

Data / IA
OpenAI Codex Max, Google Banana Pro… la guerre des modèles continue
Par Laurent Delattre, publié le 21 novembre 2025
Décidément, en cette fin d’année, les nouveaux modèles se multiplient. Après les différentes variantes de GPT-5.1 et celles de Gemini 3, deux nouveaux poids lourds viennent rappeler à quel point l’IA générative change d’échelle. OpenAI signe un modèle taillé pour confier de vrais chantiers applicatifs à des agents de développement. Google, de son côté, propulse un moteur d’images capable de transformer données, rapports et contenus métier en visuels véritablement exploitables par les équipes marketing, produit ou formation.
Rien n’arrête le progrès. Surtout dans l’univers de l’IA générative. Vu la fréquence de sortie de nouveaux modèles, il faut croire que les équipes de R&D d’OpenAI et de Google/DeepMind tournent à plein régime et ne dorment pas souvent.
Certes, la guerre des modèles est prolifique. Elle conduit à des modèles toujours plus puissants et performants pour prendre en charge des tâches toujours plus complexes et soulager nos emplois du temps et nos processus… avant peut-être un jour de nous remplacer… mais pas tout de suite.
OpenAI arme un peu plus les équipes de développement
Ainsi, OpenAI vient d’ajouter une pièce maîtresse à son arsenal : GPT-5.1-Codex-Max, un nouveau modèle spécialisé dans la génération de code. Il ne s’agit pas ici de jouer les simples assistants de complétion. Ce nouveau modèle agentique a été spécialement conçu et calibré pour rester focalisé sur un même objectif d’ingénierie logicielle pendant des heures, voire une journée entière. Disponible dans l’environnement de développement « maison » OpenAI Codex (comprenant un CLI, une extension IDE VS Code, un hébergement cloud, et une interface de revue de code) directement accessible depuis ChatGPT pour les abonnés ChatGPT Plus, Pro, Business, Edu et Enterprise, ce modèle cherche à se positionner comme LE moteur des futurs workflows « agentiques » côté développement.
Le modèle s’appuie sur une version renforcée du moteur de raisonnement de GPT-5.1, entraînée sur des tâches complexes d’ingénierie logicielle, de mathématiques, de recherche ou d’usage d’outils. L’enjeu n’est plus de générer une fonction ou un micro-service en quelques secondes, mais de confier à l’IA des chantiers applicatifs de bout en bout : refonte d’un module, correction systématique de suites de tests, nettoyage d’un dépôt encombré, etc. OpenAI revendique des sessions internes où GPT-5.1-Codex-Max a travaillé plus de 24 heures sur le même projet, enchaînant refactorings et itérations jusqu’à obtenir un résultat exploitable.
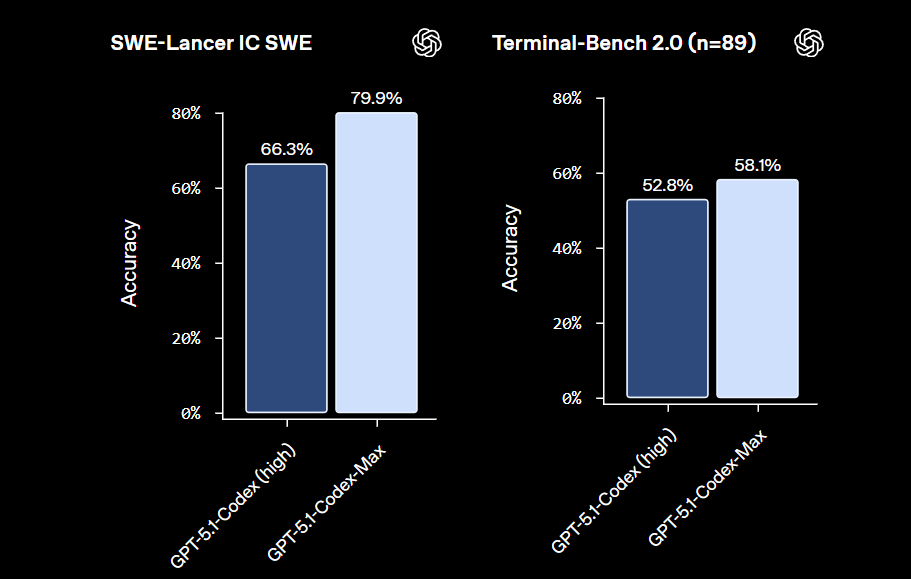
Deux éléments notables méritent d’être ici soulignés. Tout d’abord c’est le premier modèle d’OpenAI conçu pour tenir la distance sur une très longue durée de fonctionnement. La vraie rupture technologique qui permet cette endurance vient de la mise en œuvre d’un principe de « compaction ». Plutôt que d’empiler le contexte jusqu’à saturation, le modèle réécrit en permanence sa propre mémoire de travail, résume, priorise et recompose un historique synthétique pour garder l’essentiel tout en libérant de la place. Concrètement, ce mécanisme permet au modèle de suivre des travaux à l’échelle d’un ensemble applicatif complet sans perdre la cohérence fonctionnelle ni le contexte métier. OpenAI affirme ainsi que GPT-5.1-Codex-Max progresse nettement sur les principaux benchmarks de développement (SWE-Bench, Terminal-Bench 2.0) tout en devenant plus économe en tokens, avec une baisse significative (-30%) de la consommation à niveau de qualité équivalent.
