Green IT
La Chine revient dans le TOP500 des HPC et en prend la tête avec ses propres processeurs
Par Laurent Delattre, publié le 24 juin 2026
Après près de 5 ans de silence et de refus de participer au classement des 500 HPC les plus puissants de la planète, la Chine fait officiellement son retour dans le « TOP500 » et s’empare d’emblée de la première place. Mais cet événement IT est loin d’être le seul enseignement des nouveaux palmarès Top500 et Green500.
La publication bi-annuelle du classement TOP500 des 500 supercalculateurs les plus puissants de planète est toujours un évènement. Elle offre un regard technique non seulement sur la progression technologique des supers ordinateurs HPC mais aussi sur les efforts réalisés en matière d’optimisation des consommations énergétiques (via le classement GREEN500) et plus encore sur les grands équilibres géopolitiques du calcul intensif. Car derrière les scores HPL, les processeurs, les accélérateurs et les interconnexions se dessine une autre cartographie : celle des nations capables de mobiliser des infrastructures extrêmes pour la recherche, l’industrie, la défense, le climat, l’énergie ou désormais l’intelligence artificielle.
La publication cette semaine du premier classement « 2026 » est riche de nombreux enseignements :
– La Chine fait son retour. Pékin avait cessé de jouer pleinement le jeu du TOP500 dès 2021-2022, en ne soumettant plus ses machines les plus avancées.
