Data / IA
Comment SubQ compte diviser votre facture IA par 1000 !
Par Laurent Delattre, publié le 11 mai 2026
Et si le problème des LLM n’était pas seulement de mieux raisonner, mais de lire plus grand sans ruiner l’infrastructure et les budgets IT ? Le nouveau modèle SubQ de la startup Subquadratic promet de casser le réflexe du « tout compare tout » du principe des LLMs actuels grâce à une « attention éparse », avec des implications directes pour le RAG, les agents de code et les données métier.
Ce n’est certainement pas « le lancement le plus important depuis ChatGPT » comme la presse américaine tend à la présenter. Mais l’annonce de Subquadratic et de son modèle de raisonnement SubQ 12B mérite attention parce qu’elle vise à corriger l’un des défauts structurels des grands modèles actuels : leur difficulté à traiter de très longs contextes sans faire exploser les coûts.
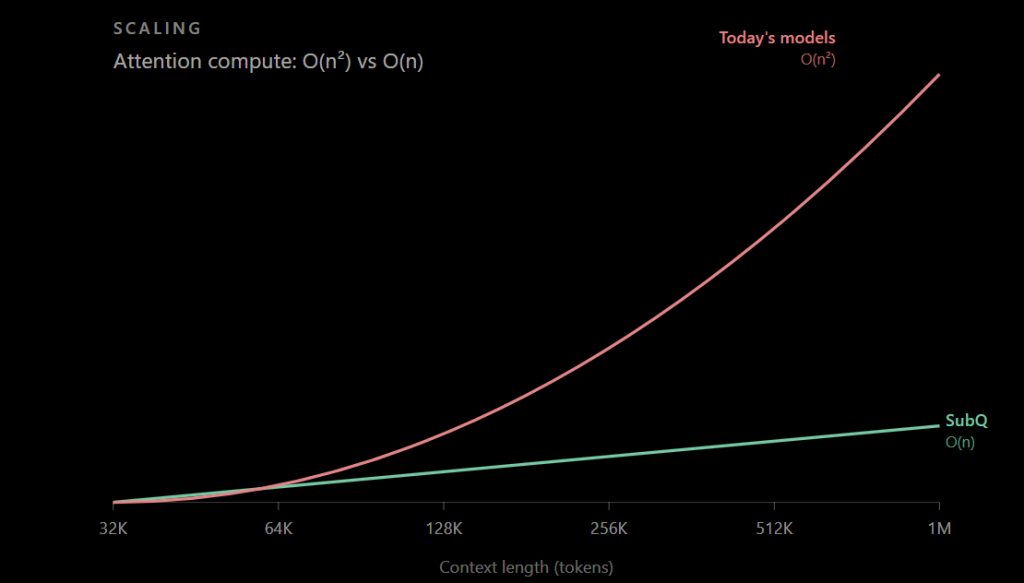
Depuis 2017 (et l’article fondateur « Attention Is All You Need »), la plupart des grands modèles de langage reposent sur l’architecture Transformer (la fameuse architecture de Google Research sur laquelle repose tous les grands LLMs et qui justifie le T de GPT). Son principe clé, l’attention, permet au modèle de mettre chaque mot – ou plutôt chaque token – en relation avec les autres pour comprendre le contexte. C’est ce mécanisme qui a rendu possibles les progrès spectaculaires des LLM. Mais il a un défaut : son coût augmente très vite avec la longueur du texte. La croissance est quadratique : dans une attention classique, chaque token doit être comparé à tous les autres. Le nombre de relations à calculer augmente donc comme le carré de la longueur du contexte. Avec 1 000 tokens, cela représente environ 1 million de comparaisons possibles ; avec 2 000 tokens, on passe à environ 4 millions. Autrement dit, doubler la taille du contexte ne double pas le coût de l’attention : il le multiplie par quatre. À grande échelle, un document long, un dépôt de code complet ou un historique de projet deviennent donc coûteux, lents et difficiles à exploiter.
SubQ : ne plus tout comparer avec tout
C’est précisément ce verrou que Subquadratic prétend desserrer avec SubQ, un modèle fondé sur une technologie baptisée SSA, pour Subquadratic Sparse Attention. L’idée est simple à formuler : au lieu de comparer chaque token avec tous les autres, SubQ cherche à identifier les relations réellement utiles et à ignorer celles qui apportent peu d’information. Dans un Transformer classique, tout le monde regarde tout le monde. Avec SubQ, le modèle essaie de repérer les interactions pertinentes avant de concentrer le calcul sur elles.