Second point notable et inhabituel, GPT-5.1-Codex-Max est le premier modèle « Codex » d’OpenAI explicitement entraîné pour opérer dans des environnements Windows. OpenAI l’a exposé à des tâches concrètes de développement et d’automatisation sous Windows, notamment autour de la CLI Codex, afin d’en faire un meilleur compagnon de travail pour les développeurs sur cette plateforme.
Sur le terrain de la performance, OpenAI introduit un nouveau niveau de raisonnement « Extra High » (xhigh) destiné aux tâches non sensibles à la latence, où le modèle « pense » plus longtemps pour maximiser la qualité du résultat. Sur SWE-Bench Verified et Terminal-Bench 2.0, GPT-5.1-Codex-Max atteint désormais les meilleurs scores annoncés par OpenAI sur ses modèles de développement, avec 77,9 % sur SWE-Bench Verified et 58,1 % sur Terminal-Bench 2.0, contre 73,7 % et 52,8 % pour GPT-5.1-Codex.
Au-delà des benchmarks, OpenAI insiste sur le fait que le modèle sait générer des interfaces frontend complètes, esthétiques et fonctionnelles, à moindre coût que la génération précédente, et qu’en interne 95 % des ingénieurs utilisent désormais Codex chaque semaine, avec une hausse d’environ 70 % du nombre de pull requests livrées depuis son adoption.
Exemple d’application front end générée par GPT-5.1-Codex-Max
Sur le terrain de la sécurité, le system card de GPT-5.1-Codex-Max est assez explicite. Le modèle est considéré comme très capable en cybersécurité, sans franchir le seuil « High capability » défini par le Preparedness Framework d’OpenAI, mais suffisamment avancé pour justifier un durcissement des garde-fous. Codex fonctionne par défaut dans un bac à sable, avec un accès disque limité à son workspace et un accès réseau désactivé tant qu’il n’est pas explicitement autorisé par le développeur. L’éditeur recommande de maintenir ce mode restreint, notamment pour limiter les risques d’attaques par injection de prompt lors de l’exploration de contenus externes.
Dit autrement, ça marche et c’est rentable et productif. Et pour les DSI, le nouvel enjeu n’est tant de « tester l’IA pour le code », mais d’industrialiser l’usage des agents dans la chaîne CI/CD, la revue de code et la maintenance applicative en veillant à mettre en œuvre les bonnes pratiques de management et les bons garde-fous.
Google muscle Gemini pour les visuels data-driven des entreprises
Le nom est improbable, on vous l’accorde. Mais l’annonce est des plus sérieuses. Car Nano Banana Pro, le nouveau modèle génératif d’images fixes de Google réalise un saut à la fois qualitatif et fonctionnel spectaculaire. Il a toutes les qualités pour s’imposer comme la brique de référence pour générer et éditer des visuels « studio » directement à partir de texte, de schémas ou de données métier.
Cette version « Pro » du modèle introduit au printemps dernier s’appuie désormais sur les capacités de raisonnement et la connaissance du monde du récemment lancé Gemini 3. D’où son nom officiel « Gemini 3 Pro Image ». Et tout comme le modèle original, il se démarque par de puissantes fonctionnalités d’édition et de composition. Cet ancrage à Gemini 3 lui permet de générer des visuels plus précis et contextuels grâce au raisonnement avancé et à la connexion avec Google Search.
Selon Google, les capacités de raisonnement avancé rendent aussi ce modèle plus utile dans les contextes d’entreprise ou d’éducation. Car le modèle ne se contente pas de créer de belles images. Il peut générer infographies, diagrammes, explications éducatives, schémas à partir du contenu fourni par l’utilisateur, des données de l’entreprise ou d’informations provenant d’Internet et de l’actualité. Il se révèle aussi capable de transformer des données brutes, rapports, tableaux, notes, en représentations graphiques immédiatement exploitables par les métiers.
D’autant que Nano Banana Pro améliore considérablement le rendu des textes sur les images, comme en témoigne l’image ci-dessous :

Prompt : Transforme l’image en croquis de storyboard en noir et blanc illustrant un plan d’ensemble, un plan moyen, un gros plan et un plan subjectif (POV) pour une scène de film.
Nano Banana Pro sait générer des slogans, des blocs de texte ou des maquettes complètes avec une typographie lisible, dans plusieurs langues, et les adapter à différents formats, jusqu’en 4K. De quoi industrialiser la déclinaison de supports tout en préservant la cohérence de la marque, y compris lorsque plusieurs visuels intègrent les mêmes personnages ou produits grâce à une meilleure gestion de la constance visuelle.