– On pensait que le pays disposait d’ordinateurs exaflopiques mais il n’en existait pas de preuve concrète. Aujourd’hui, preuve est faite. Et non seulement la Chine dispose bien de machines exaflopiques mais elle dispose surtout de la plus puissante d’entre elles, grillant la politesse aux américains.
– Le LineShine Chinois atteint la performance exaflopique en s’appuyant exclusivement sur des CPU chinois et sans utiliser de « GPU IA avancés ».
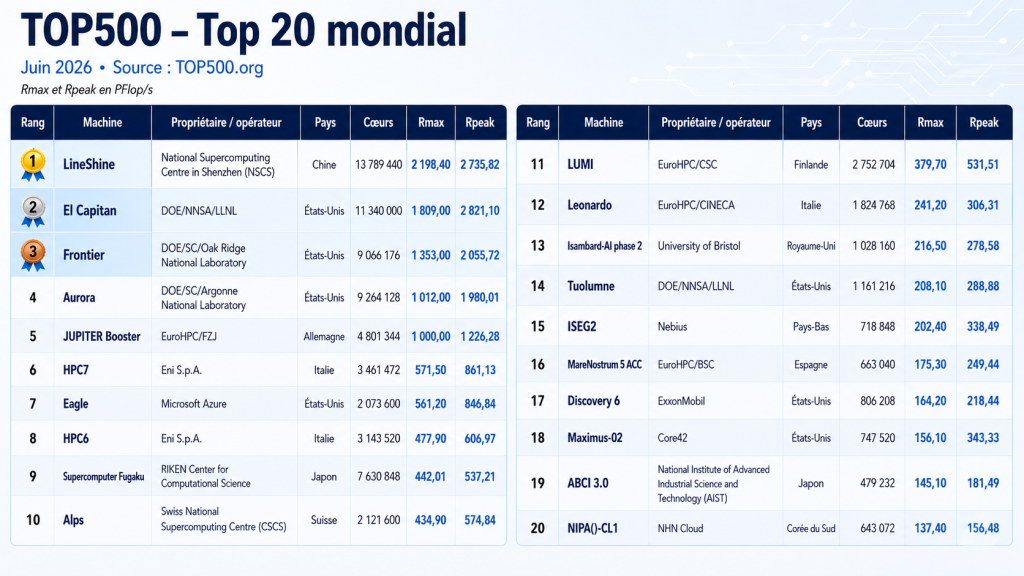
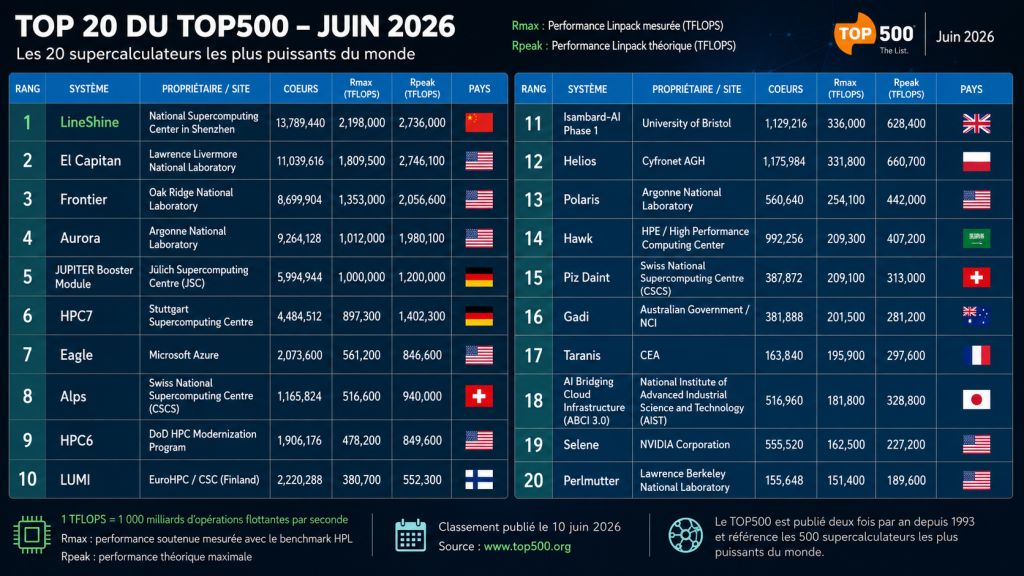
– Le monde est bien entré dans l’ère exaflopique : Cinq systèmes publics sont désormais officiellement exascale : LineShine, El Capitan, Frontier, Aurora et JUPITER Booster.
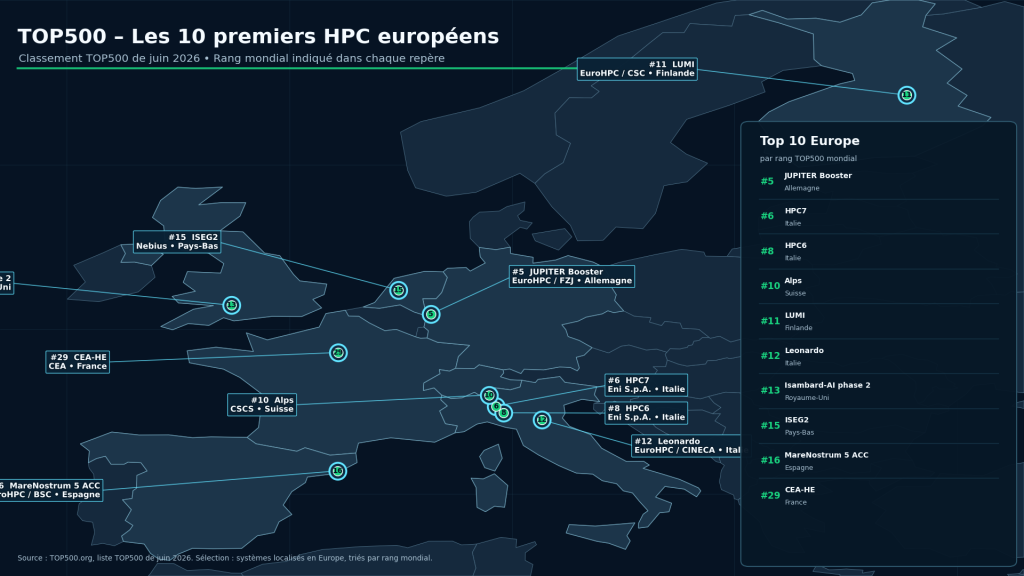
– L’Europe fait officiellement son entrée dans le clan des entités disposant de machines exaflopiques. Bien qu’encore incomplet, le JUPITER (via son seul module Booster) atteint officiellement la barre du 1 exaflop.
– La France brille dans le Green500. KAIROS et ROMEO-2025 occupent les deux premières places mondiales de l’efficacité énergétique (classement Green500). Cocorico discret, mais très significatif. Et Bravo à Bull/Eviden qui occupe les 3 premières places !
– NVIDIA reste l’écrasant maître de la stack HPC. Ses technologies GPU ou Superchips équipent plus de 400 des 500 systèmes (81 %) et près de 9 nouveaux entrants sur 10. Néanmoins, c’est bien AMD qui domine sur les processeurs CPU du Top 10.
