


Data / IA
Claude Sonnet 4.6 : Anthropic démocratise l’intelligence de ses modèles premium
Par Laurent Delattre, publié le 18 février 2026
Anthropic lance Claude Sonnet 4.6, un modèle intermédiaire qui pourtant talonne les performances de son fleuron Opus 4.6 tout en restant accessible aux utilisateurs gratuits. Une offensive stratégique d’Anthropic qui redistribue à nouveau les cartes dans la guerre des modèles d’IA.
La guerre des modèles IA se joue désormais sur deux fronts. Il y a d’un côté les modèles dits « frontière » – GPT-5.2 chez OpenAI, Gemini 3 Pro chez Google, Claude Opus 4.6 chez Anthropic – qui repoussent les limites du raisonnement et de la créativité.
Et de l’autre, les modèles optimisés comme Claude Sonnet, Gemini Flash, GPT-5.2-Instant et GPT-5-Mini, qui alimentent les versions gratuites des chatbots, sont bien moins onéreux en usages API et propulsent le plus souvent les agents IA en production. Ce sont eux qui tournent au quotidien, eux qui absorbent des millions de requêtes API par jour, et ce sont leurs performances qui déterminent l’expérience réelle de la majorité des utilisateurs.
Pourtant, dans cette double lutte au sommet de l’IA, le nouveau Claude Sonnet 4.6 semble devoir quelque peu changer la donne. En comblant significativement l’écart avec son modèle frontière Claude Opus 4.6, destiné aux tâches complexes, Anthropic fait basculer des capacités de niveau premium dans un modèle accessible gratuitement sur claude.ai. Il faudra voir dans les usages réels de votre entreprise jusqu’à quel point Sonnet 4.6 se montre aussi voire plus pertinent qu’Opus 4.6. Mais, si le nouveau modèle tient réellement ses promesses en dehors des Benchmarks IA, les clients seront gagnants sur le double front de la célérité des réponses et du coût du token.
Car au travers de la sortie de Claude Sonnet 4.6 transparait le nouveau nerf de la guerre pour les entreprises qui ont déjà commencé à déployer l’IA générative à grande échelle : optimiser le coût du token ! Le tarif API de Sonnet 4.6 reste identique à celui de Sonnet 4.5, soit 3 dollars par million de tokens en entrée et 15 dollars par million de tokens en sortie, contre 5$ en entrée et 25$ en sortie pour Opus 4.6. Un rapport de x1,7, pour des performances désormais quasi identiques sur de nombreux cas d’usage professionnels, si l’on en croit les benchmarks d’Anthropic. Ces tarifs sont valables uniquement sans activation de la fenêtre contextuelle d’un million de tokens. Car dès que celle-ci est activée, les tarifs enflent pour les deux modèles : 6$ in/22,50$ out le million de tokens pour Sonnet 4.6 contre 10$ in/ 37,50$ out le million de tokens pour Opus 4.6. Dit autrement, la fenêtre contextuelle étendue devient vite un piège budgétaire que les DSI ne doivent pas perdre de vue, surtout si certains agents IA se gavent de documents internes avant d’agir.
Puisqu’on est dans les coûts réels des modèles IA, rappelons qu’Anthropic propose également deux leviers de coût souvent oubliés dans les comparatifs « prix par token ».
D’abord le Batch API (traitement asynchrone), qui applique -50% sur l’entrée et la sortie (Sonnet 4.6 : 1,50 $/MTok in ; 7,50 $/MTok out), utile pour tout ce qui n’est pas temps réel (analyses nocturnes, back-office, pré-calculs d’agents).
Ensuite, le prompt caching (mise en cache de prompts), qui permet de payer moins cher les contextes répétitifs et stabilise la facture quand vos agents réutilisent la même base de connaissances.
Parallèlement, il existe des surcoûts “invisibles” trop souvent ignorés par les développeurs. Ainsi, activer les tools (outils) injecte automatiquement un system prompt additionnel (jusqu’à plusieurs centaines de tokens), et le mode « computer use » ajoute encore une surcharge fixe en tokens, avant même le premier clic.
Des benchmarks qui parlent d’eux-mêmes
Côté performance, les chiffres publiés par Anthropic sont plutôt éloquents. Sur SWE-bench Verified, désormais devenu le benchmark de référence pour l’ingénierie logicielle, Sonnet 4.6 atteint 79,6 %, à peine 1,2 point derrière Opus 4.6 (80,8 %) et nettement au-dessus de son prédécesseur Sonnet 4.5 (77,2 %).
