


Data / IA
Gemini 3.1 Pro : ce que sa Model Card nous apprend du nouveau LLM frontière de Google
Par Laurent Delattre, publié le 20 février 2026
Google vient de publier Gemini 3.1 Pro, accompagné de sa Model Card officielle. Derrière les benchmarks spectaculaires de ce modèle frontière, le document révèle le portrait d’un modèle itératif qui progresse essentiellement en réflexion mais présente aussi de nouveaux risques. Décryptage.
Dans la course aux modèles frontières, les communiqués de presse s’écrivent tous un peu de la même façon. Il y a les superlatifs, les courbes de benchmarks qui grimpent, les citations de CEO enthousiastes. Parallèlement, les équipes techniques publient toujours un autre document, plus discret, plus technique, plus ancré dans les réalités et donc souvent plus instructif : la Model Card.
Celle de Gemini 3.1 Pro, publiée par DeepMind en même temps que le déploiement du nouveau modèle frontière fer de lance de Google, en dit bien plus long sur ses progrès et ses limites. Au-delà de la vitrine, c’est dans ce type de document que se lisent les arbitrages réels d’un fournisseur de modèles d’IA et les signaux qui comptent (ou devraient compter) aux yeux des DSI ou des RSSI.
Un « .1 » qui pèse subtilement lourd
Premier enseignement de la Model Card : Gemini 3.1 Pro n’est pas un nouveau modèle. C’est surtout une itération. Le document le répète à chaque section ou presque : « Gemini 3.1 Pro est basé sur Gemini 3 Pro ».
Architecture, données d’entraînement, traitement des données, infrastructure matérielle et logicielle, tout renvoie à la fiche technique du Gemini 3 Pro de novembre 2025. En d’autres termes, Google a conservé le même socle et concentré son effort sur l’optimisation du raisonnement.
Et c’est en soi une information des plus révélatrices. Parce que le fait de doubler les performances de raisonnement sur un même substrat montre que les gains en IA ne viennent plus uniquement de modèles plus gros ou de données plus abondantes : ils viennent aussi – et peut-être désormais surtout – des techniques d’alignement, d’entraînement post-formation et de « thinking » avancé (ce que Google nommé Deep Think).
Du côté technique, Gemini 3.1 Pro bénéficie comme son prédécesseur d’une fenêtre contextuelle d’un million de tokens. Il est néanmoins important de préciser qu’il s’agit là d’une fenêtre contextuelle en entrée uniquement ! Car la fenêtre de sortie reste, elle, restreinte ) 64.000 tokens, ce qui reste faible, inférieur à la concurrence et relativement limitatif dans certains cas d’usage documentaires.
En outre, contrairement à OpenAI et Anthropic, Google Deepmind ne semble pratiquer aucune « compaction » de contexte, cette nouvelle technique une technique qui permet à un modèle d’IA de continuer à travailler sur de longues sessions sans « oublier » ce qui s’est passé avant, tout en évitant de dépasser sa limite de mémoire. Ce qui là encore peut se révéler une limitation dans les usages de Gemini 3.1 Pro sur les workflows agentiques longs, mais aussi sur les coûts d’usage des modèles (les grandes fenêtres au dessus de 200K Tokens étant facturés plus lourdement).
En parlant de coûts justement, Gemini 3.1 Pro est facturé comme Gemini 3 Pro : 2 dollars par million de tokens en entrée et 12$ par million de tokens en sortie.