– Le GPU NVIDIA Grace Hopper règne sur l’efficacité. Les 8 premiers HPC du Green500 tournent sur GPU NVIDIA, 9 des 10 premiers sur sa technologie, les 4 premiers étant des superchips « Grace Hopper ».
– Le ticket d’entrée dans le TOP500 est désormais au-dessus des 2,66 Pétaflops.
– Le classement perd en représentativité. Les hyperscalers (Microsoft, Amazon, Meta, xAI…) n’y soumettent quasiment plus leurs infrastructures IA, pourtant bien plus massives.
Entrons un peu plus dans le détail des classements…
LineShine, le nouveau maître du monde
L’édition de juin 2026 restera, à ce titre, comme l’une des plus symboliques de ces dernières années. La Chine y reprend la première place mondiale avec LineShine, un système installé au National Supercomputing Centre de Shenzhen. Une première depuis Sunway TaihuLight en 2017. Mais ce retour au sommet vaut autant pour sa performance que pour le signal qu’il envoie. Depuis 2021-2022, Pékin avait largement cessé d’exposer ses machines les plus stratégiques au regard public du TOP500. Des systèmes chinois continuaient bien d’apparaître dans le classement, mais les supercalculateurs les plus avancés, notamment ceux soupçonnés d’avoir franchi ou approché l’exascale, restaient hors champ.
Derrière ce retour au sommet se cache bien sûr un message implicite de Pékin : les contrôles à l’export de Trump ne nous arrêtent pas !
Et dire que LineShine intrigue est un euphémisme. La machine atteint le sommet sans s’appuyer sur des GPU IA avancés visibles, et en étant exclusivement animé par des puces de conception Chinoise (basées sur l’architecture ARM).
Sur le plan matériel, LineShine repose sur une plateforme maison baptisée « LingKun », totalement dépourvue d’accélérateurs GPU là où huit des dix premières machines du classement en exploitent.
Cette plateforme imaginée par Shenzhen Cloud Computing Center. Elle s’appuie à la fois sur une interconnexion propriétaire LingQi (qui offre 1,6 Tb/s par nœud) et sur des processeurs « LX2 » à 304 cœurs cadencés à 1,55 GHz.
Le concepteur exact des processeurs n’a pas été officiellement révélé, mais la majorité des analystes l’attribuent sans détour à Huawei (vraisemblablement sa division HiSilicon), seul ou en co-conception avec le centre de Shenzhen. Chaque puce assemble deux chiplets de calcul. L’architecture assemble les 304 cœurs en huit clusters de 38 cœurs, et dote chacun d’eux des extensions vectorielles SVE et des unités matricielles SME (Scalable Matrix Extension). Ce sont précisément ces unités SME qui permettent à un CPU de jouer, en partie, le rôle d’un accélérateur : le LX2 gère nativement les formats FP64, FP32, BF16, FP16 et INT8, et délivre à lui seul 60,3 TFLOPS en FP64, 240 TFLOPS en BF16/FP16 et 960 TOPS en INT8.
L’organisation mémoire est sans doute l’élément le plus original du design. Chaque LX2 embarque 32 Go de HBM directement sur le boîtier (jusqu’à 4 To/s de bande passante), épaulés par de la DDR classique hors package, un moteur SDMA dédié orchestrant les transferts entre les deux niveaux. Cette hiérarchie HBM + DDR pilotée matériellement évoque davantage la logique d’un APU MI300A d’AMD que celle d’un CPU serveur traditionnel.
Le tout est chapeauté par le système d’exploitation chinois Kylin OS.
Le système aligne 13 789 440 cœurs, soit environ 45 360 processeurs LX2 si l’on rapporte ce total aux 304 cœurs annoncés par puce. Sur HPL, la machine atteint les 2,198 exaflops soutenus pour un pic théorique de 2,736 exaflops, soit environ 80 % de rendement Linpack.
Cela en fait le premier système officiellement classé à dépasser 2 exaflops HPL soutenus.
Au passage on notera que le El Capitan américain s’offre un pic théorique supérieur au LineShine, mais la machine chinoise convertit un peu mieux sa puissance brute en performance soutenue, ce qui lui suffit pour ravir la première place. Elle s’offre au passage le sommet du classement HPCG (22 Pétaflops), bien plus représentatif des charges mémoire et communication intensives.