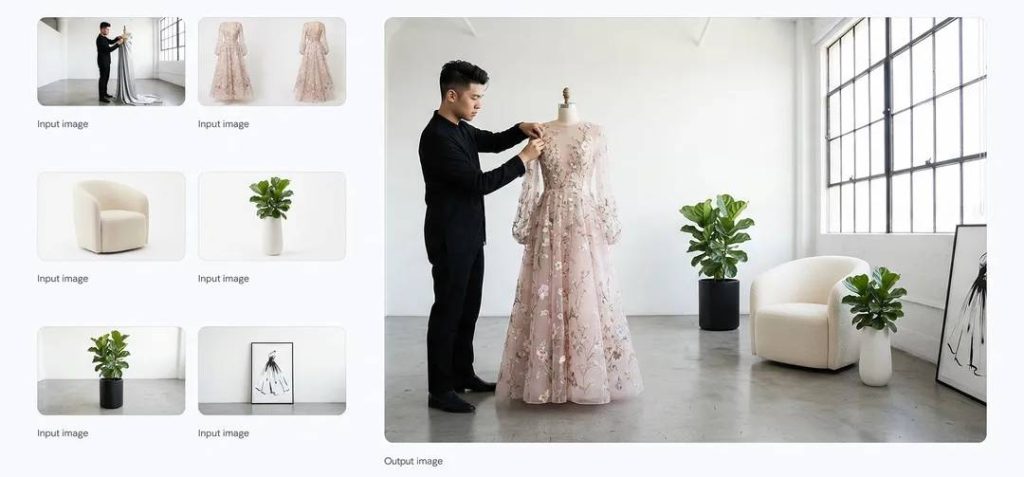
Prompt: Combine les images fournies en une seule image cinématographique bien arrangée au format 16:9 et change la robe du mannequin par celle présente sur la photo.
Enfin le modèle se montre également très inspiré lorsqu’il s’agit de créer des compositions à partir d’éléments disparates. Le modèle sait combiner jusqu’à 14 images et maintenir la cohérence de 5 personnages dans une même composition. Et ses capacités d’édition d’images sont qualifiées par Google de qualité « studio ». Il est possible de sélectionner, affiner et transformer des détails ou partie d’image, d’ajuster les angles de caméras, de changer la mise au point d’une photo, d’appliquer un étalonnage complexe ou de repenser l’éclairage d’une scène.

Prompt : Génère une image avec un effet de clair-obscur intense. L’homme doit conserver ses traits et son expression d’origine. Introduit une lumière directionnelle dure, semblant provenir du haut et légèrement de gauche, créant des ombres marquées et profondes sur le visage. Seuls des filets de lumière doivent éclairer ses yeux et ses pommettes, le reste du visage restant dans une ombre profonde.
Côté intégration, Google déroule d’un coup toute sa pile applicative. Nano Banana Pro arrive dans l’application Gemini, dans le mode IA de Google Search, dans NotebookLM, dans Google Ads et, côté collaboration, dans Slides et Vids pour alimenter présentations et vidéos. Les développeurs et les DSI le retrouvent via l’API Gemini, Google AI Studio, la nouvelle plateforme de développement agentique Antigravity et bien évidemment Vertex AI pour les usages à grande échelle. Il débarque également dans l’outil de filmage Flow qui cible les créatifs et les équipes marketing.
Pour répondre aux inquiétudes liées aux deepfakes, toutes les images générées sont marquées par un filigrane numérique SynthID, et l’utilisateur peut désormais interroger l’app Gemini pour vérifier si un visuel a été produit par les outils Google. Cette fonctionnalité sera prochainement étendue aux générations audio et vidéo des modèles de Google.
Et dernier point critique, la tarification du modèle demeure étonnamment raisonnable : 0,134$ par image 2K et 0,24$ par image 4K. De quoi renforcer encore un peu plus son usage professionnel, notamment dans les chaînes de création visuelle des équipes marketing produits.
Un saut remarquable qu’il faut savoir exploiter
Pour les DSI, ces deux modèles aussi différents soient ils racontent en réalité la même histoire : en deux ans, les IA génératives sont passées du gadget expérimental à la brique d’infrastructure solide et crédible qui s’insère dans les processus métiers sans tout faire voler en éclats. Côté développement, les agents codent, refactorent et maintiennent dans des environnements cloisonnés, logués, pilotables. Côté « contenus », les modèles construisent des visuels data-driven cohérents, traçables et filigranés, intégrés aux chaînes de production existantes.
La vraie rupture n’est plus aujourd’hui l’utilité réelle et la puissance brute des modèles. Il ne fait plus aucun doute qu’ils changent la donne et peuvent apporter une vraie valeur. L’enjeu se fait aujourd’hui sur la capacité à les encadrer, les auditer et les brancher proprement sur la CI/CD, le MRM, le CRM ou les plateformes de données. Autrement dit, l’IA générative est vraiment devenue en 2025 un outil d’entreprise modulable, gouvernable et contractualisable. Aux DSI, désormais, d’orchestrer cette nouvelle couche d’intelligence comme on gère un socle applicatif critique : non plus à coups de POC, mais avec des patterns, des politiques et des engagements de service dignes d’un système de production.
À LIRE AUSSI :










