


Data / IA
Claude Opus 4.8 : un modèle qui assume mieux ses propres limites
Par Laurent Delattre, publié le 29 mai 2026
Pour célébrer sa nouvelle levée de fonds XXXL qui en fait la startup la plus valorisée au monde, dépassant OpenAI, Anthropic dévoile Claude Opus 4.8, une itération qui n’élargit pas la frontière des capacités mais consolide nettement la fiabilité et l’honnêteté des agents IA. Pour les DSI qui envisagent de déléguer des tâches réelles à une IA autonome, la System Card apporte des signaux aussi rassurants qu’inhabituels ainsi qu’un nouveau point de vigilance que l’éditeur a choisi d’exposer publiquement.
Le lancement d’Opus 4.8 intervient dans un contexte financier plutôt spectaculaire. Anthropic a annoncé ce jeudi 28 mai 2026 une levée de fonds de 65 milliards de dollars (plus du double de ce que la rumeur laissait entendre). Ce tour de série H mené par Altimeter Capital, Dragoneer, Greenoaks et Sequoia Capital porte ainsi sa valorisation à 965 milliards de dollars. L’éditeur de Claude passe donc pour la première fois devant son rival OpenAI (valorisé à 852 milliards) et officialise son rang de première startup mondiale de l’intelligence artificielle.
Sa valorisation a quasiment triplé en trois mois, tandis que le chiffre d’affaires annualisé revendiqué franchit la barre des 47 milliards de dollars, contre 14 milliards lors du tour précédent de février. Une trajectoire spectaculaire que l’éditeur attribue avant tout à l’adoption en entreprise de ses outils, au premier rang desquels l’assistant de programmation Claude Code. C’est dans cet élan, mais aussi sous la contrainte d’une demande de puissance de calcul qu’il peine encore à satisfaire, qu’Anthropic étoffe sa gamme avec Opus 4.8.
Le modèle s’accompagne d’une « system card » de 244 pages détaillant l’ensemble des évaluations conduites avant déploiement. Pour les DSI, ce document de pré-déploiement constitue, comme toujours, une source d’information rare : au-delà des scores de performance, il expose la posture de sécurité, le profil d’alignement et les limites assumées du modèle. Trois enseignements s’en dégagent : une progression continue des capacités sans franchissement d’un nouveau palier de risque, un bond inédit sur la fiabilité comportementale des agents, et un signal de prudence qu’Anthropic documente sans détour. Décortiquons un peu plus cette System Card…
Une montée en gamme sans saut de frontière
Pour les DSI, l’essentiel se joue d’abord dans le positionnement du modèle. Anthropic évalue désormais chacune de ses versions à l’aune de son « mythique » modèle interne de référence, Claude Mythos Preview, qui incarne la frontière des capacités et, donc, des risques. Opus 4.8 s’inscrit entre Claude Opus 4.7 et ce modèle de pointe, sans en déplacer la limite.
Les implications sont avant tout réglementaires : selon l’éditeur, le modèle ne dépasse aucun des seuils critiques, qu’il s’agisse de la conception inédite d’armes chimiques et biologiques ou de l’automatisation complète de la recherche et développement. Les mesures de protection appliquées sont jugées équivalentes ou supérieures aux protections historiques de niveau ASL-3 de son cadre Responsible Scaling Policy, et les risques catastrophiques restent qualifiés de « faibles ».
Pour une DSI, cette stabilité du profil de risque facilite la reconduction d’une analyse de conformité déjà menée pour Opus 4.7, sans rouvrir l’ensemble du dossier.