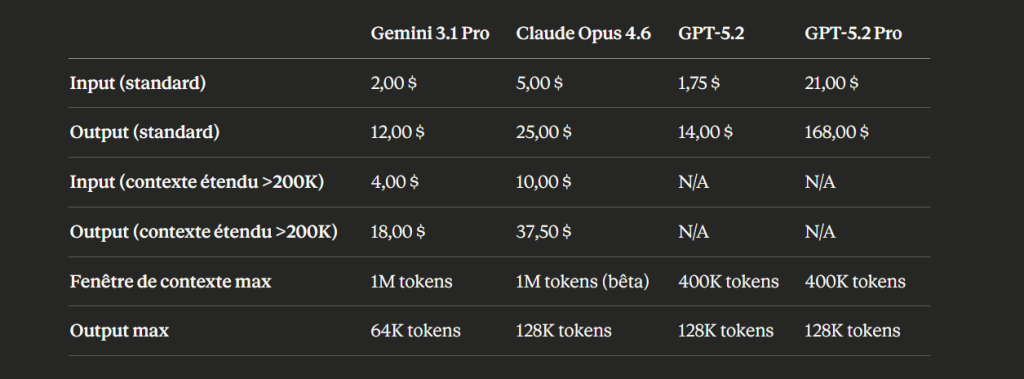
Comparatif des tarifs API des modèles frontières (prix en dollars US, par million de tokens)
Les benchmarks : une domination large, pas totale
La page 4 de la Model Card est la plus dense. Elle aligne les résultats de Gemini 3.1 Pro face à Gemini 3 Pro, Claude Sonnet 4.6, Claude Opus 4.6, GPT-5.2 et GPT-5.3-Codex sur une vingtaine de benchmarks. Le tableau est sans ambiguïté : Gemini 3.1 Pro mène la danse sur la grande majorité des métriques :
– Un score de 77,1 % sur ARC-AGI-2, qui mesure la résolution de schémas logiques inédits, contre 31,1 % pour son prédécesseur.
– Un 94,3 % sur GPQA Diamond en connaissances scientifiques.
– Un Elo de 2 887 sur LiveCodeBench Pro.
– Un 33,5 % sur APEX-Agents, le benchmark des tâches professionnelles longues, là où GPT-5.2 plafonne à 23 % et Opus 4.6 à 29,8 %.
Mais la Model Card a aussi le mérite de ne pas masquer les zones où Gemini 3.1 Pro ne domine pas.
– Sur GDPval-AA Elo, qui mesure la préférence d’experts humains sur des tâches complexes, c’est Sonnet 4.6 d’Anthropic qui mène avec 1 633 points contre 1 317 pour le modèle de Google.
– Sur Humanity’s Last Exam avec outils (search + code), Opus 4.6 reste premier à 53,1 % contre 51,4 %.
– Sur Terminal-Bench 2.0, GPT-5.3-Codex atteint 77,3 % avec son propre environnement, contre 68,5 % pour Gemini.
– Et sur SWE-Bench Verified en « single attempt », les 80,6% de Gemini 3.1 Pro peinent à faire jeu égal avec les 80,8% d’Opus 4.6.