Reste l’addition énergétique : 42,2 MW engloutis pour une efficience de 52,07 GFlops/W, là encore en retrait des 60,94 GFlops/W d’El Capitan. Un détail qui a son importance, nous y reviendrons. La Chine reprend la couronne de la puissance brute, mais pas celle de la sobriété.
Reste un point qui sera probablement difficile à confirmer. Officiellement, LineShine aurait été développé sans financement public direct, ce qui aurait précisément autorisé ses concepteurs à le soumettre au TOP500.
Les USA glissent trois machines exaflopiques dans le TOP500
Détrônés mais loin d’être distancés, les États-Unis conservent une profondeur de banc inégalée avec trois systèmes au-dessus de la barre de l’exaflop.
El Capitan, installé au Lawrence Livermore National Laboratory et dédié à la simulation de l’arsenal nucléaire américain, glisse de la première à la deuxième place sans bouger d’un iota : son score reste figé à 1,809 Exaflops sur HPL. Ce HPE Cray EX255a aligne 11 340 000 cœurs, mariant des processeurs AMD EPYC de 4ᵉ génération (24 cœurs à 1,8 GHz) aux accélérateurs AMD Instinct MI300A, sur réseau Slingshot 11.
Surtout, El Capitan prend une éclatante revanche sur le terrain qui compte vraiment pour l’IA : il demeure n°1 du classement HPL-MxP (précision mixte) avec 16,7 Exaflops, très loin devant LineShine.
Derrière, le tableau est tout aussi stable. Frontier, le pionnier de l’exascale inauguré à Oak Ridge en 2022, conserve sa troisième place avec 1,353 Exaflops (HPE Cray EX235a, EPYC 3ᵉ génération 64 cœurs à 2 GHz, 9 066 176 cœurs, Slingshot 11). Aurora, au Argonne National Laboratory, complète ce trio à la quatrième position avec 1,012 Exaflops, seul représentant d’une architecture entièrement Intel au sommet du classement.
Aucune de ces trois machines n’a vu ses performances évoluer depuis l’édition de novembre 2025 : elles sont au plafond de leur configuration. Le bouleversement de juin 2026 ne tient donc pas à une régression américaine, mais bien à l’irruption d’un nouvel entrant chinois par le haut.
Pour reprendre l’avantage, Washington mise sur une nouvelle vague de systèmes déjà commandés mais pas encore opérationnels, tous tournés vers l’IA.
Le premier jalon, Lux, doit être déployé à Oak Ridge dès le début 2026 : co-développé par l’ORNL, AMD, HPE et Oracle Cloud Infrastructure, ce cluster bâti sur plateforme HPE ProLiant Compute XD685 associe GPU AMD Instinct MI355X, CPU EPYC et réseau Pensando. Présenté comme la première « AI Factory » scientifique souveraine des États-Unis, il viserait environ trois fois la capacité IA des systèmes actuels du laboratoire.
Le coup d’après s’appelle Discovery. Successeur déclaré de Frontier, ce système exascale de deuxième génération est attendu pour une livraison en 2028 et une mise en service en 2029. Il inaugurera la nouvelle plateforme HPE Cray Supercomputing GX5000, animée par les futurs processeurs AMD EPYC « Venice » (6ᵉ génération) et les accélérateurs AMD Instinct MI430X de la série MI400, taillés pour l’IA souveraine et le calcul scientifique, avec un stockage K3000 à base de DAOS et la nouvelle génération d’interconnexion Slingshot.
Troisième fer de lance, et non des moindres : Doudna (alias NERSC-10), la future machine phare du NERSC, au Lawrence Berkeley National Laboratory. Baptisée en hommage à Jennifer Doudna (prix Nobel de chimie 2020 pour CRISPR), elle tranche avec ses deux cousines à un double titre. D’abord par son intégrateur : c’est Dell Technologies qui décroche le contrat, brisant la série des trois précédents plus gros systèmes du DOE, tous confiés à HPE. Ensuite par son silicium : là où Lux et Discovery misent sur AMD, Doudna fait le pari de la plateforme NVIDIA Vera Rubin (CPU Arm « Vera » + GPU « Rubin »), sur serveurs Dell à refroidissement liquide direct, réseau Quantum-X800 InfiniBand et NVLink. Annoncée pour une livraison fin 2026, elle promet au moins dix fois la performance de Perlmutter — l’actuel fleuron du centre — pour une enveloppe énergétique inférieure à 20 MW. Son système d’accès anticipé, « Cech » (72 CPU Grace et 144 GPU Blackwell, précurseurs de Vera Rubin), a d’ailleurs déjà été livré en janvier 2026. Pensée pour la convergence simulation + IA + données expérimentales en temps réel, et connectée aux grands instruments du DOE via le réseau ESnet, Doudna incarne, plus encore que Discovery, le basculement américain vers des infrastructures conçues d’abord pour l’IA scientifique.
