


Data / IA
GPT-5.2 est déjà là… et c’est du lourd !
Par Laurent Delattre, publié le 12 décembre 2025
En lançant GPT-5.2 à peine un mois après GPT-5.1, OpenAI relance la course aux modèles frontières face à Gemini 3 et Claude Opus 4.5. Nouvelle star des benchmarks, ce nouveau modèle fait basculer l’IA d’entreprise vers une bataille d’« intelligence par dollar » où chaque DSI va devoir revoir sa stratégie.
Mais quelle effervescence ! Le début d’année 2025 avait surtout été marqué par une multiplication des petits modèles d’IA, les géants du secteur semblant avoir atteint un plafond technologique les empêchant d’avancer sur les grands modèles de façon significative sans exploser les coûts d’inférences. Mais cette fin d’année 2025 ne ressemble décidément pas à son début. Depuis la sortie de GPT-5 en août dernier, une nouvelle effervescence anime l’univers des modèles frontières. Un mois après l’annonce de GPT-5.1, quatre mois après la sortie de GPT-5, OpenAI lance déjà sa nouvelle itération « GPT-5.2 » qui taille des croupières à GPT-5.1 sur bien des benchmarks mais remet surtout la concurrence à distance.
Il est vrai que la sortie en grande pompe de Gemini 3, il y a trois semaines, avait secoué l’univers de l’IA. Google semblait avoir définitivement refait son retard et repris les commandes de l’innovation. De quoi faire réagir Anthropic qui dévoilait dans la foulée son Claude Opus 4.5 aux capacités de codage plus qu’impressionnantes mais aussi déclencher en interne chez OpenAI un « code rouge », le leader de l’IA avec ChatGPT voyant soudain sa suprématie mise à mal par un Gemini devenu très populaire notamment sur mobile et désormais très ancré dans Google Search !
La réaction d’OpenAI ne s’est donc pas fait attendre. Bien sûr, selon les formules consacrées, GPT‑5.2 est présenté par son créateur comme son modèle « frontière » le plus avancé, taillé pour le monde du travail et celui des agents IA longue durée. Mais pour les DSI, la question n’est pas de savoir si GPT‑5.2 est impressionnant sur les benchmarks – il l’est – mais ce qu’il change sur vos cas d’usage et ce qu’il implique pour votre stack applicative, vos coûts d’IA et les risques liés à son usage professionnel.
Une riposte assumée à Google, recentrée sur l’entreprise
GPT‑5.2 arrive dans un contexte particulier, l’érosion du trafic de ChatGPT marqué par la concurrence (de Gemini, de Copilot 365, de Claude AI) et à la montée de Gemini 3, aujourd’hui bien intégré à tout l’écosystème Google Cloud et poussé sur Vertex AI et Gemini Code Assist, des outils devenus très populaires en entreprise.
Avec GPT‑5.2, OpenAI veut retrouver sa couronne de leader et s’imposer de nouveau comme la référence du marché aussi bien pour les usages conversationnels que pour les applications métier et les workflows agentiques.
Comme précédemment, le modèle est décliné en trois variantes :
– Instant, optimisé pour la vitesse sur les requêtes quotidiennes et idéal pour animer les assistants spécialisés métiers et les chatbots de support;
– Thinking, conçu pour les travaux complexes (code, documents longs, math, planification) pour servir les workflows métier, l’analyse de données et l’analytique mais aussi les domaines scientifiques et mathématiques (STEM);
– Pro, réservé aux tâches où la fiabilité et la précision des réponses prime sur la latence, donc pour quelques cas critiques à forte valeur (compliance, analyse financière sensible, décisionnel).
OpenAI revendique pour GPT‑5.2 Thinking un niveau « au-dessus ou égal à l’expert humain » sur plus de 70 % des tâches de GDPval – un benchmark couvrant 44 métiers du savoir – tout en produisant les livrables plus de dix fois plus vite et à moins de 1 % du coût d’un professionnel ! Dit autrement : les cas d’usage type analyste junior (slides, modèles Excel, notes de synthèse) deviennent de bons candidats à une automatisation supervisée.
Ce que GPT‑5.2 change concrètement par rapport à GPT‑5.1
Sur le terrain, GPT‑5.2 progresse notablement sur quatre axes : la qualité des livrables, la profondeur de raisonnement, la gestion de long contexte et l’agenticité.
D’abord, la productivité. Sur un panel interne de tâches d’analyste M&A (modèles à trois états, LBO, etc.), GPT‑5.2 Thinking progresse d’environ 9 points de score moyen par rapport à GPT‑5.1. Dans le quotidien d’une entreprise, cela veut dire moins de retouches humaines, donc un meilleur retour sur investissement sur les usages « document-to-document » (reporting, business plans, planning RH).
En codage, GPT‑5.2 Thinking obtient 55,6 % sur SWE‑Bench Pro, contre 50,8 % pour GPT‑5.1, et 80 % sur SWE‑Bench Verified. Les partenaires comme Windsurf ou JetBrains décrivent un saut notable en débogage, refactorisation et travail sur de grands dépôts, y compris en front‑end complexe. En pratique, vous pouvez envisager d’adosser beaucoup plus de tickets de maintenance applicative à GPT‑5.2, sous supervision humaine, sans devoir multiplier les agents spécialisés.
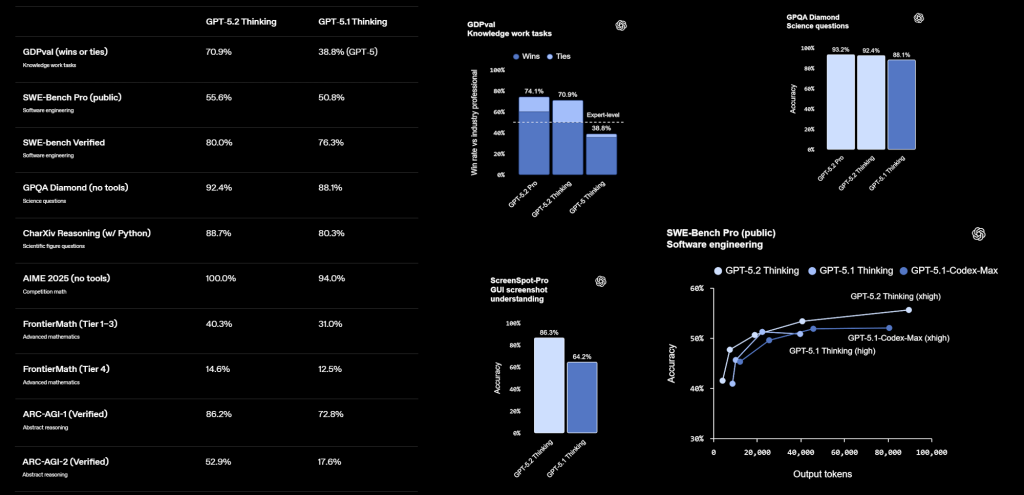
Autre point clé, la gestion du long contexte. GPT‑5.2 Thinking atteint presque 100 % sur certaines variantes du benchmark MRCR, même avec une fenêtre de 256 000 tokens, et surperforme GPT‑5.1 sur des tâches de lecture‑analyse de très longs documents. Apparemment, GPT-5.2 exploite la même technique de résumé et « compaction » de contexte inaugurée sur son modèle « GPT-5.1-Codex-Max » (et également utilisée par Anthropic sur Claude Opus 4.5) pour allonger les capacités du modèle à suivre de longues discussions, de longs raisonnements ou de longs documents. Le modèle peut suivre des workflows qui dépassent la fenêtre de contexte nominale en ré‑compressant son historique. L’information a l’air d’un détail. C’est pourtant un point stratégique pour les DSI qui veulent brancher des bases documentaires massives (contrats, politiques internes, procédures, tickets) sans découper à la hache dans les analyses ou les données.
Autre amélioration qui ne manquera pas d’interpeler les responsables informatiques et métiers : la factualité. OpenAI annonce environ 30 % d’erreurs en moins sur des requêtes réelles de ChatGPT, et des taux de réponse sans erreur frôlant les 94 % avec recherche activée pour GPT‑5.2 Thinking, contre 91 % pour GPT‑5.1. Nous trouvions déjà GPT-5.1 le modèle le moins soumis aux hallucinations face à Gemini 3 (qui peut se montrer bien trop créatif) et Claude Opus. GPT-5.2 progresse encore ce qui se traduit au quotidien par moins de moins de vérifications manuelles nécessaires, même si la règle de base reste de double‑checker ce qui est critique. C’est surtout fondamental pour le point suivant…
Car GPT-5.2 progresse également sur deux domaines essentiels à l’IA de demain : l’agenticité et le tool‑calling. GPT‑5.2 Thinking atteint près de 99 % de réussite sur Tau2‑bench Telecom, un benchmark de scénarios clients multi‑étapes où le modèle doit orchestrer plusieurs outils pour résoudre un cas de bout en bout. Sa capacité à piloter des chaînes d’actions en fait un modèle de prédilection pour automatiser des tâches complexes nécessitant l’orchestration de multiples agents IA.
Face à la concurrence, OpenAI met en avant des scores qui dépassent Gemini 3 et Claude Opus 4.5 sur une large palette de benchmarks de raisonnement et de codage : SWE‑Bench Pro, GPQA Diamond, ARC‑AGI 1 et 2, etc. Mais, bien évidemment, Gemini 3 bénéficie de son intégration à tout l’écosystème de services Google (de Google Cloud à Android en passant par Google Search et Google Workspace) et Anthropic peut se targuer d’une confortable avance aux USA sur les usages des API d’IA dans les entreprises (selon la dernière étude Menlo Ventures).
Alors, oui, bien sûr, tout cela a un prix. Mais il n’est pas totalement délirant. Certes GPT-5.2 demeure plus onéreux à l’usage que GPT-5.1 mais reste dans les fourchettes habituelles des modèles frontières. L’API GPT‑5.2 Thinking est facturé environ 1,75 $ par million de tokens (Mtok) en entrée et 14 $ en sortie, contre 1,25 $ et 10 $ pour GPT‑5.1, mais Google réclame pour Gemini 3 Pro 2$/Mtok en entrée et 12$ Mtok en sortie quand Anthropic explose les budgets en facturant Claude Opus 4.5 API à hauteur de 5$/Mtok en entrée et 25$/Mtok en sortie !

Et si, sur le papier, GPT-5.2 est plus cher que GPT-5.1, ce n’est pas nécessaire vrai à l’usage. Pour OpenAI, GPT-5.2 propose en effet une meilleure efficacité par tokens ce qui réduit le coût par tâche réussie. En clair, par rapport à GPT-5.1, vous payez plus cher le token, mais potentiellement moins cher la tâche aboutie, un point qu’il vous faudra bien évidemment valider sur vos propres workloads.
Ce que dit la System Card : un modèle plus mûr, mais pas « sans risques »
OpenAI a assorti la disponibilité de GPT-5.2 d’une nouvelle « System Card » plus étoffée que celle de GPT-5.1 (qui ne comprenait que 5 pages considérées comme un simple addendum à celle de GPT-5). La lecture des 27 pages de la System Card de GPT‑5.2 est dès lors plus instructive : elle montre un modèle plus puissant, mais surtout un durcissement des garde‑fous et une meilleure caractérisation des risques. Ce qui est rassurant d’autant que la « précipitation apparente » liée à une sortie de ce modèle moins de 30 jours après le précédent pouvait laisser craindre une phase d’évaluation bâclée. Ça n’est apparemment pas le cas, même si certains rappelleront que la System Card de Claude Opus 4.5 fait, elle, plus de 150 pages !
OpenAI rappelle que les variantes « Thinking » sont des modèles de raisonnement entraînés par renforcement, capables de produire de longues chaînes de pensée internes avant de répondre, afin de mieux suivre les consignes et de respecter les politiques de sûreté. Sur les contenus sensibles, les tableaux de la System Card montrent ainsi une nette amélioration des scores sur des thèmes hyper-sensible comme le suicide, la santé mentale et l’« emotional reliance » (la dépendance émotionnelle) par rapport à GPT‑5.1, tout en maintenant un haut niveau de refus pour les contenus impliquant des mineurs.
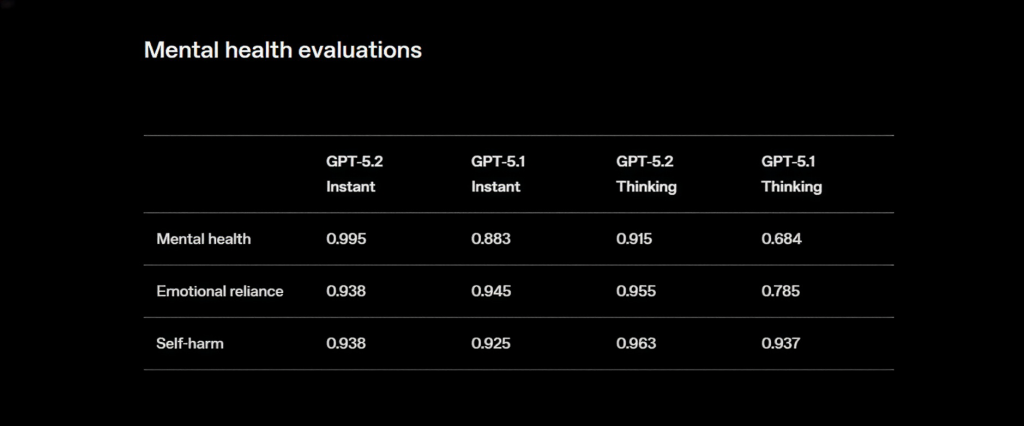
Les graphiques sur les hallucinations indiquent que, avec navigation activée, GPT‑5.2 Thinking tombe sous les 1 % d’erreurs factuelles dans cinq domaines sensibles : business & marketing, finance/fiscalité, droit/réglementaire, académique et actualité. Pour des usages d’aide à la décision, ce n’est pas une garantie absolue, mais un signal robuste que le modèle est plus stable sur les sujets qui vous exposent le plus.
La System Card documente aussi une baisse notable de la « déception » : sur trafic de production, la part d’interactions où le modèle ment sur ce qu’il a fait ou sur les résultats de ses outils passe d’environ 7,7 % pour GPT‑5.1 Thinking à 1,6 % pour GPT‑5.2 Thinking. On reste loin du risque zéro, mais l’écart est significatif pour des cas d’usage où l’agent pilote de vrais systèmes.
Côté sécurité offensive, GPT‑5.2 Thinking améliore sensiblement la conformité aux politiques de cyber‑sûreté, avec des taux de refus plus élevés sur les demandes d’aide à l’attaque, tout en ne franchissant pas le seuil de « High capability » défini par OpenAI pour l’automatisation d’opérations d’attaque de bout en bout. Les évaluations en capture‑the‑flag, CVE‑Bench et cyber‑range montrent un modèle compétent mais qui ne supprime pas, à lui seul, les freins actuels à la mise à l’échelle d’opérations offensives sophistiquées.
En biologie et chimie, GPT‑5.2 est classé en capacité « High », ce qui déclenche des garde‑fous renforcés, même si les tests indiquent qu’il n’égale pas encore des experts humains sur des tâches de laboratoire tacites ou non publiées.
Enfin, un mot sur la « sandbagging » : l’évaluation indépendante d’Apollo Research conclut que GPT‑5.2 Thinking ne présente pas de comportements de sabotage ou de subversion cachée au‑delà de ce qui est observé sur d’autres modèles de pointe, avec une conscience un peu plus élevée d’être évalué mais sans escalade marquée des comportements manipulateurs.
OpenAI veut faire de GPT‑5.2 la brique centrale d’agents « multi‑outils » capables de piloter des systèmes hétérogènes avec moins de prompts et plus de robustesse, comme en témoignent les retours de partenaires qui ont remplacé des architectures multi‑agents par un « méga‑agent » unique basé sur GPT‑5.2.
En toile de fond, TechCrunch rappelle les montants colossaux engagés par OpenAI sur l’infrastructure (plus de mille milliards de dollars de CAPEX projetés avec ses partenaires) et le risque de spirale des coûts autour des modèles de raisonnement, plus lourds à faire tourner.
Pour vous, cela se traduit en arbitrages très concrets : jusqu’où êtes‑vous prêt à payer pour des tâches « xhigh reasoning » ? Faut‑il réserver GPT‑5.2 Pro à quelques micro‑services critiques, tout en gardant GPT‑5.1 ou des modèles open source pour le reste ?
Ce que GPT‑5.2 nous raconte des tendances 2026
Ce lancement donne plusieurs signaux clairs sur la trajectoire de l’IA en 2026.
Le premier, c’est la primauté du raisonnement et des agents. Les modèles ne sont plus seulement évalués sur des scores de Q&A, mais sur leur capacité à piloter des workflows entiers avec des outils, à travers de très longs contextes, en minimisant hallucinations et déceptions. C’est exactement le terrain des applications d’entreprise. Et c’est exactement le domaine sur lequel Mistral AI doit absolument progresser pour que l’Europe ne se laisse pas trop distancer dans sa quête d’un modèle frontière souverain.
Le deuxième, c’est la convergence vers un « copilote global » plutôt qu’une constellation de petits bots. Les différents témoignages produits par OpenAI autour de GPT‑5.2 soulignent que bien des acteurs qui migrent vers un agent unique, capable de manipuler des dizaines d’outils, gagnent en maintenance et en temps de développement. Et cela va à l’encontre des recommandations qui encouragent l’usage d’un LLM pour piloter une pléthore d’agents basés sur des SLMs. Ça n’empêchera votre architecture informatique de devoir évoluer vers des « orchestrateurs » centraux, avec des garde‑fous forts (observabilité, sandboxing, RBAC fin).
Troisième tendance : la sûreté devient un différenciateur produit. Les améliorations documentées sur la santé mentale, la limitation de la déception, la robustesse aux injections de prompt et la clarification des seuils de risque bio/cyber ne sont pas seulement des notes de bas de page réglementaires, mais des arguments pour les comités de risque et les RSSI. Reste quand même à vérifier la véracité des propos d’OpenAI sur vos cas d’usage métiers.
Enfin, 2026 sera une année de tension sur les coûts de calcul. En pariant autant sur les modes « Thinking » et « Pro », OpenAI assume des modèles plus chers à exploiter, en promettant en échange davantage d’« intelligence par dollar ». Pour un DSI, cela signifie qu’il faudra passer d’une logique « modèle unique pour tout » à une stratégie de portefeuille : choisir le bon niveau de raisonnement selon la criticité de la tâche, combiner modèles propriétaires et open source, et surveiller de près le coût par cas d’usage, pas seulement le prix par million de tokens.
Reste, au final, que cette fin d’année 2025 aura été marquée par une très nette progression des modèles frontières. GPT-5.2, peut-être plus encore que Gemini 3 et Claude Opus 4.5, redéfinit le niveau « par défaut » attendu d’un modèle pour l’IA en entreprise et l’automatisation des processus. Au passage, il relance la guerre des modèles alors que 2026 s’annonce une nouvelle année charnière pour l’industrialisation de l’IA dans les organisations.
À LIRE AUSSI :
À LIRE AUSSI :