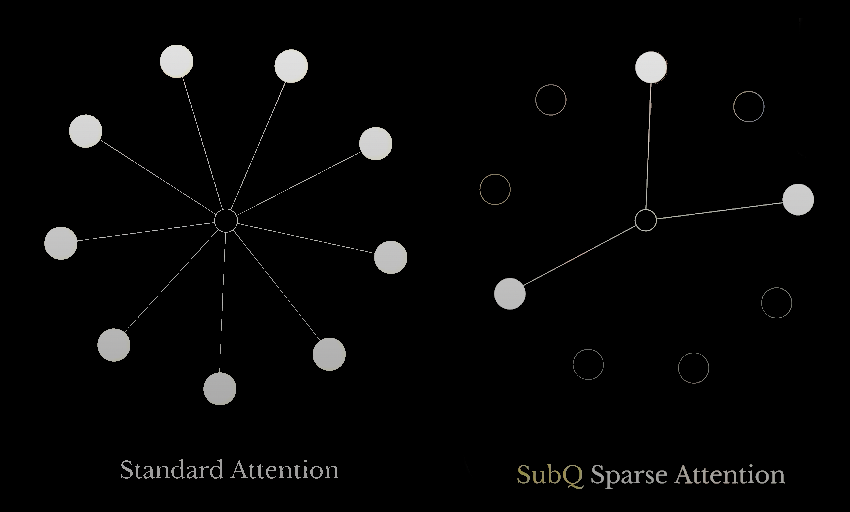
La nuance est importante. Il ne s’agit pas seulement d’optimiser l’attention classique, comme le font des techniques telles que FlashAttention (une optimisation côté GPU notamment utilisée dans vLLM et PyTorch mais qui ne change pas la croissance quadratique). Subquadratic affirme modifier la logique économique du long contexte : ne plus payer le prix complet de toutes les relations possibles, mais seulement celui des relations jugées importantes. Cela permettrait de traiter des fenêtres de contexte beaucoup plus longues avec une progression du coût nettement plus raisonnable.
Une idée nouvelle ? Pas vraiment
La technologie de SubQ n’invente pas ex nihilo l’attention éparse ou sous-quadratique. Google, Mistral et d’autres ont déjà exploré depuis plusieurs années des variantes destinées à casser le mur quadratique du Transformer. Google Research a notamment travaillé sur Reformer, Big Bird ou les Performers, qui cherchaient déjà à réduire le coût de l’attention par des mécanismes de hachage, d’attention éparse ou d’approximation linéaire.
Mistral, de son côté, a popularisé avec Mistral 7B une approche plus pragmatique fondée sur le sliding window attention, où le modèle se concentre sur une fenêtre de contexte limitée plutôt que sur l’ensemble de la séquence à chaque couche.
Mais l’approhe de Subquadratic se distingue par sa volonté de démontrer qu’une attention éparse dépendante du contenu peut être intégrée dans un modèle généraliste, compétitif, exploitable via API, et réellement économique sur des contextes de plusieurs centaines de milliers à plusieurs millions de tokens. C’est moins une invention isolée qu’une industrialisation d’une piste de recherche longtemps jugée prometteuse mais difficile à faire tenir à grande échelle.
Des performances annoncées très agressives
Les chiffres avancés par Subquadratic sont spectaculaires. L’entreprise affirme que SubQ est 52 fois plus rapide que FlashAttention sur 1 million de tokens, et que le calcul d’attention serait réduit d’environ 1 000 fois à 12 millions de tokens par rapport à une attention dense classique.
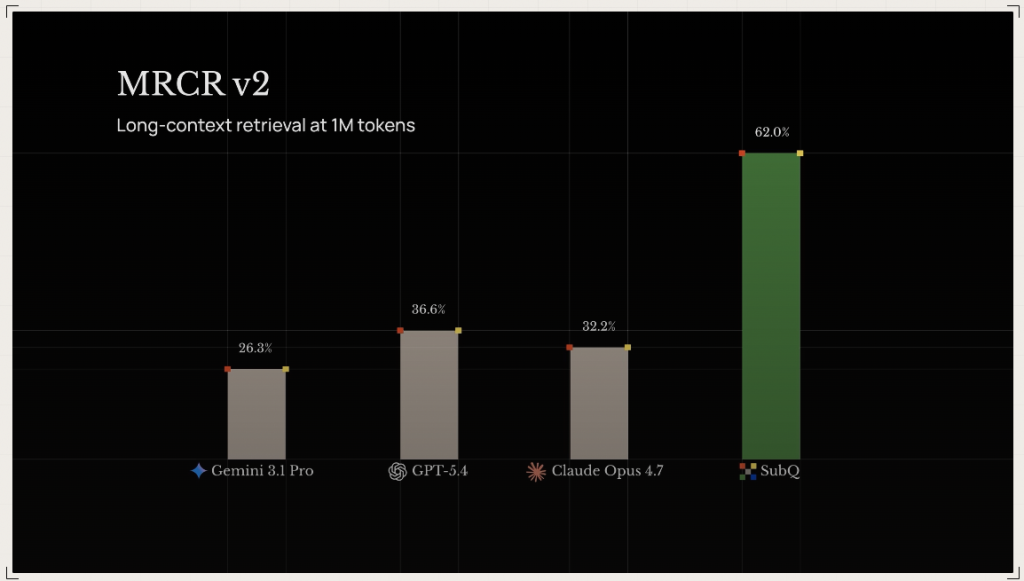
Sur le benchmark RULER 128K, spécialisé dans les longs contextes, SubQ atteindrait un score de 95 %, soit un niveau comparable aux meilleurs modèles du marché. Sur SWE-Bench Verified, benchmark de codage, il afficherait un score de 81,8 %, le plaçant devant plusieurs références citées par l’entreprise.
