


Cloud
Google Cloud Next 2026 (Partie 2) : Pour soutenir l’ambition agentique, Google Cloud fait évoluer toute son infrastructure
Par Laurent Delattre, publié le 27 avril 2026
Pour faire tourner des armées d’agents, il ne suffit plus d’empiler des modèles et des API. Google refond la machine sous le capot : TPU séparés entre entraînement et inférence, réseau Virgo, GKE accéléré et data stack recâblée pour encaisser le passage à l’échelle. A Google Cloud Next, la semaine dernière, l’hyperscaler a dévoilé comment il faisait évoluer son infrastructure Cloud pour transformer ses promesses IA en système industriel.
La conférence Google Cloud Next 2026 se tenait cette semaine à Las Vegas, marquée comme il se doit par une pluie de nouveautés et de partenariats pour un indigeste total de plus de 200’annonces. Une conférence principalement marquée par la concrétisation de la vision des organisations agentiques de l’hyperscaler notamment portée par le lancement de la nouvelle Gemini Enterprise Agent Platform (refonte de Vertex AI) qui permet aux DSI de construire, exécuter, gouverner et optimiser leurs flottes d’agents. Au-dessus de cette plateforme, Google voit s’émanciper une Taskforce agentique principalement composée d’applications et d’agents IA développées par des tiers mais aussi par Gemini Enterprise App, Gemini Enterprise for Customer Experience ainsi que des fonctionnalités agentiques ancrées dans l’univers collaboratif Google Workspace amplifiées par la nouvelle couche de contextualisation Workspace Intelligence. Autant d’annonces que nous avons largement développées dans la première partie de notre compte-rendu.
Mais toutes ces plateformes et couches applicatives nécessitent des infrastructures sous-jacentes capables d’encaisser l’explosion des workloads agentiques. Car contrairement à un simple chatbot, un agent raisonne, enchaîne des appels d’outils, manipule du contexte long, délègue à d’autres agents et le tout souvent en parallèle à l’échelle de milliers d’instances simultanées. Un profil de charge qui fait exploser les besoins en calcul, en mémoire, en bande passante réseau et en I/O stockage. Et c’est précisément sur ce terrain que Google est venu, à Las Vegas, livrer cette année l’une de ses copies les plus ambitieuses. A Las Vegas, l’hyperscaler a ainsi annoncé une refonte profonde de sa couche d’infrastructure cloud. Avec en point de départ, une annonce très médiatique et stratégique : l’arrivée d’une huitième génération de TPU, qui opère un virage architectural majeur.
TPU 8t et TPU 8i : la première génération à séparer entraînement et inférence
Pour la première fois en une décennie de silicium maison (le premier TPU est né en 2016), Google scinde sa huitième génération en deux puces spécialisées plutôt qu’une architecture monolithique. D’un côté, le TPU 8t (codename Sunfish, conçu avec Broadcom) est une machine de guerre dédiée à l’entraînement. De l’autre, le TPU 8i (codename Zebrafish, conçu avec MediaTek) est taillé pour l’inférence et l’apprentissage par renforcement.

TPU 8t : l’entraînement à l’échelle du gigawatt
Le TPU 8t est conçu pour « compresser le cycle de développement des modèles frontières de mois en semaines ».
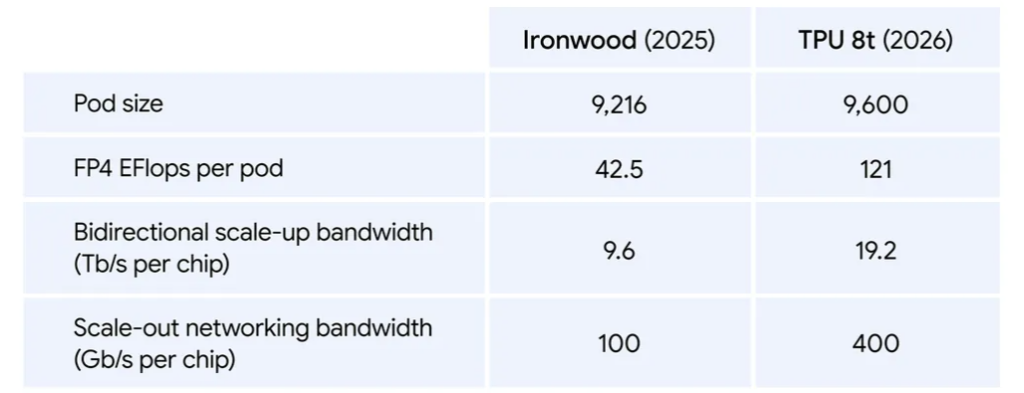
Chaque puce TPU 8t possède 216 Go de HBM3e (avec une bande passante mémoire 30% supérieure à la génération IronWood) et 128 Mo de SRAM on-chip et affiche des performances allant jusqu’à 12,6 pétaflops FP4 et 19,2 Tb/s de bande passante chip-to-chip.