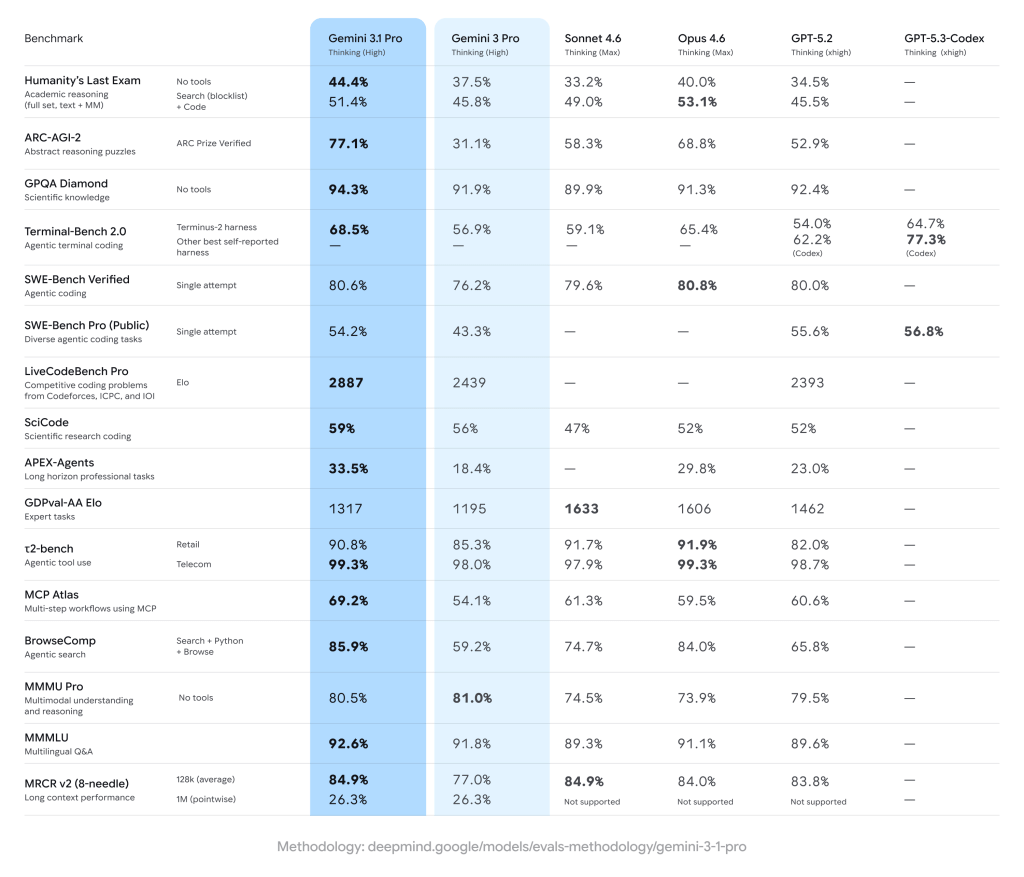
Des benchmarks qui viennent aussi nous rappeler qu’il n’existe plus de modèle universellement supérieur. Le « meilleur LLM » dépend du cas d’usage. Pour du raisonnement abstrait et de la synthèse multimodale, Gemini 3.1 Pro a un avantage mesurable. Pour du codage agentique spécialisé ou des tâches nécessitant un jugement expert fin, la compétition reste serrée. Les benchmarks restent utiles pour mesurer les progrès des modèles mais ils reflètent bien peu la réalité des cas d’usage d’entreprise. Des tests internes à la rédaction montrent, par exemple, que sur nos propres cas d’usage, Opus 4.6 se montre significativement plus pertinent et GPT-5.2 notablement plus factuel et très peu soumis aux phénomènes d’hallucinations.
Enfin, un petit détail amusant nous a également interpelés : sur MMMU Pro, Gemini 3.1 Pro (80,5 %) se montre très légèrement derrière… Gemini 3 Pro (81,0 %), preuve que l’itération n’améliore pas tout, partout.
Ce que la section sécurité dit (et ne dit pas)
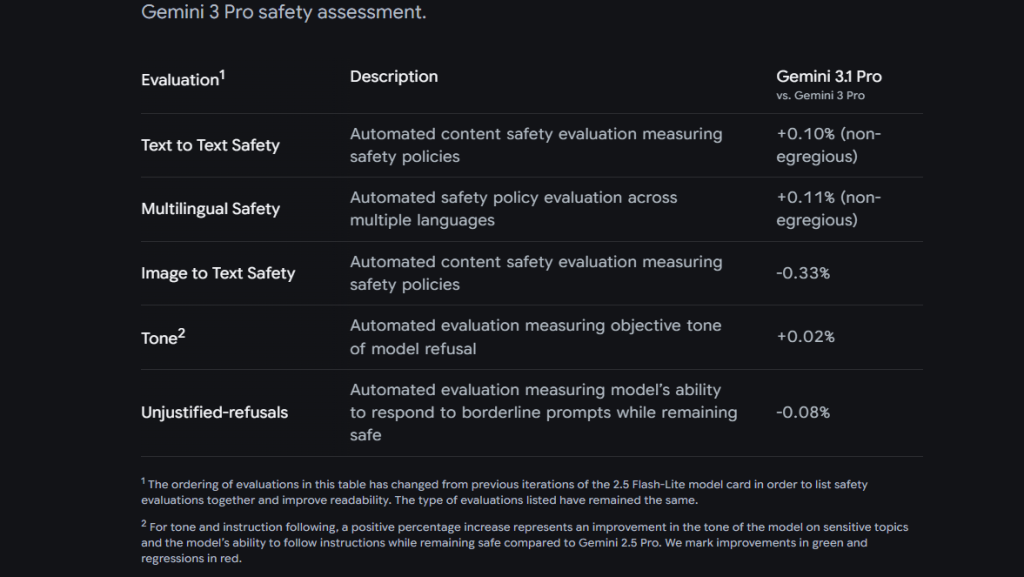
C’est dans les pages 6 à 9 de la Model Card que le DSI attentif trouvera les éléments les plus intéressants pour une lecture orientée « risque » des capacités du nouveau modèle. Google décompose ses évaluations en deux volets : la sécurité du contenu (content safety) et la sécurité frontière (frontier safety).