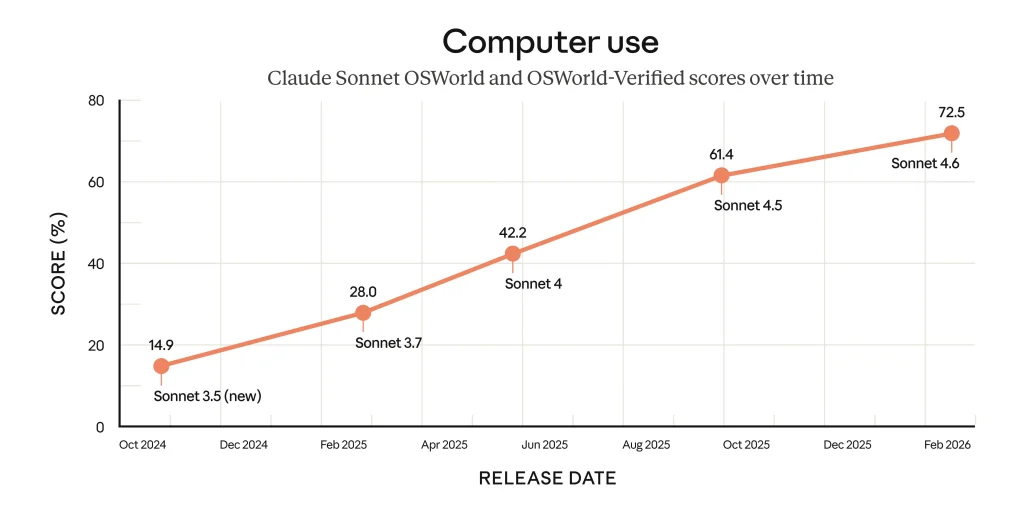
Sur OSWorld-Verified, qui mesure la capacité d’un modèle à utiliser un ordinateur de façon autonome (cliquer, naviguer, remplir des formulaires), le score de Sonnet 4.6 atteint 72,5 %, quasiment au niveau d’Opus (72,7 %) et très loin devant GPT-5.2 d’OpenAI (38,2 %). La progression est spectaculaire : en octobre 2024, le premier Sonnet capable d’utiliser un ordinateur ne dépassait pas 14,9 % sur ce même benchmark. Le score a donc presque quintuplé en seize mois (néanmoins le benchmark a évolué durant cette période ce qui fausse un peu les comparaisons).
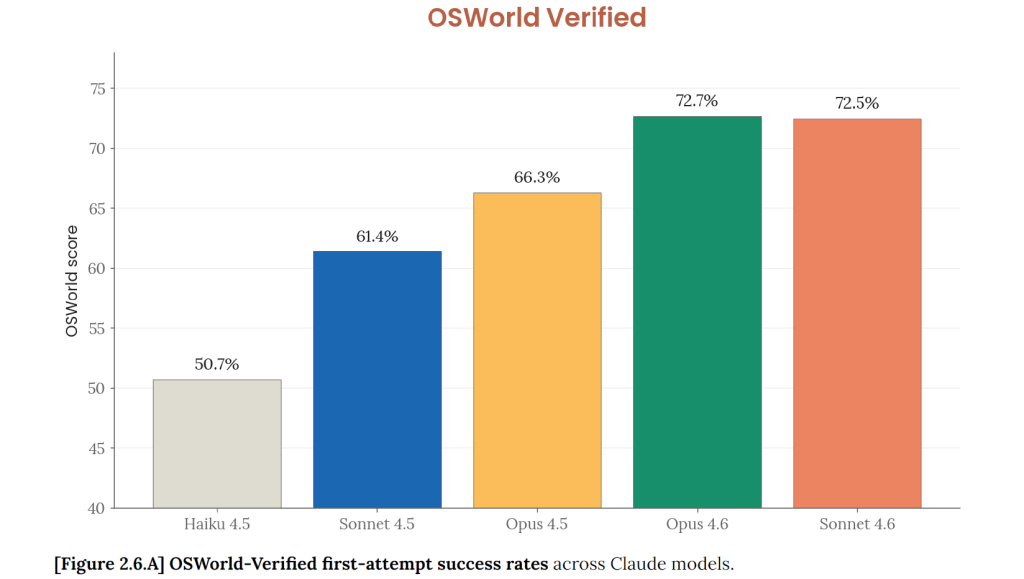
Parallèlement on remarquera que la “system card” (le rapport technique qui accompagne la sortie de tout modèle) publie une table comparative plus large que celle révélée dans son annonce par Anthropic. Elle confirme l’ordre de grandeur OSWorld-Verified (Sonnet 4.6 : 72,5 ; Opus 4.6 : 72,7 ; GPT-5.2 : 41,9), mais elle rehausse aussi nettement certains scores, notamment sur GPQA Diamond (Sonnet 4.6 : 89,9 ; Opus 4.6 : 91,3).