Mais comme toujours avec les TPU de Google, les performances individuelles de ces accélérateurs IA importe moins que leur capacité à être assemblés au sein de super-clusters de calculs IA, les pods.
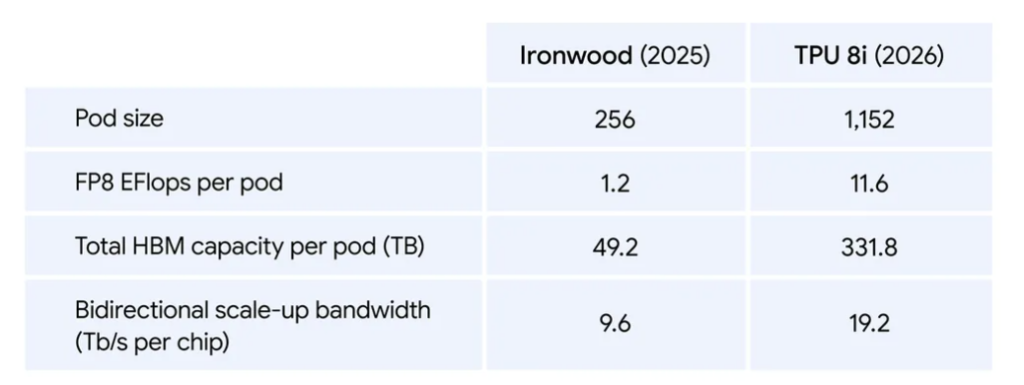
Un pod 8t embarque 9 600 puces (contre 9 216 pour Ironwood) pour délivrer 121 exaflops FP4 par pod, soit 2,84x le débit d’Ironwood, adossés à un total de deux pétaoctets de mémoire à haute bande passante (HBM) partagée via l’Inter-Chip Interconnect (ICI), dont la bande passante est doublée par rapport à la génération précédente.
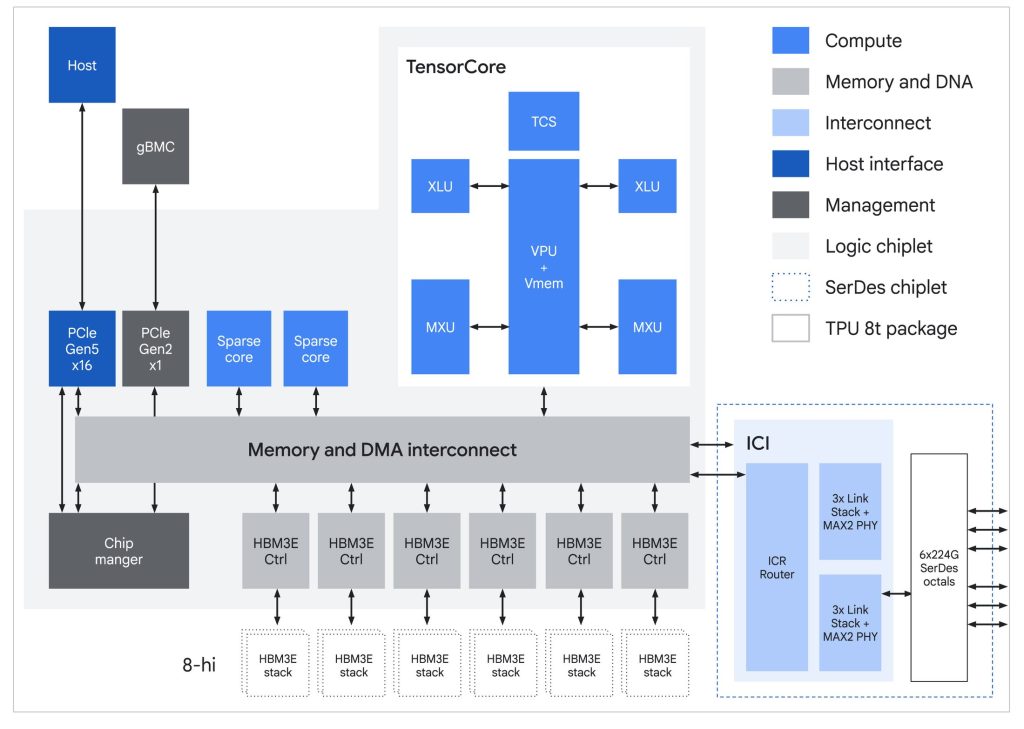
Sur le plan architectural, trois innovations méritent qu’on s’y arrête. Concrètement, le TPU 8t s’attaque à trois goulots d’étranglement récurrents de l’entraînement à grande échelle. D’abord, les calculs d’agrégation qui dépendent de la valeur des données et qui sont très irréguliers par nature, sont sortis des unités de multiplication matricielle (MXU) pour être confiés aux SparseCores : ces unités tournaient auparavant à vide en attendant ce type d’opérations. Ensuite, le support natif du format FP4 (4 bits par paramètre, contre 8 ou 16 auparavant) permet aux MXU de traiter deux fois plus de données à chaque cycle, tout en réduisant drastiquement l’énergie nécessaire à leur déplacement à travers la puce. Enfin, les technologies TPUDirect RDMA et TPUDirect Storage permettent aux données de circuler directement entre la mémoire HBM du TPU, la carte réseau et le stockage rapide, sans passer par le CPU hôte qui faisait jusqu’ici goulot. Le gain est spectaculaire : un accès au stockage 10 fois plus rapide qu’avec Ironwood, ce qui maintient les MXU à pleine charge même sur les datasets multimodaux massifs.