Ces trois machines dessinent la trajectoire recherchée par les US : ne pas se contenter de reprendre la tête du HPL, mais construire des plateformes post-exascale capables de servir simultanément la simulation scientifique, l’IA, la fusion, la biologie, la cybersécurité et la défense.
L’Europe entre dans l’ère exaflopique et soigne ses consommations énergétiques
L’événement, pour le Vieux Continent, porte un nom : JUPITER. Avec exactement 1,000 Exaflops sur HPL, il s’installe à la cinquième place mondiale et devient, enfin, très officiellement, le premier système exascale européen. Opéré par le Jülich Supercomputing Centre pour le compte d’EuroHPC, JUPITER repose sur l’architecture BullSequana XH3000 d’Eviden, à refroidissement liquide direct, pour un budget de 500 millions d’euros incluant six années d’exploitation et un datacenter modulaire d’une cinquantaine de conteneurs étalé sur 2 300 m².
Mais la cinquième place du JUPITER n’est que temporaire. Car contrairement aux machines américaines sa conception est loin d’être terminée. Son score ne mesure que son seul module « Booster » : environ 6 000 nœuds embarquant chacun quatre superchips NVIDIA GH200 Grace Hopper, soit près de 24 000 GH200, reliés en InfiniBand NDR200. Ce module GPU permet à lui seul au JUPITER de franchir la barre de l’exaflop.
Mais la machine est encore loin d’être complète. Il lui manque sa vraie brique souveraine, le module « Cluster », généraliste et dédié aux codes peu friands d’accélérateurs. Il sera animé par le tout premier processeur HPC européen, le Rhea1 de la deeptech SiPearl : 80 cœurs Arm Neoverse V1 (« Zeus »), deux moteurs vectoriels SVE de 256 bits par cœur, 64 Go de HBM2e épaulés par 512 Go de DDR5 par nœud, le tout sur une puce de plus de 61 milliards de transistors gravée en 6 nm chez TSMC. Le module agrégera environ 1 300 nœuds à deux Rhea1 chacun. Après un bring-up (campagne de validation matérielle) lancé le 13 mai 2026 et étalé sur douze semaines, Rhea1 vise une disponibilité commerciale d’ici la fin 2026, date à laquelle le module Cluster pourra à son tour entrer en service.
Au passage, rappelons que SiPearl prépare déjà un « Rhea2 » destiné au second exascale européen, le français Alice Recoque (542 millions d’euros, lui aussi confié à Eviden).
Si l’Europe peut être fière de sa cinquième place dans le domaine de la performance brute, elle doit aussi se féliciter de ses résultats sur le terrain de l’efficacité énergétique.
Car l’Europe écrase la concurrence. Le Green500, qui re-classe les machines du TOP500 à l’aune des Gigaflops délivrés par watt, voit un trio strictement européen trôner en tête. Et, cocorico, les deux premiers HPC les plus efficients sont français.
KAIROS, installé au centre CALMIP de l’Université de Toulouse-CNRS, conserve sa couronne mondiale avec 73,28 GFlops/W (pour 3,046 Pétaflops HPL).
ROMEO-2025, hébergé au centre de calcul ROMEO de Champagne-Ardenne (Université de Reims), prend la deuxième place avec 70,91 GFlops/W (9,863 Pétaflops, 47 328 cœurs).
L’extension GPU du système Levante, au centre climatique allemand DKRZ, complète le podium à 69,43 GFlops/W (6,747 Pétaflops).
Le point commun de ces trois machines ? Une architecture rigoureusement identique : des BullSequana XH3000 bâtis autour des superchips NVIDIA GH200 Grace Hopper (72 cœurs à 3 GHz) et d’un réseau Quad-Rail NVIDIA InfiniBand NDR200. Elles avaient toutes trois fait leur entrée sur la liste précédente il y a six mois, et leur ordre n’a pas bougé.