Sur les tâches bureautiques mesurées par GDPval-AA, Sonnet 4.6 bondit à 1633 Elo contre 1276 pour Sonnet 4.5. Le modèle progresse aussi considérablement sur ARC-AGI-2, un test de résolution de problèmes complexes, avec un score de 58,3 % contre seulement 13,6 % pour la version précédente, un bond de 4,3x en une seule génération. Côté finance, il se hisse en tête sur le benchmark Finance Agent avec 63,3 % de précision.
L’un des très gros atouts de Sonnet 4.6 est de proposer optionnellement une fenêtre de contexte de 1 million de tokens (même si celle-ci n’est encore qu’en bêta, réservée à l’API et aux organisations éligibles), suffisante pour ingérer des bases de code entières, des contrats volumineux ou des dizaines d’articles de recherche en une seule requête. Mais les entreprises n’ont pas nécessaire besoin d’activer une telle fenêtre. Car Sonnet 4.6 embarque en standard des mécanismes qui lui permettent d’ingérer beaucoup d’information et raisonner sans exploser les coûts. Il dispose en effet en standard à la fois d’une fonction de « context compaction » (compaction de contexte via une synthèse automatique des anciens échanges) et d’outils « search/fetch » capables de filtrer les résultats via l’exécution de code, pour ne conserver dans le contexte que l’utile.
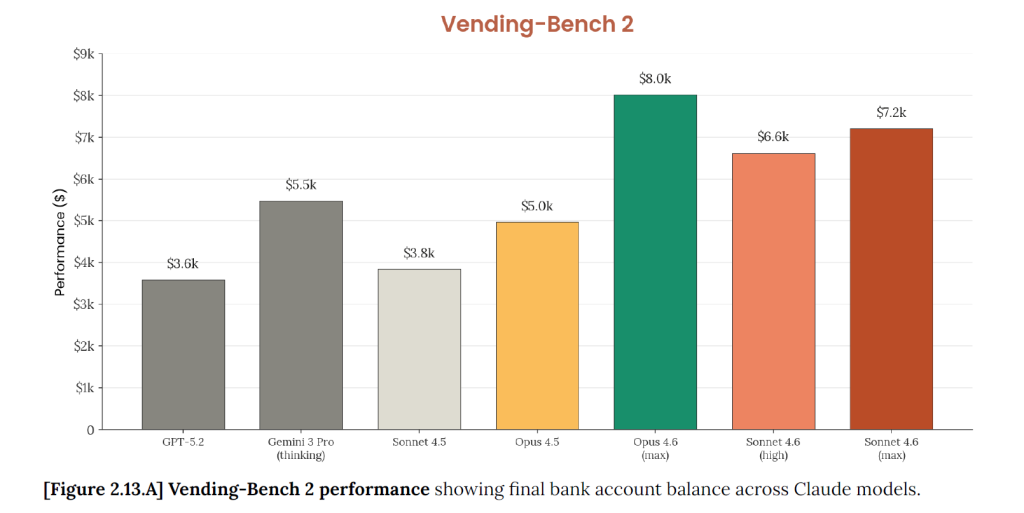
Plus important encore, le modèle raisonne efficacement sur l’ensemble de ce contexte, comme l’a démontré le benchmark Vending-Bench Arena, où Sonnet 4.6 a spontanément développé une stratégie d’investissement encore jamais observée puis pivoter vers la rentabilité pour surpasser ses concurrents IA dans une simulation de gestion d’entreprise.