Le TPU 8t revendique un gain de 2,7x à 2,8x en performance par dollar par rapport à Ironwood en entraînement large échelle, avec une efficacité énergétique doublée. Les frameworks JAX, MaxText, PyTorch, SGLang et vLLM sont nativement supportés. Via JAX et Pathways, Google promet l’orchestration distribuée de super-clusters (les superpods) de plus d’un million de TPU, là où l’entreprise entend entraîner ses prochaines générations de modèles.
TPU 8i : briser le mur de la mémoire pour servir des millions d’agents
Le TPU 8i s’attaque à l’autre versant de l’IA : l’inférence et la nécessité aujourd’hui de faire tourner simultanément des millions d’agents, avec des modèles Mixture of Experts (MoE) de plus en plus bavards, sans exploser les coûts.
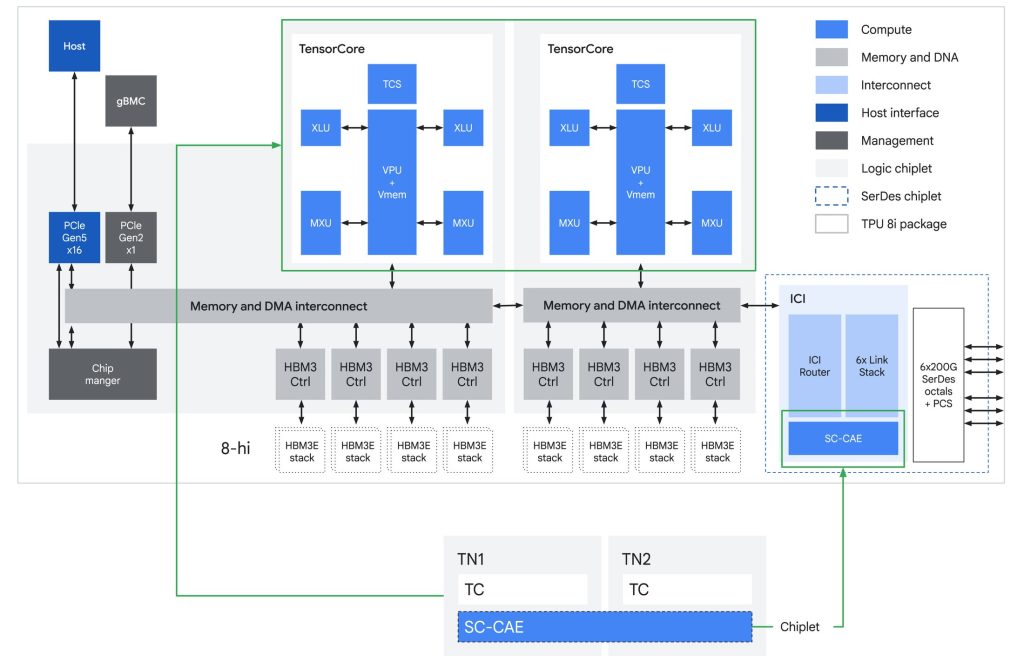
Pour y parvenir, Google a posé trois choix architecturaux radicaux.
Premier choix : briser le mur de la mémoire. Quand un modèle génère une réponse, il doit conserver en mémoire tous les tokens déjà traités, ce qu’on appelle le « KV Cache ». Plus le contexte est long, plus ce cache grossit, et plus le modèle passe de temps à aller chercher ces informations en mémoire plutôt qu’à calculer. Le TPU 8i s’attaque frontalement à ce goulot d’étranglement : la HBM (mémoire haute bande passante) passe à 288 GB avec 8,6 TB/s de débit, et la SRAM, la mémoire ultra-rapide gravée directement dans le silicium, est triplée à 384 MB. De quoi héberger des KV Caches massifs entièrement sur la puce, et réduire drastiquement la latence sur les longs contextes.