Pour Bull/Eviden, c’est un doublé historique : cinquième édition consécutive à la première place du Green500, et deuxième podium 100 % maison d’affilée, le constructeur revendiquant par ailleurs 59 systèmes au TOP500.
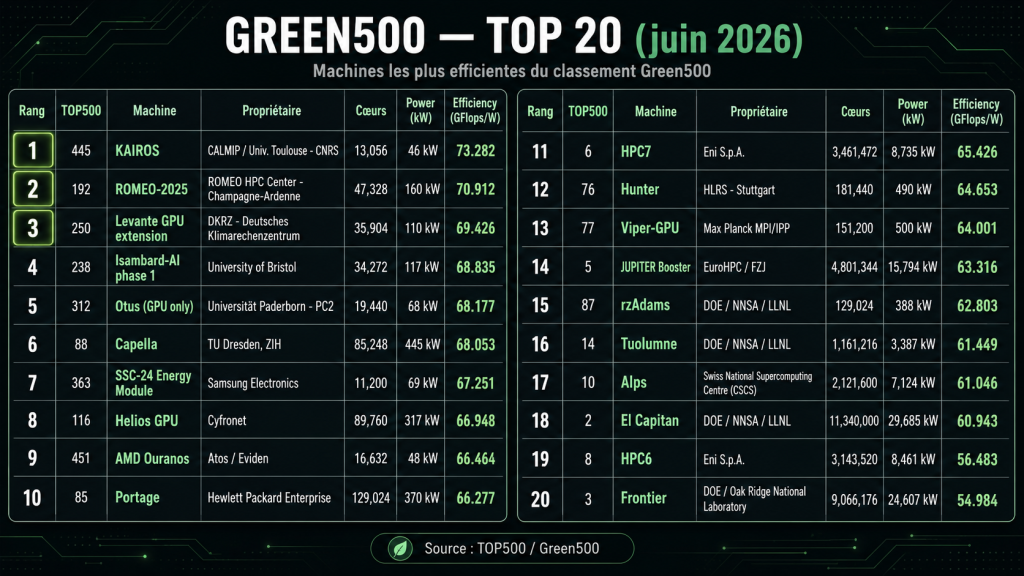
Cette hiérarchie illustre un phénomène contre-intuitif que les DSI gagneront à méditer : à technologie identique, ce sont systématiquement les petites installations qui devancent les grandes en efficacité. La raison tient aux interconnexions, dont les performances ne progressent pas linéairement avec la taille : plus une machine grandit, plus la part d’énergie consacrée à faire dialoguer les nœuds pèse sur le rendement global. Petit = vert. L’exemple le plus parlant n’est autre que JUPITER lui-même : environ 333 fois plus puissant que KAIROS pour une architecture voisine, il ne plafonne qu’à 63,3 GFlops/W, ce qui le relègue à la 14ᵉ place du Green500.
Le paradoxe LineShine est l’exact miroir de cette logique. La machine chinoise écrase le TOP500, mais ne pointe qu’autour de la 50e place du Green500. Elle avale 42,2 MW et atteint environ 52 gigaflops par watt (très loin des 73 GFlops/W du sommet vert). La puissance chinoise se paie donc en watts. À l’inverse, JUPITER Booster, bien plus massif que KAIROS mais beaucoup plus efficace que LineShine ou Aurora, illustre la voie européenne : atteindre l’exascale sans exploser totalement l’équation énergétique.
Une nuance, toutefois, mérite d’être apoortée : à l’échelle des architectures CPU-only, LineShine pulvérise son aîné Fugaku (15 à 17 GFlops/W selon les optimisations). L’approche tout-CPU reste structurellement gourmande face au GPU, mais la Chine a réalisé un bond générationnel sur l’efficacité de ses propres puces.
Mais où sont passés les hyperscalers ?
Derrière le théâtre des grandes puissances étatiques se cache un angle mort de plus en plus béant. Le TOP500 reste, par construction, un classement de volontaires : il agrège pour l’essentiel des systèmes académiques et gouvernementaux dont les exploitants acceptent de soumettre leurs mesures.