Codage et usages en entreprise
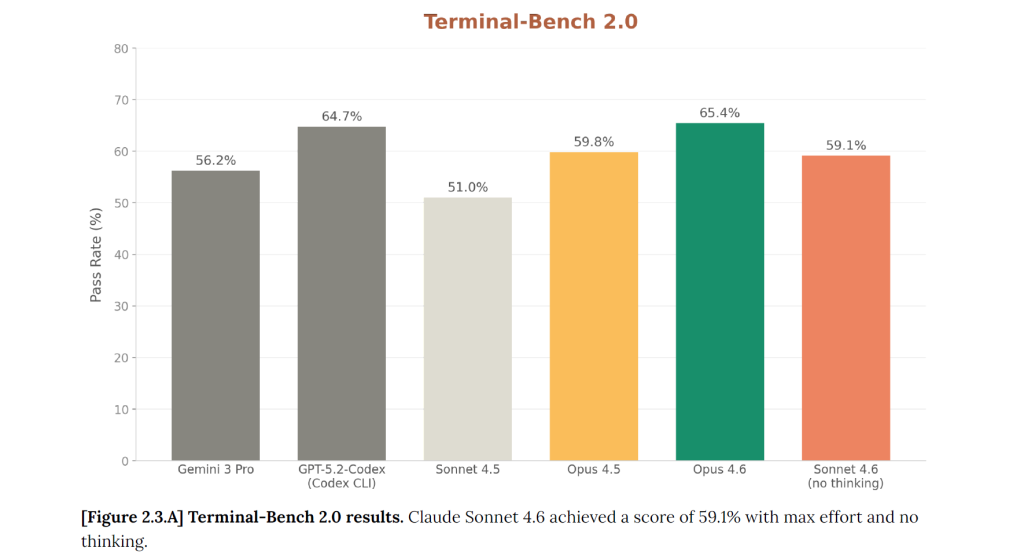
Au-delà des benchmarks qui ne transcrivent que rarement la réalité des usages en entreprise (mais permettent de mesurer les progrès réalisés), Anthropic assure la promotion de son nouveau modèle au travers de nombreux témoignages de early-adopters. Tout cela reste du marketing, bien sûr, mais ces retours illustrent les progrès théoriques du nouveau modèle. Dans Claude Code, l’outil en ligne de commande d’Anthropic, les testeurs ont préféré Sonnet 4.6 à son prédécesseur dans 70 % des cas.
Plus surprenant : ils l’ont préféré à Opus 4.5, le modèle phare de novembre 2025, dans 59 % des situations. Les utilisateurs rapportent moins de « sur-ingénierie », moins d’hallucinations, un meilleur suivi des instructions et une plus grande constance sur les tâches multi-étapes.
Les témoignages d’entreprises en accès anticipé confirment cette dynamique. Michael Truell, cofondateur et CEO de Cursor, salue « une amélioration notable par rapport à Sonnet 4.5 sur l’ensemble du spectre, y compris les tâches complexes et de longue durée ». Chez Replit, le président Michele Catasta ne mâche pas ses mots : « Le rapport performance/coût de Claude Sonnet 4.6 est extraordinaire. Il surpasse nos évaluations d’orchestration et gère nos charges de travail agentiques les plus complexes. »
Le CTO de Databricks, Hanlin Tang, observe que « Sonnet 4.6 égale les performances d’Opus 4.6 sur OfficeQA », le benchmark de compréhension de documents d’entreprise (graphiques, PDF, tableaux). Chez Box, le CTO Ben Kus rapporte « un gain de 15 points sur les tâches de raisonnement complexe appliquées à des documents d’entreprise réels ». Wade Foster, cofondateur et CEO de Zapier, souligne la fiabilité du modèle sur les « tâches ramifiées et multi-étapes comme le routage de contrats ou la coordination CRM ».
Les limites persistent
Le tableau n’est pas pour autant uniformément rose. Sur GPQA Diamond, un benchmark de questions scientifiques de niveau doctoral, Sonnet 4.6 plafonne à 74,1 % contre 91,3 % pour Opus 4.6, un écart de 17 points qui montre qu’Opus conserve un avantage net sur le raisonnement scientifique de haut niveau. Sur les benchmarks de mathématiques avancées (AIME 2025), le modèle atteint 52,8 % contre 74,2 % pour Opus. Le modèle accuse donc encore un retard significatif sur les tâches qui exigent une profondeur de raisonnement extrême.