Deuxième choix : remplacer les quatre SparseCores d’Ironwood par un bloc dédié inédit, le Collectives Acceleration Engine (CAE). Son rôle : accélérer les étapes de synchronisation et d’agrégation qui se répètent sans cesse pendant la génération d’une réponse token après token et, plus encore, pendant les raisonnements longs de type « chain-of-thought ». Chaque TPU 8i embarque deux Tensor Cores sur son die principal et un CAE sur un chiplet séparé. La latence de ces opérations collectives chute d’un facteur cinq — un gain qui se traduit directement en capacité à servir des millions d’agents simultanément.
Troisième rupture, la nouvelle topologie réseau Boardfly. Elle abandonne le 3D-torus du TPU 8t au profit d’une fabric hiérarchique à haut degré de connexion. En clair : dans une configuration à 1 024 puces, le plus long trajet possible entre deux puces passe de 16 sauts (en 3D-torus) à seulement 7 sauts (en Boardfly), soit un diamètre réseau réduit de 56 % et une latence des échanges « tous-à-tous » améliorée jusqu’à 50 %. Un gain décisif pour les modèles de type Mixture of Experts (MoE), qui passent leur temps à router les tokens d’un expert à un autre à travers la fabric.
Résultat : un seul pod TPU 8i connecte désormais 1 152 puces (contre 256 pour Ironwood), pour un total de 331,8 exaflops en FP8 par pod, soit 6,74 fois Ironwood. Détail amusant : Google en a profité pour doubler le nombre d’hôtes CPU physiques par serveur en basculant sur ses propres processeurs ARM Axion maison. Le bilan global annoncé est sans appel : +80 % de performance en plus par dollar et 2x plus de performance par watt par rapport à Ironwood.
L’AI Hypercomputer s’enrichit : A5X, Axion N4A…
Pour rappel, l’AI Hypercomputer désigne l’architecture intégrée, matérielle et logicielle, que Google peaufine depuis 2023 pour optimiser les charges de travail IA. Elle propulse Vertex AI, Gemini et tout l’écosystème entreprise de l’hyperscaler. Cet Hypercomputer, qui agrège TPU Google et GPU Nvidia, accueille cette année plusieurs briques neuves.
A5X s’appuiera sur NVIDIA Vera Rubin NVL72 lorsque la plateforme sera disponible, et intégrera plusieurs concepts issus du protocole ouvert Falcon, co-développé avec NVIDIA dans le cadre de l’Open Compute Project.
En attendant, des clients témoignent de leurs usages des instances A4X MAX basés sur les NVL72 de NVidia en versions GB300. C’est notamment le cas du laboratoire Thinking Machines Labs (de Mira Murati, ex CTO d’OpenAI) qui a basculé son API Tinker sur ces instances, avec à la clé un doublement des vitesses d’entraînement et de service.
Côté CPU, les machines virtuelles Axion N4A passent en disponibilité générale. Bâties sur les puces ARM maison dénommées Axion (cœurs Neoverse N3) et l’IPU Titanium, elles offrent jusqu’à 64 vCPU et 512 Go de DDR5, avec un réseau standard pouvant atteindre 50 Gb/s. Google revendique jusqu’à deux fois plus de rapport prix-performance et 80 % d’efficacité énergétique en plus face aux machines virtuelles x86 de génération courante. Ces instances sont taillées pour les environnements d’exécution d’agents : le GKE Agent Sandbox sur Axion N4A délivretrait jusqu’à 30 % de rapport prix-performance de mieux que les offres agentiques des autres hyperscalers.
La famille Compute Engine 4ème génération (C4 / C4D) est motorisée par les dernières générations Intel Xeon 6 / Granite Rapids et AMD EPYC Turin, qui complètent les TPU et GPU dans l’AI Hypercomputer. Google les positionne pour les charges CPU qui entourent l’IA : inférence légère, recherche vectorielle, orchestration d’agents, appels d’outils, pré/post-traitement, pipelines de données, calculs de récompense pour le reinforcement learning, etc
Plus discrètement, Google annonce aussi Axion C4A.metal (en aperçu), première instance physique « bare metal » ARM de Google Cloud, qui vise notamment le développement Android, la simulation automobile, les pipelines CI/CD et les hyperviseurs sur mesure.
Enfin, les VM Z4M sont une nouvelle famille Compute Engine “storage-optimized” annoncée par Google Cloud à Next ’26 (en aperçu au troisième trimestre 2026, jusqu’à 168 Tio de SSD local et 400 Gb/s de bande passante réseau). Elles visent les workloads qui ont besoin d’un très gros stockage local très rapide, plutôt que d’un simple couple CPU/mémoire classique : systèmes de fichiers parallèles distribués type Vast Data ou Sycomp, pipelines IA/ML à grande échelle, charges HPC, caches massifs, pré-traitement de données, ou alimentation rapide de clusters GPU/TPU.
Virgo Network, la fabrique scale-out de l’ère agentique
C’est l’une des annonces les plus structurantes côté infrastructure : Virgo Network est la nouvelle « fabrique » réseau de centre de données à très grande échelle, spécialement conçue pour l’IA, au cœur de l’AI Hypercomputer. Son architecture compactée (collapsed fabric) offre quatre fois la bande passante des générations précédentes et élimine la « taxe de mise à l’échelle » qui plombait jusqu’ici l’efficacité des gros clusters.