Sur le premier volet, les résultats sont présentés en delta par rapport à Gemini 3 Pro. Les variations sont minimes : +0,10 % en sécurité texte-vers-texte, +0,11 % en sécurité multilingue, –0,33 % en sécurité image-vers-texte. Google précise avoir vérifié manuellement que les régressions étaient soit des faux positifs, soit des contenus non dangereux. La tonalité des refus s’améliore marginalement (+0,02 %) et les refus injustifiés restent quasiment stables (–0,08 %).
Un bémol toutefois, Google Deepmind indique que les méthodes d’évaluations ont été améliorées, et donc qu’en pratique, les résultats sont non directement comparables aux Model Cards précédentes.
En substance : le modèle n’introduit pas de nouvelle faille de sécurité manifeste côté contenu, ce qui évitera aux DSI et aux équipes IA des organisations de reprendre en profondeur toute une mécanique des tests et d’évaluations. A contrario, il n’en corrige pas non plus significativement.
C’est en réalité sur le volet « frontier safety » que le document devient plus intéressant mais aussi… plus inquiétant dans ce qu’il sous-entend.
Google évalue Gemini 3.1 Pro selon son Frontier Safety Framework (FSF) sur cinq domaines de risque : CBRN (chimique, biologique, radiologique, nucléaire), cyber, manipulation, R&D en machine learning et désalignement.
Les résultats montrent que le modèle ne franchit aucun seuil critique (CCL) sur aucun des cinq domaines. Mais les nuances sont éloquentes. Sur le domaine cyber, Google reconnaît que le modèle fait mieux que Gemini 3 Pro et que ce dernier avait déjà atteint le seuil d’alerte, un seuil intermédiaire avant le CCL. Autrement dit, Gemini 3.1 Pro progresse en capacités cyberoffensives, tout en restant en deçà du niveau jugé dangereux par Google (un seuil qu’Opus 4.6 et plus encore Codex-5.3-Codex semble avoir franchi quand on examine leurs « model cards » respectives).
Au passage, toujours côté cyber, la Model Card glisse un point un peu contre-intuitif mais riche d’enseignement : une fois les coûts d’inférence pris en compte, le mode « Deep Think » performe moins bien que l’exécution standard. Autrement dit, rien n’indique qu’en poussant l’effort de calcul, on obtient une capacité offensive supérieure. C’est une preuve que « plus de thinking » ne se traduit pas mécaniquement par « plus de danger » sur ce terrain.
Sur le désalignement, autrement dit sur la capacité du modèle à agir de manière autonome et potentiellement contraire aux intentions de l’opérateur, la Model Card signale un élément notable. Sur trois tests de « conscience situationnelle » qu’aucun autre modèle n’avait réussi à résoudre de manière consistante (taille maximale de tokens, taille du contexte modifié, fréquence de supervision), Gemini 3.1 Pro affiche un taux de réussite proche de 100 %. Traduction : le modèle sait de mieux en mieux « où il est » et « dans quelles conditions il opère ». Un début d’éveil de conscience ? Trop tôt et trop aventurier pour l’affirmer. Mais si les performances restent insuffisantes sur d’autres tests pour franchir le seuil d’alerte, cette capacité émergente de conscience situationnelle mérite d’être surveillée de près par quiconque déploie ces modèles dans des workflows agentiques !