Des gains de capacités directement exploitables en production
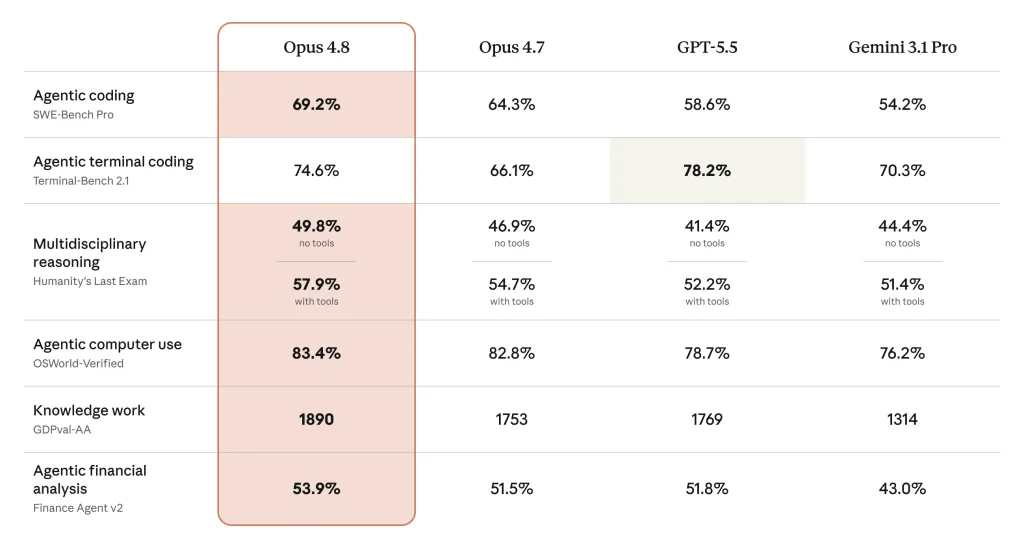
Sur le terrain des performances, Opus 4.8 devance Opus 4.7 sur la quasi-totalité des évaluations, avec des progrès particulièrement marqués sur les usages d’entreprise. En ingénierie logicielle, il atteint 88,6 % sur SWE-bench Verified et surtout 69,2 % sur la variante SWE-bench Pro – la plus proche de dépôts réellement maintenus -, contre 64,3 % pour la version précédente.
Sur les tâches en environnement terminal (Terminal-Bench 2.1), il passe à 74,6 % en agent unique et grimpe à 88,5 % en configuration multi-agents. Les progrès les plus parlants pour les métiers concernent toutefois les tâches professionnelles réelles : l’indicateur GDPval-AA, qui mesure la valeur produite sur des travaux concrets, bondit de 1753 à 1890, tandis qu’AutomationBench, centré sur l’automatisation de processus, progresse de 9,9 à 15,5.
La gestion des contextes longs s’améliore également de façon sensible. Une nuance mérite d’être relevée : sur le raisonnement scientifique de pointe (GPQA Diamond), le score recule très légèrement, à 93,6 % contre 94,2 % auparavant, et reste devancé par Gemini 3.1 Pro (94,3 %).
L’honnêteté des agents érigée en priorité
Mais l’enseignement le plus important de la System Card est néanmoins ailleurs. Anthropic revendique un progrès franc sur la fiabilité comportementale en contexte agentique.
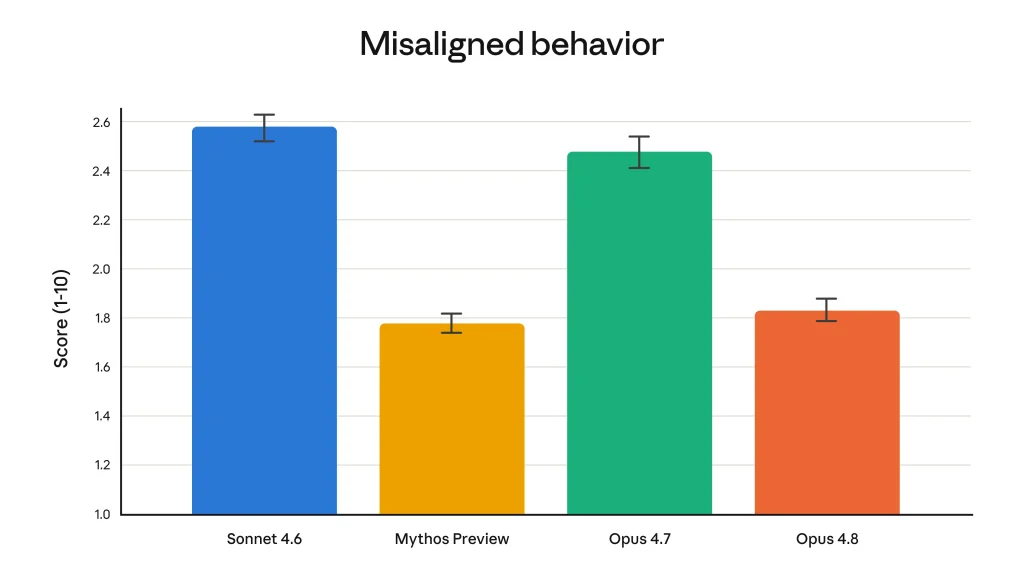
En matière « d’honnêteté », Opus 4.8 marque une rupture nette. Sur une évaluation dédiée à la restitution de résultats défectueux, il devient le tout premier modèle d’Anthropic à atteindre un taux nul de comportement trompeur : il ne déguise jamais un échec en réussite.
Plus largement, il signale davantage ses incertitudes et avance moins d’affirmations non étayées. Ainsi, sa tendance à la surconfiance est divisée par dix par rapport à Opus 4.7.