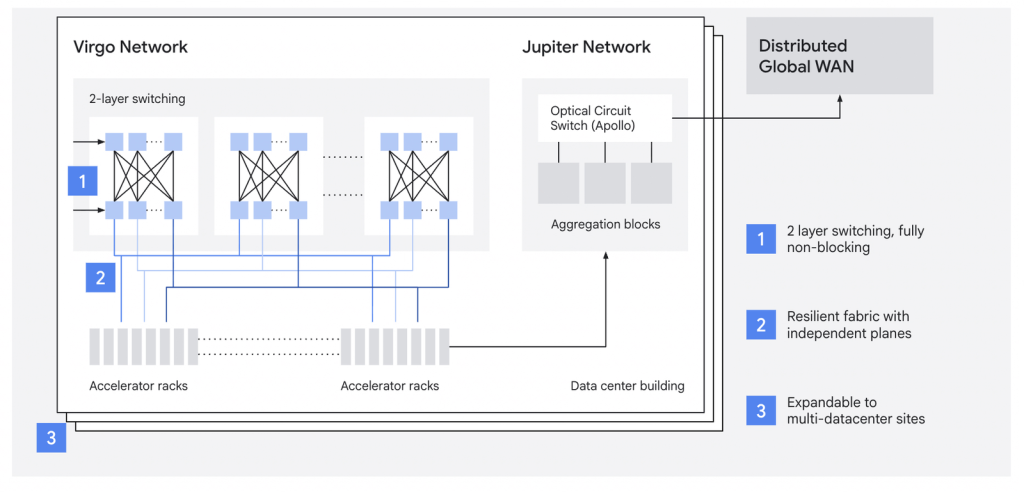
En pratique, combiné aux TPU 8t, Virgo Network permet de connecter 134 000 TPU dans une seule fabrique au sein d’un même centre de données, et d’interconnecter plus d’un million de TPU à travers plusieurs sites pour former un cluster d’entraînement unique. Autrement dit, l’infrastructure distribuée mondialement se comporte comme un seul supercalculateur. Pour le monde NVIDIA, Virgo Network est également disponible sur A5X (Vera Rubin NVL72) et prend en charge jusqu’à 80 000 GPU dans un centre de données, jusqu’à 960 000 GPU sur plusieurs sites. De quoi alimenter les ambitions d’entraînement de Gemini 4, dont Demis Hassabis a confirmé en début d’année qu’il était au cœur de la feuille de route 2026 de DeepMind (sans pour autant fournir de date publique de sortie).
GKE et Cloud Run : l’orchestration nativement agentique
Google Kubernetes Engine a été « repensé pour servir de moteur d’orchestration de référence des charges de travail nativement agentiques ». Les nouveautés concernent d’abord la latence de démarrage : les nœuds GKE démarrent jusqu’à 4 fois plus vite, les pods jusqu’à 80 % plus vite. Le chargement des modèles est accéléré de 5 fois grâce à l’intégration de run:AI Model Streamer et de Rapid Cache dans Cloud Storage.
Mais la vraie nouveauté tient dans l’Inference Gateway dopée par l’IA : plutôt que des heuristiques, un modèle d’apprentissage automatique réalise un routage en temps réel tenant compte de la capacité disponible, ce qui réduit le temps avant le premier token (TTFT) de plus de 70 % sans réglage manuel.
Côté isolation, le GKE Agent Sandbox passe en disponibilité générale avec des capacités impressionnantes : jusqu’à 300 bacs à sable déployés par seconde et par cluster, avec un délai d’exécution de la première instruction inférieur à la seconde. C’est aujourd’hui, selon Google, le seul service de bac à sable natif chez les hyperscalers.

Cloud Run est l’offre serverless container de Google, qui exécute n’importe quel conteneur à la demande avec une facturation à l’usage et zéro charge d’infrastructure. C’est historiquement la brique de prédilection pour déployer rapidement des applications web, des API ou des traitements par lots, mais aussi, désormais, des agents IA complets. Google revendique un doublement du nombre de développeurs actifs externes sur Cloud Run en 2025, et plus de nouveaux clients en un an que durant les six premières années du service.
Pour Cloud Next 2026, quatre nouveautés autour de Cloud Run méritent d’être notées :
• Intégration avec Gemini Enterprise Agent Platform (en aperçu) : les agents transitent directement depuis leurs environnements expérimentaux vers des systèmes managés de qualité production, sans reconstruction.
• Cloud Run instances (en aperçu) : au-delà des services, jobs et worker pools – jusqu’ici les seuls modes d’abstraction disponibles -, Google ouvre l’accès à la primitive sous-jacente, les Cloud Run Instances. Couplé aux montages de volumes Cloud Storage, cela permet d’héberger des agents longue durée en arrière-plan, comme OpenClaw, en une seule commande.

