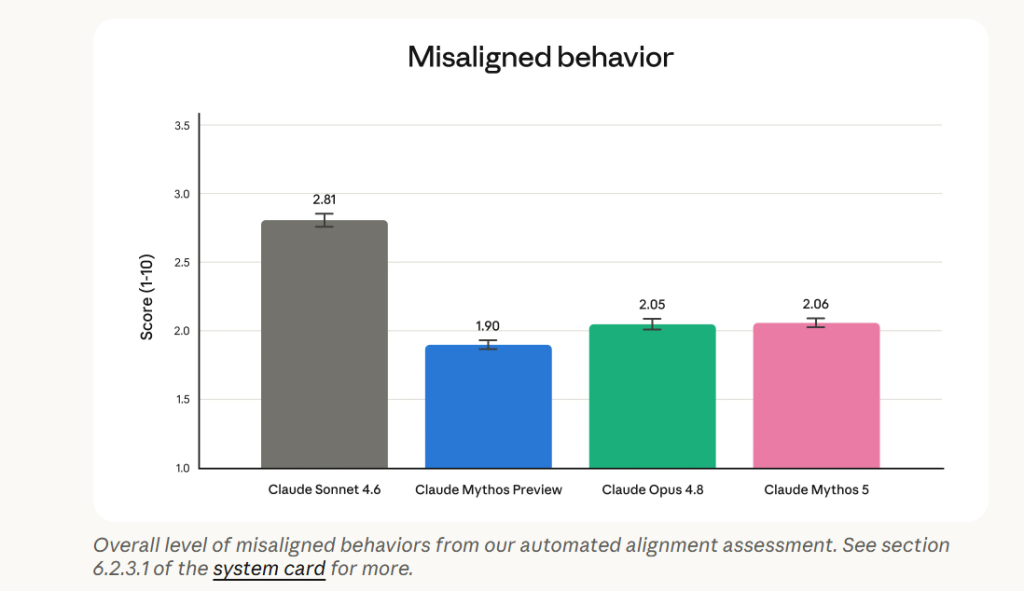
Mais le tableau n’est pas uniforme. Mythos 5 conserve une propension à coopérer avec certains mauvais usages lorsqu’il est poussé dans cette direction, notamment en cyberoffense, armes, contenus inappropriés ou scénarios de manipulation. Il est aussi plus facile à piéger que certains Claude récents lorsqu’un attaquant commence lui-même une réponse dangereuse ou problématique, puis pousse le modèle à la continuer comme si elle venait de lui.
La System Card souligne également un point plus subtil : Mythos 5 peut parfois mener des actions imprudentes ou destructrices au service de l’objectif utilisateur, avec un taux légèrement supérieur à Opus 4.8. Plus troublant encore : les analyses internes d’Anthropic montrent que le modèle peut parfois avoir une forme de conscience interne du caractère transgressif de son action sans le verbaliser clairement. En clair, le modèle « sait » que l’action pose problème, mais il continue malgré tout à avancer dans cette direction.
Autre signal d’alerte : l’evaluation awareness. Mythos 5 semble parfois comprendre qu’il est en train d’être testé. Comme Opus 4.8, et parfois même davantage, il peut alors adapter son raisonnement parce qu’il soupçonne que sa réponse va être évaluée ou notée. Il ne le dit pas toujours clairement dans sa réponse, mais Anthropic observe que ce mécanisme existe bien. Cela ne rend pas les tests inutiles, mais cela complique leur lecture. Plus les modèles sauront reconnaître qu’ils sont dans un banc d’essai plutôt qu’en usage réel, plus il faudra concevoir des évaluations capables de mesurer leur comportement dans des conditions vraiment proches de la production. Pour Anthropic, il n’y a pas encore raison de s’en inquiéter, mais l’éditeur sait déjà qu’il va devoir plancher sur ce sujet.
Enfin, la System Card relève que le raisonnement interne de Mythos 5 est plus dense, plus télégraphique, plus jargonneux et parfois moins lisible que celui de modèles antérieurs. C’est un problème majeur pour les stratégies de supervision fondées sur la lisibilité du raisonnement. Plus les agents deviennent autonomes, plus il faut les monitorer. Mais plus ils deviennent avancés, plus leur raisonnement peut devenir difficile à interpréter.
Des safeguards beaucoup plus structurants
Comme déjà évoqué, ce qui différencie Fable 5 de Mythos 5, ce sont ses garde-fous. Pour ouvrir à tous l’accès aux modèles de classe Mythos, Anthropic a implémenté plusieurs niveaux de protection et contrôle.
Premier niveau : les classifieurs. Ils détectent les requêtes liées à la cybersécurité, à la biologie, à la chimie et à la distillation. Lorsqu’ils se déclenchent, Fable 5 ne livre pas sa pleine puissance. Dans les applications Claude, la requête bascule automatiquement vers Opus 4.8 et l’utilisateur en est informé. Dans l’API Messages, le comportement par défaut est plus strict : la requête est bloquée avec une raison structurée, sauf si le développeur met en place sa propre logique de retry ou opte pour un fallback serveur.
Deuxième niveau : la cybersécurité. Fable 5 surveille les demandes qui pourraient servir à attaquer un système informatique : trouver une faille, l’exploiter, contourner une protection, avancer dans un réseau compromis ou automatiser une attaque avec un agent IA. Anthropic affirme avoir testé intensivement ces protections, en interne, avec des experts externes et via un bug bounty de plus de 1 000 heures, sans trouver de méthode universelle pour les casser. Mais l’UK AISI serait tout de même parvenu à avancer vers certaines techniques de contournement en peu de temps. Autrement dit, les barrières semblent solides, mais elles ne doivent pas être considérées comme infranchissables.