Or les véritables monstres de calcul de notre époque ne sont plus là. Microsoft, Amazon, Meta, Alphabet, xAI : les hyperscalers qui façonnent la révolution IA n’y inscrivent quasiment plus leurs infrastructures, pourtant infiniment plus massives que la plupart des machines classées.
Le seul vrai représentant du cloud dans le Top 10 est le désormais presque ancestral « Eagle » de Microsoft (Azure, 7ᵉ avec 561,2 Pétaflops, processeurs Xeon Platinum 8480C et GPU NVIDIA H100).
Pour le reste, l’essentiel de la capacité IA mondiale échappe donc au radar. L’ordre de grandeur a de quoi donner le vertige : selon une estimation de chercheurs de Cornell, El Capitan, n’atteindrait qu’environ 22 % de la performance de calcul du seul Colossus de xAI, déployé à Memphis et absent du classement.
La réalité, c’est que les hyperscalers pourraient probablement s’emparer des premières places du TOP500 s’ils le souhaitaient. Mais, ils ne le souhaitent pas. Pour ne pas dévoiler d’informations confidentielles à la concurrence. Pour ne pas mobiliser des ressources dynamiques onéreuses à des fins non commerciales. Pour ne pas rentrer dans un « jeu académique » où ils n’ont pas leur place parce qu’ils n’ont pas, eux, à justifier des financements multiples. Et parce que le HPL mesure, de leur point de vue, la mauvaise chose. Le test Linpack évalue la double précision (FP64), un format dont les infrastructures IA n’ont quasiment aucun usage, leurs accélérateurs étant taillés pour le BF16 ou le FP8. Un score HPL ne refléterait donc pas leur véritable valeur, il la sous-estimerait, tout en engloutissant une fortune en calcul. Le jeu n’en vaut littéralement pas la chandelle.
Dit autrement, le classement TOP500 demeure un formidable instrument de mesure de la puissance souveraine et académique, mais il ne dit plus grand-chose de l’endroit où se concentre réellement la puissance de calcul de la planète.
Les IA Factories mal représentées
Le décrochage entre puissance affichée et puissance utile pour l’IA est sans doute l’enseignement le plus structurant de l’édition. Car dominer le HPL ne signifie pas, de nos jours, dominer l’IA. Le benchmark Linpack mesure une opération bien précise – la résolution de systèmes linéaires denses en double précision (FP64) – qui est le pain quotidien de la simulation scientifique, mais qui n’a plus grand-chose à voir avec l’entraînement et l’inférence des grands modèles, lesquels carburent à la précision mixte.
Or c’est précisément là que LineShine décroche. Sur le HPL-MxP, le benchmark conçu pour refléter les charges IA en précision mixte, le n°1 mondial du HPL ne pointe qu’en quatrième position avec 7,92 Exaflops et une accélération somme toute modeste de 3,6x. La rançon de son design exclusivement CPU, dépourvu des accélérateurs qui font merveille sur ces formats. El Capitan, lui, trône en tête de ce classement avec 16,7 Exaflops. La machine la plus puissante du monde pour la science classique se retrouve devancée par trois systèmes américains dès que l’on bascule sur des charges typées IA.
NVIDIA ne se prive d’ailleurs pas de le souligner, en revendiquant pour ses systèmes plus de 2x le débit d’entraînement et près de 3x le débit d’inférence de toutes les autres plateformes réunies.
On pourra donc regretter que le TOP500 reste avant tout un thermomètre du HPC, pas un palmarès des « AI Factories ». Ces dernières obéissent à une logique de conception différente, optimisée pour le training et l’inférence plutôt que pour le FP64. Peut-être est-il désormais l’heure d’un vrai palmarès « AI500 » plus parlant que le classement livré par le benchmark HPL-MxP.
Une lutte Nvidia vs AMD. Et Intel alors ?