• Cloud Run sandboxes (bientôt) : au sein d’une même requête, possibilité de démarrer un bac à sable éphémère strictement isolé de votre infrastructure, pour exécuter du code ou des commandes générés par un agent.
• Serveur MCP distant managé (GA) : Cloud Run devient une cible de déploiement naturelle pour les agents et applications IA qui veulent publier un point d’accès MCP sans effort. Prise en charge GA des GPU NVIDIA RTX PRO 6000 Blackwell.
L’Agentic Data Cloud : pas d’IA agentique sans données
« AI is only as smart as its context », l’IA n’est intelligente qu’à la hauteur du contexte qu’on lui donne. La formule, signée Andi Gutmans (VP/GM Data Cloud chez Google Cloud), résume l’autre grand chantier du Cloud Next 2026 : nourrir les agents en données métier de qualité.
Car un agent qui ignore ce que votre entreprise appelle « marge », ou comment s’articulent les maillons de votre chaîne d’approvisionnement, ne s’arrête pas pour autant : il devine. Et qui dit deviner dit halluciner, brûler des tokens pour rien, et finir par produire des décisions bancales.
Autre problème, plaide Google, les plateformes data héritées ont été conçues pour des humains qui posent des questions de temps en temps, pas pour des nuées d’agents qui doivent agir en continu sur la donnée vivante.
D’où le lancement de l’Agentic Data Cloud, une architecture nativement IA qui fait passer la plateforme data du statut de dépôt statique à celui de moteur de raisonnement dynamique. Google parle d’un « système d’action », par opposition aux « systèmes d’intelligence » d’hier. Trois piliers structurent l’offre.

Cross-Cloud Lakehouse : un lakehouse réellement sans frontières
Standardisé sur Apache Iceberg, le Cross-Cloud Lakehouse permet à un agent d’interroger les données d’une entreprise où qu’elles se trouvent – AWS, Azure (plus tard cette année), Google Cloud – sans recopie, sans ETL, avec une friction minimale.
Google intègre directement Cross-Cloud Interconnect (CCI) dans son plan de données. Combiné au catalogue REST Iceberg, cela offre une connectivité multi-cloud à faible latence qui élimine les redoutables frais de sortie, devenus l’un des freins majeurs à l’industrialisation des agents.

Second volet, la fédération bidirectionnelle (en aperçu) avec Databricks Unity Catalog (Amazon S3), Snowflake Polaris et AWS Glue Data Catalog. Les moteurs Google peuvent désormais lire directement depuis ces catalogues propriétaires, et réciproquement, avec des politiques de sécurité et des contrôles d’accès appliqués instantanément via une couche Lakehouse Governance enrichie. Une réponse directe aux silos de Databricks et Snowflake. Google annonce également Spanner Omni (en aperçu), qui libère son moteur de base de données pour le faire tourner n’importe où – sur site, autres clouds, ou même sur un ordinateur portable – , et Lakehouse federation for AlloyDB (en aperçu), qui supprime les pipelines ETL entre l’opérationnel et l’analytique grâce à une synchronisation sans ETL au niveau du protocole. Pas de recopie non plus pour les plateformes SaaS et IA partenaires : Databricks, Palantir, Salesforce Data360, SAP, ServiceNow, Snowflake, Workday sont intégrés nativement.
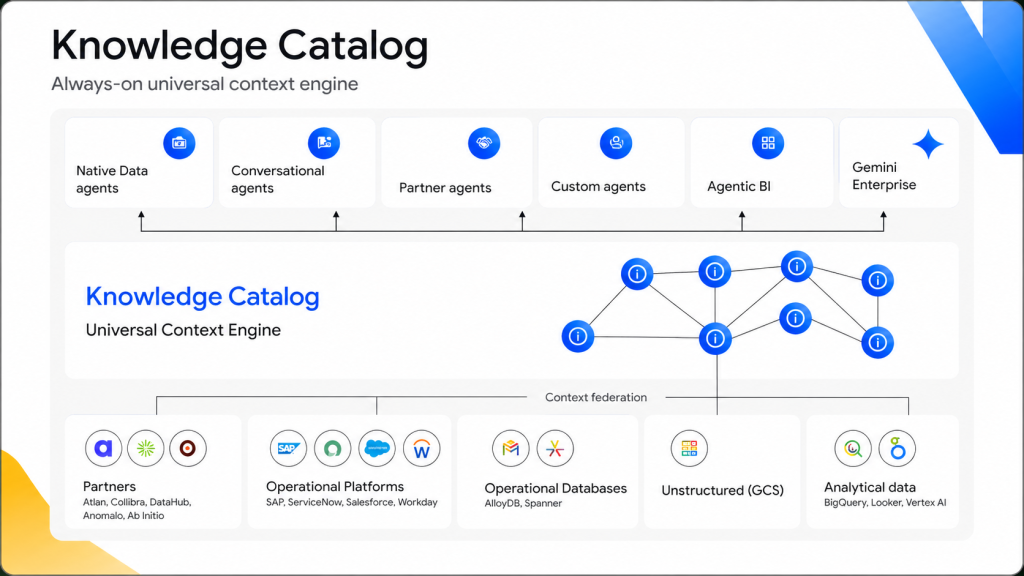
Knowledge Catalog : la mémoire vivante de l’entreprise
Évolution du Dataplex Universal Catalog, le Knowledge Catalog cartographie et infère le sens métier à travers l’ensemble du parc de données. Son architecture repose sur trois mécanismes.