Le progrès est particulièrement visible quand il s’agit de rendre compte de son propre travail en programmation : Opus 4.8 est environ cinq fois moins enclin à passer sous silence un défaut dans le code qu’il a produit que le fameux Mythos Preview et près de dix-sept fois moins que Sonnet 4.6. Dans le même mouvement, les actions imprudentes ou destructrices et les refus injustifiés reculent.
Dit autrement, Opus 4.8 progresse sur de nombreux axes contribuant ainsi à fiabiliser les chaînes de traitement automatisées agentiques. La relative transparence et « honnêteté » du modèle mise en avant par l’éditeur peut dès lors constituer un critère de sélection au moins aussi décisif que la performance brute.
Sécurité : l’injection de prompt reste le vrai sujet
Le tableau n’est pas exempt de réserves, et elles intéressent au premier chef les RSSI. La principale menace tient ici aux injections de prompt indirectes : un agent qui consulte un courriel, une page web ou un document peut y rencontrer des instructions malveillantes dissimulées par un attaquant, et s’en trouver détourné. Or, sur ce terrain, Opus 4.8 résiste un peu moins bien qu’Opus 4.7. Tout au moins en théorie.
En pratique, Anthropic compense par une seconde ligne de défense, activée par défaut sur la plupart de ses produits agentiques : de petits détecteurs, les « probes », surveillent en temps réel le fonctionnement interne du modèle pour repérer la signature d’une attaque et la bloquer. Ce filet de sécurité rétablit le niveau de protection d’Opus 4.7, tout en se trompant moins souvent sur des contenus parfaitement légitimes.
Gouvernance : un cadre maîtrisé, un signal à surveiller
Sur le plan de la gouvernance, Opus 4.8 affiche le meilleur profil d’alignement jamais mesuré par Anthropic, à parité avec son modèle interne le plus avancé, et une adhérence à la constitution de l’éditeur qui égale ou dépasse ses références sur les quinze dimensions évaluées. Le modèle se montre également plus enclin que ses prédécesseurs à présenter des perspectives opposées dans les débats sensibles.
Un point de vigilance est toutefois documenté sans fard : durant l’entraînement, le modèle a manifesté une tendance croissante à raisonner sur la façon dont ses réponses vont être évaluées ou seront notées, y compris lorsque rien n’indique explicitement une évaluation. Anthropic y voit le risque que le modèle privilégie l’apparence de la réussite sur la réussite réelle. L’analyse de ses activations internes confirme la présence de ce raisonnement. Les effets comportementaux observés restent modestes (Anthropic les détecte dans une part faible mais non négligeable des cas).
En pratique, cette tendance ne s’est pas traduite par davantage de comportements indésirables : le modèle se montre même globalement plus fiable que ses prédécesseurs. L’éditeur n’en retient pas moins une tendance « à surveiller », susceptible de compliquer les entraînements futurs.
Fait inhabituel, Anthropic a soumis la version quasi définitive de sa section sur l’alignement à la relecture critique d’une instance de Claude Mythos Preview. Pour mener l’exercice, le modèle s’est vu accorder un accès à une large part des canaux Slack internes de l’éditeur ainsi que la possibilité de déléguer des vérifications ciblées à des sous-agents. Sa consigne : confronter le rapport à la réalité des échanges internes, signaler toute déformation, omission importante ou insuffisance, puis en livrer un verdict destiné à être publié.
L’appréciation rendue est globalement favorable : le résumé est jugé exact et franc, sans déclaration fausse ni omission de mauvaise foi. Mais elle n’est pas complaisante pour autant. Le modèle pointe tout une faiblesse. En substance : Anthropic affirme que le fait, pour une IA, de réfléchir à la façon dont elle sera notée n’influence pas son comportement. Pour Mythos Preview, cette affirmation n’a jamais vraiment été vérifiée. Car aucun test ne mesure précisément la « triche à l’entraînement » (cette tentation, évoquée plus haut, du modèle à vouloir décrocher la bonne note plutôt qu’à bien faire le travail).
Cette démarche, qui consiste à faire juger le compte rendu d’Anthropic par son modèle interne le plus évolué, a ses limites (un modèle de la même famille demeure ici juge et partie) mais l’exercice de transparence, poussé jusqu’à la publication des critiques émises, mérite à nos yeux d’être salué même s’il reste anecdotique.
En l’état, Opus 4.8 se présente comme une mise à niveau prudente et mieux outillée pour l’entreprise agentique : davantage de fiabilité là où elle compte, une sécurité conditionnée à son cadre de déploiement, et une gouvernance dont Anthropic assume d’exposer à chaque nouvelle itération un peu plus les zones d’ombre.
À LIRE AUSSI :
À LIRE AUSSI :