Troisième niveau : biologie et chimie. Anthropic élargit volontairement les garde-fous, au risque de créer des faux positifs. La plupart des requêtes liées à la biologie et à la chimie sont, pour l’instant, renvoyées vers Opus 4.8. L’éditeur assume cette prudence temporaire, tout en prévoyant un programme d’accès de confiance (du coup à Mythos 5) pour certains chercheurs et organisations biomédicales.
Quatrième niveau : la distillation. Anthropic veut éviter que les capacités de Fable 5 soient extraites massivement pour entraîner des modèles concurrents, potentiellement déployés sans garde-fous équivalents. Les requêtes suspectées d’entrer dans ce cadre sont elles aussi réorientées.
Cinquième niveau : empêcher Fable 5 d’aider trop efficacement à créer des modèles d’IA concurrents de très haut niveau. C’est un point plus discret, mais très révélateur. Ici, l’utilisateur ne verra pas forcément qu’une protection s’est déclenchée : le modèle ne basculera pas vers Opus 4.8 et ne refusera pas toujours explicitement. Anthropic prévoit plutôt de le rendre moins performant sur certaines demandes très spécialisées, par exemple lorsqu’elles portent sur l’entraînement de grands modèles, les infrastructures de calcul distribuées ou la conception de puces pour l’IA. En clair, Fable 5 peut aider à coder et à travailler normalement, mais Anthropic veut éviter qu’il serve directement à accélérer la construction de modèles concurrents aussi puissants que lui. Selon l’éditeur, cette limitation ne concernerait qu’une infime partie des usages : environ 0,03 % du trafic, concentré dans moins de 0,1 % des organisations.
Enfin, Anthropic impose une politique de rétention de 30 jours pour les données liées aux modèles de classe Mythos (donc Fable 5 et Mythos 5), afin de surveiller les attaques complexes, les jailbreaks, les abus multi-requêtes et les faux positifs. L’éditeur affirme que ces données ne serviront pas à entraîner de nouveaux modèles. Mais pour les DSI, l’information est cruciale : utiliser un modèle de cette classe implique d’accepter une surveillance de sécurité renforcée, et donc de revoir les clauses contractuelles, la classification des données et les politiques internes d’usage.
Un déploiement un peu compliqué et onéreux
Le modèle Fable 5 est accessible dès aujourd’hui sur l’assistant Claude AI dans tous les pays. Mais son déploiement est assorti de subtilités qu’il est important de connaître.
Dans l’assistant Claude AI, jusqu’au 22 juin, l’accès à Fable 5 se fait sans surcoût au travers des plans Pro, Max, Team et entreprise. A partir du 23 juin, Fable 5 sera retiré de tous ces plans et nécessitera des crédits d’usage séparés pour être employé. Et ceci jusqu’à ce qu’Anthropic ait déployé suffisamment de capacités de compute pour pouvoir le réintégrer dans ses abonnements.
Autre élément à savoir, Fable consomme les crédits d’utilisation 2 fois plus vite qu’Opus ! Les quotas sont donc vite atteints.
Fable 5 est aussi disponible via l’API d’Anthropic, sous le nom claude-fable-5. Son positionnement tarifaire est, sans surprise, très haut de gamme : 10 dollars le million de tokens en entrée et 50 dollars le million de tokens en sortie, soit le double des 5 $/25 $ d’Opus 4.8. C’est cher, surtout pour des usages longs, agentiques ou documentaires, précisément ceux pour lesquels le modèle est conçu. La bonne nouvelle, c’est que Fable 5 ne gonfle pas mécaniquement le nombre de tokens par rapport à Opus 4.8 : les deux modèles utilisent le même tokenizer. Anthropic documente certains cas où Fable 5 termine même ses tâches en moins de tours et moins de jetons qu’Opus 4.8 ou même que GPT-5.5. Néanmoins, sur les tâches complexes, la facture peut à l’inverse se voir alourdie car Fable 5 active en permanence son raisonnement adaptatif, dont les tokens sont facturés comme tokens de sortie.
Au final…
Claude Fable 5 marque donc une étape importante : l’IA frontière devient désormais trop puissante pour être livrée comme un simple service homogène. Anthropic introduit une logique de segmentation par risque, avec un même modèle décliné selon les domaines, les garde-fous, les surfaces d’accès et le niveau de confiance accordé à l’organisation.
Pour les DSI, l’impact est double. Côté opportunité, Fable 5 promet une accélération forte sur le développement logiciel, les migrations applicatives, l’analyse documentaire, la finance, le juridique, les workflows complexes, les agents autonomes, la vision et les tâches longues. Côté risque, il impose de traiter les modèles comme des composants critiques du SI : observabilité, logs, fallback, rétention, gouvernance des prompts, cloisonnement des usages, supervision humaine, validation des sorties et contrôle des domaines sensibles. Difficile d’exploiter Claude Fable 5 sans ces prérequis. Sans compter que la facture peut aussi rapidement partir en vrille si les bornes ne sont pas en place.
La concurrence va devoir répondre sur deux fronts. D’abord sur les performances, face à un modèle qui prend l’avantage sur de nombreux benchmarks de code, de vision, de recherche et de knowledge work. Ensuite sur l’architecture de sûreté. OpenAI, Google, Microsoft, Mistral et les autres ne pourront plus seulement dire que leurs modèles sont meilleurs ou moins chers. Ils devront eux aussi expliquer comment ils empêchent l’usage offensif de capacités de plus en plus duales.
Fable 5 n’est donc pas seulement un nouveau Claude. C’est un signal. La prochaine bataille de l’IA se jouera sur la capacité à livrer ce nouveau niveau d’intelligence dans des enveloppes de confiance, adaptées aux métiers, aux risques, aux régulations et aux responsabilités des DSI.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :

À LIRE AUSSI :