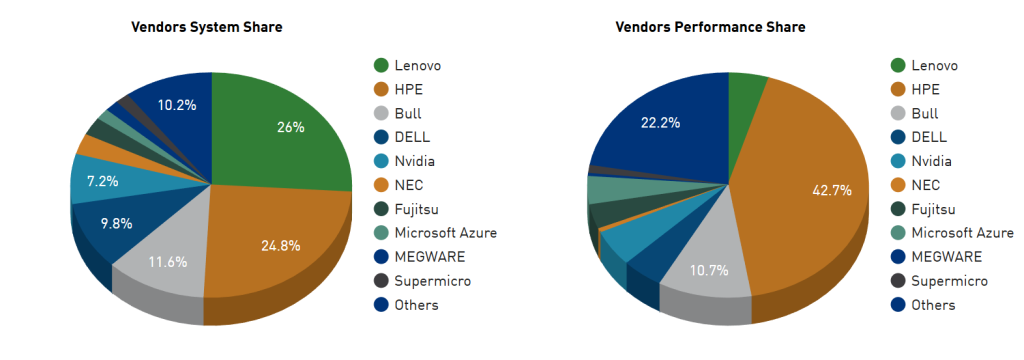
Au-delà de la géopolitique des nations, l’édition redessine aussi le rapport de force entre fondeurs. Et il est tout sauf univoque. Sur le TOP500 pris dans son ensemble, NVIDIA reste l’écrasant maître de la « stack » HPC : ses technologies équipent plus de 400 des 500 systèmes (81 %), avec un record de 238 machines accélérées par ses GPU et de 376 interconnectées par son réseau (majoritairement Quantum InfiniBand). Le fondeur pousse désormais aussi ses propres CPU Grace, présents dans 26 systèmes (+8 en six mois, près de 2,5 millions d’unités livrées), et truste 90 % des nouveaux entrants. En attendant que le CPU « Vera » s’impose à l’avenir sur davantage de systèmes.
D’ailleurs, d’une manière plus générale, les architectures ARM, longtemps marginales dans le HPC, s’imposent comme le fil rouge des designs les plus novateurs et les plus souverains : ARMv9 pour le LX2 de LineShine, A64FX pour Fugaku, Neoverse pour les Grace de NVIDIA comme pour le Rhea1 de SiPearl. ARM n’est plus une curiosité dans l’univers du calcul intensif, c’est devenu le socle commun des ruptures.
En attendant, sur les processeurs des dix premières machines, c’est bien AMD (et l’architecture x86) qui règne. Le fondeur anime directement quatre des dix systèmes du Top 10 (El Capitan, Frontier, ainsi que les italiens HPC7 et HPC6) et pèse plus de 40 % de la performance HPL cumulée du Top 10.
Intel, en revanche, fait désormais pâle figure : sa présence au sommet se résume pour l’essentiel à Aurora (plateforme complète) et aux Xeon de l’Eagle de Microsoft. Une nouvelle preuve de la déconfiture que subit le fondeur depuis quelques années.
Sur le Green500, la hiérarchie se resserre brutalement autour d’un seul nom. NVIDIA y rafle les huit premières places (toutes sur GPU NVIDIA) et neuf des dix premières, les quatre premières revenant à des superchips GH200 Grace Hopper, confirmant que la combinaison CPU + GPU à mémoire partagée reste, à ce jour, le nec plus ultra du rendement énergétique. AMD se contente d’une présence minoritaire dans le Top 10 (deux machines à accélérateurs MI300A.
L’exascale 2026 est devenue un paysage hétérogène, où cohabitent x86, ARM, GPU, APU, interconnexions propriétaires, Slingshot, InfiniBand et architectures nationales.
Et demain ?
Le retour de la Chine en tête du TOP500 n’est donc pas seulement une performance technique. C’est aussi un retour politique. L’entrée directe de LineShine à la première place marque plus qu’une simple mise à jour semestrielle du palmarès. Elle signe la fin d’une longue séquence de discrétion chinoise, entamée et rappelle que le TOP500 n’est pas seulement un classement de puissance brute. C’est aussi un instrument de visibilité technologique, de souveraineté industrielle et de rapport de force entre grandes puissances du calcul.
Mais cette édition de juin 2026 raconte aussi une transformation plus profonde. Le supercalcul ne se juge plus uniquement au nombre de flops. Il se juge désormais à la capacité de concevoir ses propres puces, de maîtriser ses interconnexions, de contenir ses mégawatts, de soutenir l’IA, de rester programmable, et de s’inscrire dans une stratégie nationale ou continentale.
Une nouvelle vérité se dessine : l’exascale n’est plus une ligne d’arrivée. C’est le nouveau point de départ d’une compétition beaucoup plus vaste, où la puissance brute, l’efficacité énergétique, la souveraineté des composants et la capacité à nourrir l’intelligence artificielle deviennent indissociables.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :