


Data / IA
Mistral AI revient dans la course avec Mistral Large 3 et ses Ministral 3
Par Laurent Delattre, publié le 03 décembre 2025
Alors qu’OpenAI, Google et Anthropic ont récemment rappelé leur totale maîtrise des modèles frontières, la startup française Mistral AI, unique espoir européen dans ce domaine, se devait, elle-aussi, de faire un bond significatif pour ne pas se laisser distancer. Elle annonce sa nouvelle famille de modèles Mistral 3 pour redorer le blason des modèles ouverts.
Les leaders américains de l’IA ont, au mois de Novembre, largement démontré leur capacité à relever le « plafond de verre » que l’on croyait contraindre les LLM à stagner. OpenAI a corrigé le tir un peu raté de GPT-5 avec une version GPT-5.1 étonnante d’expressivité et de précision dans un peu tous les domaines. Google a démontré qu’elle n’avait plus aucun retard et dominait à la fois de Deep Research et la génération d’images avec Gemini 3 et Nano Banana Pro. Anthropic leur a répondu avec un Claude 4.5 Opus au sommet notamment en matière de codage.
Meta avec son LLama 4, les chinois DeepSeek et Kimi, et les européens avec Mistral AI n’ont jamais paru aussi loin dans la course à l’IA, un coup dur pour tous ces acteurs clés de l’univers des modèles ouverts.
Il n’aura cependant pas fallu attendre bien longtemps pour voir le grand espoir de l’IA Européenne, Mistral AI réagir. La startup française a annoncé cette semaine la sortie officielle de sa famille de modèles Mistral 3, comportant le modèle Mistral Large 3 et ses petits frères dédiés à l’edge et l’embarqué, les Ministral 3 (3B, 8B, 14B).
Mistral Large 3, massif mais pas hybride
Mistral 3 est une famille de nouveaux modèles multimodaux et multilingues. Elle comprend trois modèles denses Ministral de 3, 8 et 14 milliards de paramètres, ainsi qu’un très grand modèle, Mistral Large 3, basé sur une architecture mixture of experts sparse. L’ensemble est publié sous licence Apache 2.0, ce qui permet un usage commercial et un déploiement sur l’infrastructure des clients, y compris on-premise, sans dépendance forte à un fournisseur de cloud.
Au sommet de la gamme se trouve donc Mistral Large 3, un modèle multimodal généraliste, ouvert par ses poids, qui repose sur une architecture mixture of experts avec environ 41 milliards de paramètres actifs sur un total de 675 milliards. Le modèle accepte texte et images, gère un contexte étendu jusqu’à environ 256 000 jetons et est proposé en version base et en version instruction, variante dédiée au dialogue et à l’assistance.
Mistral revendique des performances au niveau des meilleurs modèles ouverts orientés conversation, avec un accent particulier sur le multilingue. Sur le classement LMArena, Mistral Large 3 arrive en deuxième position parmi les modèles ouverts non centrés sur le raisonnement et se place dans le haut du panier des modèles ouverts toutes catégories.
Techniquement, le modèle a été entraîné sur environ trois mille GPU NVIDIA H200. En aval, l’éditeur a travaillé avec NVIDIA, Red Hat et la communauté vLLM pour optimiser l’inférence sur les piles TensorRT LLM et SGLang, ainsi que sur les futures générations de matériel Blackwell et les configurations Blackwell NVL.
Mistral Large 3 ne reste pas un modèle de laboratoire. Il est pensé pour être déployé dans des environnements de production variés, y compris sur des infrastructures GPU mutualisées, avec des formats de poids compressés qui réduisent l’empreinte mémoire et les coûts d’inférence. Sur son blog, l’entreprise explique que l’avenir de l’IA doit reposer sur la transparence, l’accessibilité et un progrès collectif et invite la communauté à construire sur ces modèles plutôt qu’à les consommer uniquement via des services fermés.
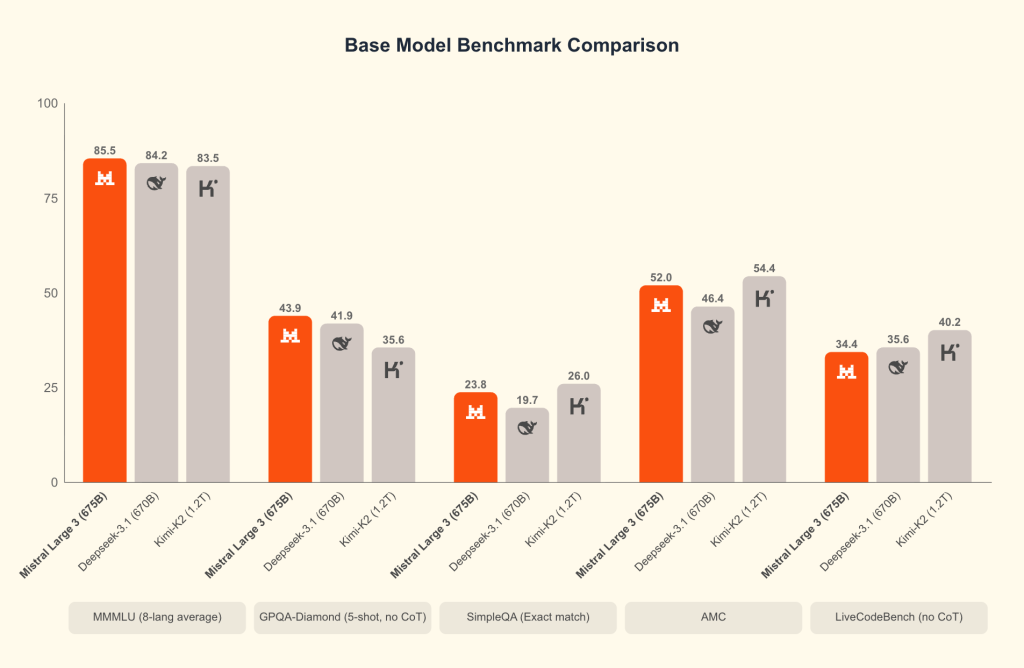
Reste que le modèle illustre malheureusement, aussi, l’ampleur du fossé qui sépare la recherche européenne de celle des startups américaines. D’une part, leurs modèles sont entraînés sur des dizaines voire des centaines de milliers de GPU, pas simplement des milliers. D’autre part, ce qui fait la force spectaculaire des derniers modèles d’OpenAI, Google et Anthropic, ce n’est pas tant la taille des modèles que leur conception hybride avec des capacités de raisonnement très avancées totalement intégrées. Or Mistral Large 3, contrairement au modèle Magistral du même Mistral AI, continue d’être un modèle classique sans raisonnement avancé qui se compare avantageusement à DeepSeek v3.1 ou un Kimi K2 mais ne s’aventure surtout pas à se comparer aux leaders américains.

Bien sûr, Mistral Large 3 sait raisonner et fait du bon boulot sur les usages classiques d’entreprise (chat, analyse de documents, multimodal, etc.). Mais il n’est pas un « flagship reasoning model » ce qui limite fortement ses capacités en mathématiques, en matière de codage ou sur les usages STEM. Or sortir un modèle sans raisonnement avancé intégré a aujourd’hui un côté quelque peu anachronique. Mistral le sait, puisque l’éditeur précise bien qu’une version « reasonning » de Large 3 est bien prévue mais pas encore disponible. Mais son approche reste néanmoins moins « hybride » qu’Anthropic ou Google, et c’est peut-être inquiétant.
Ministral 3, l’arme de Mistral pour l’edge et le local
À l’opposé d’un modèle frontière comme Mistral Large 3, Mistral pousse aussi la famille Ministral 3, trois modèles denses de 3, 8 et 14 milliards de paramètres, chacun décliné en versions base, instruct et même « reasoning », tous multimodaux et tous sous licence Apache 2.0.
Ces modèles sont explicitement pensés pour l’edge et les déploiements locaux. Les variantes de 3 et 8 milliards de paramètres peuvent tourner sur un unique GPU récent de type H200 et les quantifications proposées par l’écosystème, comme celles d’Ollama, visent des exécutions sur des postes de travail haut de gamme ou des serveurs modestes.
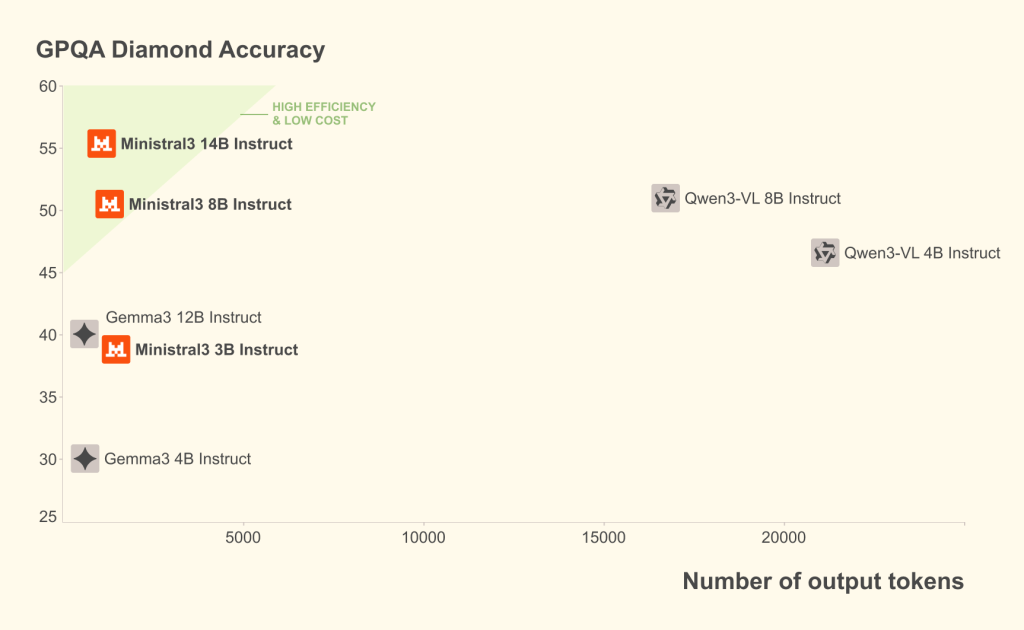
Mistral AI insiste sur le rapport performance/coût de la gamme Ministral. Les modèles d’instruction sont présentés comme capables d’égaler ou dépasser les modèles concurrents de taille comparable, tout en générant souvent beaucoup moins de jetons pour une même tâche, ce qui réduit mécaniquement la facture d’inférence. Les variantes reasoning, elles, privilégient la qualité des réponses sur des tâches de raisonnement, quitte à calculer plus longtemps, avec par exemple un score revendiqué d’environ 85 pour cent sur l’épreuve AIME pour le modèle de quatorze milliards de paramètres. Les variantes Reasoning sont conçues pour des cas où la justesse compte plus que la latence ; elles consomment volontairement plus de tokens pour réfléchir plus longtemps et améliorer la qualité des réponses. Les variantes « Reasoning » s’appuient sur les mêmes architectures de base que les Ministral 3 « normaux » mais avec un post-entraînement ciblé sur le raisonnement, et un profil d’inférence qui accepte d’être plus bavard et plus lent pour gagner en précision sur des problèmes difficiles.

Les modèles Ministral peuvent être intégrés directement dans des applications embarquées, des systèmes industriels ou des outils métiers internes, sans dépendre d’un appel à une API distante. Cette approche limite l’exposition des données sensibles, tout en laissant ouverte la possibilité de basculer sur Mistral Large 3 pour des scénarios plus exigeants, par exemple une plateforme de support client multilingue ou une fabrique documentaire à grande échelle.
La personnalisation est une force
L’ensemble de la famille Mistral 3, des petits modèles Ministral à Mistral Large 3, est publié sous licence Apache 2.0. Cette licence autorise un usage commercial, l’intégration dans des produits propriétaires et la modification, avec des obligations limitées. Elle réduit le risque lié aux clauses ambiguës que l’on retrouve parfois dans d’autres modèles de la galaxie open source.
Reste que les modèles Mistral AI ne sont pas des modèles open source selon la définition OSI mais des modèles « open weight ». Mistral publie les poids des modèles mais pas l’ensemble des données d’entraînement ni tout le code d’infrastructure utilisé, ce qui alimente un débat récurrent en Europe sur la différence entre modèle open source et modèle à poids ouverts. La stratégie open-weight offre aux entreprises une certaine maîtrise opérationnelle sans leur donner une visibilité complète sur les biais potentiels des données de base.
Pour atténuer ce point, Mistral met en avant son offre de services de personnalisation et de fine tuning. C’est normalement la force des petits modèles comme les Ministral mais c’est aussi ici le cas pour Mistral Large 3. Les entreprises peuvent relativement aisément adapter les modèles à leurs propres corpus ou domaines. Et cela change évidemment tout en matière de lutte contre les hallucinations et de pertinence générale des réponses dans le contexte de votre entreprise. Autrement dit, avec Mistral 3, la personnalisation n’est pas un add-on mais un principe de conception, et c’est ce qui rend le sujet du fine tuning particulièrement stratégique pour les équipes IT.
Les variantes Mistral 3 peuvent déjà être fortement “pilotées” sans aucun entraînement supplémentaire. La documentation officielle consacre un guide complet à la personnalisation par system prompt, réglage des objectifs, définition des valeurs, politiques de modération et format de sortie voulu. L’idée est de façonner le comportement du modèle par le texte et les paramètres plutôt que par un nouveau training, ce que Mistral appelle le pilotage du modèle par “application behavior”.
Mistral Large 3 est expressément conçu pour bien respecter ce type de pilotage, avec une forte sensibilité au system prompt et des capacités avancées de function calling et de sorties structurées. C’est déjà une forme de personnalisation fine sans toucher aux poids des modèles. Pour de nombreux cas d’usage métier, Mistral oriente d’ailleurs d’abord vers cette approche, complétée par du RAG pour injecter la connaissance métier à la volée plutôt que la graver dans les poids.
Pour aller plus loin Mistral propose via sa Plateforme et via son AI Studio un véritable « fine-tuning » clé en main, en texte et vision, pour apprendre au modèle à suivre des consignes métier, adopter un ton spécifique ou maîtriser un domaine vertical.
Et pour aller encore plus loin, Mistral propose un SDK open source de fine-tuning de ses modèles. « mistral-finetune », basé sur LoRA, permet en quelque sorte de réentraîner efficacement ses modèles sur un ou plusieurs GPU, avec des jeux de données au format JSONL et une prise en charge de scenarii instruct et function calling.
Mistral propose même d’accompagner les entreprises en matière de gouvernance et de conformité pour toutes les organisations en quête de modèles personnalisés dans des environnements régulés ou en appui sur des données très sensibles.
Une vraie alternative européenne
Avec Mistral 3, la start-up parisienne se positionne encore un peu plus frontalement en alternative européenne aux offres fermées de Google, OpenAI et Anthropic ainsi qu’aux offres ouvertes de Meta et des startups chinoises. On peut tourner les choses dans tous les sens, saluer les efforts de LightOn sur les SLM, Owkin et Bioptimus dans le biomédical ou les recherches de Kuytai (et sa spin-off Gradium) sur l’IA vocale, apprécier les innovations agentiques de Dust ou H Company, aux yeux du monde Mistral reste la seule vraie force européenne en matière d’IA générative. Et l’un des leaders mondiaux incontournables des modèles ouverts sur lesquels s’appuient bien des startups et centres de recherche en IA.
Mistral ne se démarque pas que par sa stratégie fortement orientée vers l’ouverture des poids, que l’entreprise présente comme un contrepoint à la tendance des grands acteurs américains à verrouiller leurs modèles derrière des offres purement SaaS. Elle se démarque aussi, et peut-être même surtout, par son éthique européenne. Ses IA sont entraînées et alignées sur des corpus de données alignés sur les valeurs européennes, l’histoire européenne, les langues européennes. Alors que les leaders américains sont influencés par la politique de Donald Trump et que les IA chinoises souffrent d’importants biais et filtrages imposées par le gouvernement Chinois, Mistral s’impose en défenseur d’une IA ouverte, indépendante des agendas politiques des grandes puissances et respectueuse des libertés publiques.
Les premiers retours et benchmarks confirment que Mistral Large 3 vient se placer parmi les meilleurs modèles ouverts pour des tâches généralistes, notamment sur des conversations non anglophones, mais reste néanmoins en retrait des modèles fermés vedettes des géants de l’IA qui continuent de dominer le haut du classement.
Les DSI, eux, regarderont moins les quelques points d’écart sur les benchmarks que la combinaison de trois critères. La qualité moyenne des réponses sur leurs langues et usages. Le coût global d’inférence, en particulier pour les volumes importants. Et le degré de contrôle réel sur l’architecture et la chaîne de déploiement. Sur ce terrain, la coexistence entre Mistral Large 3 dans le cloud et les modèles Ministral sur l’edge ou on premise donne à Mistral un argument différenciant face à des offres plus monolithiques.
Dans l’immédiat, la nouvelle famille Mistral 3 est accessible via Mistral AI Studio, mais aussi via des plateformes comme Amazon Bedrock, Azure, IBM WatsonX, Hugging Face ou encore des fournisseurs spécialisés comme Modal, Fireworks, Together ou OpenRouter. Une universalité qui facilite les expérimentations multi cloud et limite les dépendances à un seul acteur.
Au final, ce lancement est aussi une invitation à réévaluer la cartographie des modèles utilisés en interne dans votre entreprise. La famille Mistral 3 mérite qu’on lui accorde toute son attention et qu’on expérimente ses différents modèles sur les cas d’usage concrets de l’entreprise. Dans un moment où chaque DSI doit arbitrer entre performance, coûts et souveraineté, les ignorer reviendrait à se priver volontairement d’un atout de compétitivité et d’autonomie.
À LIRE AUSSI :