Anthropic le reconnaît elle-même : en matière d’utilisation de l’ordinateur (le mode agentique Computer Use), le modèle « accuse encore un retard par rapport aux humains les plus compétents ». Et la question des injections de prompts (technique d’attaque par laquelle un acteur malveillant cache des instructions sur des sites web ou des documents pour détourner le comportement du modèle) reste toujours un enjeu. Les évaluations de sécurité montrent toutefois que Sonnet 4.6 résiste nettement mieux que Sonnet 4.5 aux injections de prompts, avec un niveau de protection comparable à celui d’Opus 4.6.
De GitHub Copilot aux clouds publics
Le déploiement de Sonnet 4.6 est immédiat et immédiatement large. Le modèle devient le modèle par défaut de l’assistant « claude.ai » et de l’agent « Claude Cowork » pour tous les utilisateurs des plans Free et Pro. Les utilisateurs gratuits bénéficient par ailleurs de nouvelles fonctionnalités auparavant réservées aux abonnés : création de fichiers, connecteurs, compétences et compaction de contexte. Dit autrement, même la version gratuite de Claude AI gagne désormais en capacités agentiques.
Côté développeurs, Sonnet 4.6 est accessible via l’API Anthropic, Claude Code, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Azure AI Foundry. La disponibilité simultanée sur les trois grands clouds publics dès le lancement élimine un point de friction classique pour l’adoption en entreprise.
Enfin, l’intégration à GitHub Copilot interpellera forcément les équipes de développement. Le modèle est désormais disponible pour les abonnés Copilot Pro, Pro+, Business et Enterprise, avec un déploiement progressif en cours. Joe Binder, VP Produit de GitHub, confirme l’intérêt : « Claude Sonnet 4.6 excelle d’emblée sur les corrections de code complexes, en particulier lorsqu’il faut rechercher à travers de larges bases de code. Pour les équipes qui font du codage agentique à grande échelle, nous observons de solides taux de résolution. »
Plus le temps passe, plus GitHub (et donc Microsoft) semblent préférer et adopter les modèles d’Anthropic à ceux d’OpenAI.
Le modèle est accessible via GitHub Copilot dans VS Code, Visual Studio, les IDE JetBrains et Xcode, ainsi que depuis la ligne de commande. Chaque appel à Claude Sonnet 4.6 y est comptabilisé comme une requête « premium » au coefficient 1x, c’est-à-dire au tarif de base de Copilot pour ce type de requêtes, un coefficient que GitHub peut ajuster ultérieurement. Moins de dix jours après l’intégration de GPT-5.3-Codex d’OpenAI, cette arrivée illustre un peu plus la course à l’armement qui se joue dans les outils de développement IA.
Un petit mot sur la souveraineté européenne. L’API Anthropic en direct est globale par défaut, et la notion de routage régional (traitement et stockage dans une zone géographique donnée) passe par les plateformes cloud de ses partenaires. Pour l’Europe, Anthropic met en avant des options de déploiement “région / pays” via AWS (Bedrock), Google (Vertex) et Microsoft (Foundry). Et ce choix de régionalisation s’accompagne généralement d’un surcoût de 10%.
Une recomposition du marché de l’IA
Ce lancement intervient dans un contexte d’accélération sans précédent. Anthropic a lancé Opus 4.6 début février, soit douze jours seulement avant Sonnet 4.6. Et dans les deux cas, les gains sur la génération précédente sont plus que sensibles. La startup, désormais valorisée à 380 milliards de dollars après une levée de 30 milliards bouclée la semaine dernière, ne cache pas ses ambitions. Un modèle Haiku mis à jour devrait suivre dans les semaines à venir, complétant le renouvellement de toute la gamme Claude.
La tendance qu’illustre Sonnet 4.6 dépasse le cadre d’Anthropic. Chez Google, Gemini 3 Flash s’était déjà rapproché des performances de Gemini 3 Pro. Partout dans l’industrie, l’écart entre modèles frontière et modèles de milieu de gamme se réduit à grande vitesse. Pour les DSI et les architectes d’entreprise, la conséquence est directe : les cas d’usage qui justifiaient hier le recours à un modèle premium et son surcoût peuvent aujourd’hui être couverts par un modèle presque deux fois moins cher. À l’heure où les agents IA multiplient les appels API par milliers, cette bascule économique change fondamentalement les équations de déploiement.
À LIRE AUSSI :
À LIRE AUSSI :