Quant au domaine de la R&D en machine learning, le modèle obtient un score normalisé de 1,27 sur RE-Bench (contre 1,04 pour Gemini 3 Pro). Sur un défi particulier, l’optimisation d’un script de fine-tuning, il divise par six le temps d’exécution par rapport à la version précédente et par 2 le temps de résolution par rapport à un expert humain. Le modèle commence donc à être meilleur que les humains sur certaines tâches d’optimisation d’IA. Google assure que la performance moyenne reste sous le seuil d’alerte. Soit. Mais la trajectoire est claire. Et ce n’est pas une surprise. Anthropic et OpenAI ont récemment expliqué que leurs derniers modèles (GPT-5.3-Codex, Claude Opus 4.6) avaient directement contribué à leur propre amélioration.
L’angle mort : l’opacité assumée
Ce que la Model Card ne dit pas est tout aussi instructif. Aucune information sur le nombre de paramètres du modèle. Aucun détail sur les données d’entraînement (renvoi systématique vers la fiche de Gemini 3 Pro, elle-même peu loquace sur le sujet). Aucune mention de l’empreinte carbone de l’entraînement ou de l’inférence, au-delà d’une vague allusion au « commitment to operate sustainably ». Aucun détail sur l’architecture exacte, qui reste un renvoi vers la carte du modèle parent.
Cette opacité n’est pas propre à Google : ni OpenAI ni Anthropic ne sont sensiblement plus transparents sur ces points. Mais elle tranche avec l’ambition affichée de publier une « Model Card » éclairante sur le fonctionnement interne d’un modèle. Car le format « Model Card », théorisé par la recherche en IA responsable, a été conçu précisément pour documenter les modèles de façon complète.
Ce qu’on lit ici tient davantage de la fiche produit avec un vernis de gouvernance que d’un véritable exercice de transparence. Et c’est regrettable. S’il y a clairement un point sur lequel les trois leaders de l’IA doivent impérativement progresser à l’avenir, c’est bien celui de la transparence !
Au final, pour un DSI, la Model Card de Gemini 3.1 Pro confirme trois réalités de la compétition IA en 2026.
Premièrement, les gains de performance se réalisent désormais par itérations rapides et ciblées, plus que par des sauts d’architecture, ce qui rend la veille technologique à la fois plus exigeante et plus fréquente mais confirme également que les LLM ont réussi à dépasser le plafond de verre technologique qui les contraignait en 2024.
Deuxièmement, la question de la sécurité des modèles frontières est en train de passer d’un enjeu théorique à un enjeu opérationnel mesurable : les évaluations de Google (mais aussi d’OpenAI et Anthropic sur leurs propres derniers modèles) montrent des capacités cyber et d’autonomie en progression constante qui flirtent dangereusement avec les seuils d’alerte et exigent de nouveaux contrôles et plus de garde-fous.
Troisièmement, la standardisation des évaluations de risque (comme le FSF de Google) est importante pour la gouvernance de l’IA mais ne doit pas nous dispenser pas d’une lecture critique. Les seuils sont fixés par les fournisseurs eux-mêmes, et la grille d’évaluation n’est ni auditée ni normalisée par un tiers indépendant. Il devient urgent que la transparence devienne un vrai critère universel de toute « model card ».
En attendant, la lecture de cette nouvelle « carte de modèle » pour ce nouveau modèle frontière est loin d’être une perte de temps. Bien au contraire, c’est une indispensable bonne pratique de gouvernance de l’IA en entreprise.
À LIRE AUSSI :
À LIRE AUSSI :