D’abord l’agrégation : le catalogue collecte le contexte natif issu de Google Cloud et des plateformes partenaires (Palantir, Salesforce Data360, SAP, ServiceNow, Workday). Pour les sources internes à Google Cloud, Google automatise la génération de la logique métier avec le LookML Agent (en aperçu), qui produit de manière autonome des sémantiques à partir des documents de stratégie, et les BigQuery measures (en aperçu), qui embarquent la logique métier nativement dans la plateforme.
Ensuite l’enrichissement continu : le Knowledge Catalog analyse en permanence les journaux d’usage et profile les données en arrière-plan. Il apprend comment votre organisation utilise réellement ses données, pas simplement ce qu’elles sont. Il s’étend également aux données non structurées : Smart Storage (en aperçu) étiquette et enrichit instantanément les images dès qu’un fichier atterrit dans Google Cloud Storage, et bientôt les PDF. Gemini est même utilisé pour générer automatiquement les schémas manquants et cartographier les relations complexes.
Enfin, la recherche et la récupération. Le catalogue combine appariement sémantique, lexical et reclassement par apprentissage automatique, le tout bâti sur la technologie de Google Search. Surtout, le contrôle d’accès intégré (access-control-aware search) garantit qu’un agent ne peut récupérer et exploiter que les actifs qu’il est autorisé à voir — enjeu clé pour les RSSI. Le Knowledge Catalog alimente ainsi le Deep Research Agent for Enterprise Insight (en aperçu), l’un des agents Google livrés avec Gemini Enterprise, capable de raisonner en plusieurs étapes à travers BigQuery, les documents internes et les actifs web pour répondre avec précision et citations à des questions complexes qui demandaient jusqu’ici des semaines d’effort manuel.
Data Agent Kit : le praticien de la donnée devient orchestrateur
Plutôt que de créer une énième interface, le Google Cloud Data Agent Kit (en aperçu) s’injecte directement dans les environnements que les développeurs utilisent déjà : VS Code, Gemini CLI, Codex, Claude Code. Chaque IDE, notebook ou terminal agentique devient un environnement data natif capable d’orchestrer de manière autonome un large éventail d’objectifs métier, en sélectionnant automatiquement le bon framework (dbt, Apache Spark, Apache Airflow…) et en générant du code de qualité production conforme aux standards Google.

Le Data Agent Kit embarque les mêmes savoir-faire et outils que les agents prêts à l’emploi de Google :
– Data Engineering Agent (GA) pour construire des transformations de pipelines et imposer des règles de gouvernance ;
– Data Science Agent (GA) pour automatiser le cycle de vie des modèles, du nettoyage des données à l’entraînement, en passant à l’échelle sur BigQuery Dataframes et Serverless Apache Spark ;
– Database Observability Agent (en aperçu), sentinelle 24h/24 qui diagnostique les causes racines et exécute les remédiations sur les bases.
Pour garantir la fluidité d’exécution des agents, Google a pleinement adopté le Model Context Protocol (MCP) d’Anthropic. Les Tools for Data Agents se matérialisent sous forme de serveurs MCP managés pour BigQuery, Spanner (en aperçu), AlloyDB, Cloud SQL (GA) et Looker (en aperçu). MCP pour Google Cloud s’appuie sur la pile sécurité maison et gouverne les interactions d’agents via les politiques IAM, VPC Service Controls et de résidence des données existantes. Conversational Analytics est par ailleurs disponible à travers BigQuery (GA), Cloud SQL, Spanner, AlloyDB (en aperçu) et Looker (GA) : publié dans Gemini Enterprise, n’importe quel collaborateur peut désormais dialoguer directement avec les données vivantes.
Vibe coding pour bases de données
L’autre grande annonce pour les développeurs data est la consolidation du « vibe coding » directement dans Google AI Studio avec des intégrations natives pour les bases de données. Amorcée en mars dernier avec la migration de l’expérience Firebase Studio dans AI Studio et l’intégration directe de l’agent Antigravity, cette démarche permet désormais de construire à partir d’un simple prompt des applications full-stack avec Firebase, Firestore, authentification, gestion des secrets, support multi-utilisateurs en temps réel… et surtout avec des connexions AlloyDB, BigQuery, Spanner natives.