Le coût revendiqué est tout aussi agressif : moins de 1,50 dollar par million de tokens. L’exécution d’un bench de long contexte comme le test RULER est ainsi facturé environ 8 dollars contre 2 600 dollars avec Claude Opus, selon Subquadratic.
Autrement dit, l’enjeu n’est pas seulement d’élargir les fenêtres de contexte, mais de les rendre économiquement utilisables.
Repenser le RAG
Les usages d’IA en entreprise ne se limitent pas à poser une question courte à un chatbot. Ils consistent souvent à analyser des contrats, des corpus documentaires, des bases de connaissance, des historiques de tickets, des référentiels réglementaires ou des dépôts de code. Aujourd’hui, ces usages reposent largement sur le RAG : on découpe les documents, on les indexe, puis on récupère les passages jugés pertinents. Cela fonctionne, mais au prix d’une chaîne complexe et fragile. Un mauvais découpage ou une récupération incomplète peut faire manquer l’information décisive.
Si le modèle tient ses promesses, SubQ pourrait réduire cette dépendance au bricolage documentaire. Bien sûr, le RAG ne disparaîtrait pas : il resterait indispensable pour filtrer, gouverner, tracer les sources et appliquer les droits d’accès. Mais il pourrait devenir moins un palliatif à la faiblesse des fenêtres de contexte et davantage une couche de gouvernance documentaire.
Un intérêt évident pour le code
Le cas du développement logiciel est probablement l’un des plus parlants. Les agents de codage actuels travaillent souvent par fragments : quelques fichiers, quelques dépendances, quelques appels d’outils. Avec un contexte beaucoup plus large et moins coûteux, un modèle pourrait raisonner sur une portion bien plus importante d’un dépôt, repérer des effets de bord, comprendre des conventions anciennes ou suivre une logique applicative dispersée. C’est le positionnement de SubQ Code, l’agent de codage annoncé par Subquadratic.

Pour les entreprises, ce point est loin d’être anecdotique. La maintenance applicative, la dette technique, les migrations cloud, la modernisation Java, la documentation de code ancien ou l’analyse d’impacts sont précisément des domaines où les modèles actuels se heurtent vite à la fragmentation du contexte.
Les limites à garder en tête
Reste que plusieurs limites doivent tempérer l’enthousiasme. D’abord, les chiffres actuellement publiés viennent principalement de Subquadratic. Certains résultats sont annoncés comme vérifiés par un tiers, mais il manque encore un rapport technique complet, une model card détaillée et des évaluations indépendantes à grande échelle pour se forger une idée plus précise du réel potentiel de SubQ.
Ensuite, long contexte ne signifie pas bonne compréhension. Un modèle peut lire davantage et se tromper quand même. Il peut retrouver la bonne information mais mal l’interpréter. Il peut aussi être plus exposé aux injections de prompt cachées dans des documents longs. La technologie est une technique d’optimisation des LLM actuels. Pas une révolution permettant à l’IA de franchir un nouveau cap cognitif, mais un levier d’efficacité essentiel : elle rend les modèles existants plus rapides, moins coûteux et plus praticables à grande échelle, sans changer fondamentalement leur architecture ni résoudre leurs limites de compréhension, de fiabilité ou de raisonnement.
Autre limite : le coût de l’attention n’est pas tout le coût d’un système IA. Il faut ajouter la génération, l’orchestration, la sécurité, l’observabilité, la conformité, la latence réseau, la gestion des droits et l’intégration au SI.
Enfin, SubQ reste une technologie propriétaire en accès anticipé. Pour une DSI, cela engendre les habituelles questions autour de la confidentialité, de l’auditabilité, de la réversibilité, de la résidence des données, des SLA, de la gouvernance des prompts et de l’intégration IAM.
Reste que SubQ marque, sur le papier, un saut important pour les LLM actuels. Certes, il n’enterre pas Transformer, ni les approches RAG, ni les grands modèles existants. Mais il matérialise une direction importante car nécessaire : l’industrialisation de l’IA passera aussi par des architectures capables de traiter beaucoup plus de contexte sans multiplier les coûts.
Car l’avenir de l’IA ne se jouera pas seulement sur des modèles plus intelligents, mais sur des modèles capables de travailler sur des volumes réels de données métier, à un coût soutenable et avec une gouvernance maîtrisable. C’est pourquoi toute innovation à même de transformer l’équation « coût par token » est bonne à prendre.
À LIRE AUSSI :
À LIRE AUSSI :