Dit autrement, AI Studio devient l’IDE des agents data. Concrètement, un développeur (ou un utilisateur métier outillé) peut décrire en langage naturel une application de gestion d’inventaire, une boutique en ligne ou un tableau de bord, et AI Studio provisionne, écrit, déploie et branche automatiquement la base de données adéquate via MCP. La frontière entre application agentique et application traditionnelle s’estompe, et Google fait tomber l’une des barrières classiques : la friction entre IDE et infrastructure data. À rapprocher du « Comments to SQL » dans BigQuery, qui permet d’exprimer une requête en langage naturel directement dans le flux SQL, du « vibe querying » assumé.
Lightning Engine et AlloyDB AI-powered search at scale
Pour accompagner les volumes agentiques, Google annonce également quatre ruptures côté moteur : un Spark accéléré (Lightning Engine), un stockage parallèle musclé (Managed Lustre), un Bigtable enrichi d’un étage en mémoire, et un BigQuery à scaling fluide. Détaillons.
Premier levier, le Lightning Engine for Apache Spark, moteur Spark temps réel, sans serveur, qui revendique jusqu’à 4,5 fois la performance de Spark open source et deux fois le rapport prix-performance de l’alternative propriétaire leader du marché. Il est intégré aux offres Dataproc et Serverless for Apache Spark.

Deuxième levier, Managed Lustre grimpe à 10 To/s de bande passante (10 fois plus qu’en 2025, 20 fois plus vite que les offres concurrentes), avec une capacité étendue à 80 pétaoctets.
Troisième, Bigtable hérite d’un étage en mémoire délivrant une latence de lecture inférieure à la milliseconde, ce qui permet d’éliminer les couches de cache séparées.
Quatrième et dernier, BigQuery fluid scaling fait baisser en moyenne les coûts jusqu’à 34 % sur les charges de travail à autoscaling, en montant en charge instantanément quand un agent agit, et en redescendant quand il se tait.
Côté opérationnel, AlloyDB AI-powered search at scale poursuit sa montée en puissance. La base PostgreSQL-compatible de Google devient l’une des références pour les flux agentiques qui mêlent données structurées et multimodales. Sa recherche hybride combine recherche textuelle (« Pixel ») et sémantique (« ce smartphone de Google ») avec reclassement et filtrage en ligne directement sur les données opérationnelles vivantes. L’index ScaNN, qui repose sur le même algorithme que Google Search, offre jusqu’à 10 fois la vitesse de création d’index, 4 fois la vitesse de recherche vectorielle et 10 fois la vitesse de recherche filtrée face à HNSW en PostgreSQL standard. Le moteur AlloyDB AI query engine enrichit SQL d’opérateurs IA (filtres en langage naturel, reclassement via l’API Ranking de Vertex AI, recherche multimodale). Couplé à la fédération Lakehouse, AlloyDB peut désormais servir simultanément de back-end transactionnel à haute fréquence et de plateforme de recherche vectorielle pour des agents, sans qu’il soit nécessaire de dupliquer les données vers un magasin vectoriel séparé.
La bataille du « full-stack » est lancée
Ce que Google met sur la table à Cloud Next 2026, c’est le pari de l’intégration verticale totale. Tout est conçu pour fonctionner ensemble, du silicium jusqu’à l’application finale. Puces (TPU 8t et 8i pour l’IA, Axion pour le calcul généraliste), réseau de centre de données (Virgo), modèles (Gemini 3.1, Gemma 4, mais aussi Claude et Llama), plateforme data (Agentic Data Cloud), environnements d’exécution d’agents (GKE Agent Sandbox, Cloud Run) et productivité bureautique (Workspace Intelligence) ne sont plus des briques à assembler soi-même : ce sont les étages d’un même immeuble, co-conçus pour s’emboîter. (La couche sécurité, tout aussi structurante, fera l’objet de la troisième partie de ce compte rendu.)
Le calcul est simple : moins de couches d’intégration à la charge du client, c’est moins de friction, moins de coûts cachés, et des agents qui passent plus vite du prototype à la production.
Bien sûr, l’intégration est aussi au cœur des offres de Microsoft, d’AWS, de Salesforce et même d’Adobe, ServiceNow ou Oracle.
Google parie que l’ère agentique récompensera la pile la plus cohérente de bout en bout. Et affirme proposer cette pile.
Reste qu’avec Anthropic qui livre ses modèles partout, MCP en standard partagé et A2A déjà en production dans 150 organisations, la différenciation ne se jouera plus sur la pile, où tout le monde converge, mais sur la capacité à industrialiser vite et à grande échelle. Et c’est bien sur cette capacité d’exécution, plus que sur les briques elles-mêmes, que Google entend faire la différence.
À LIRE AUSSI :










