


Data / IA
GPT-5.5 : OpenAI revient dans la course, mais la guerre des modèles reste ouverte
Par Laurent Delattre, publié le 24 avril 2026
Distancé ces derniers mois par Claude Opus 4.6 puis Opus 4.7 sur le terrain des agents, du code et du travail long, OpenAI réplique avec GPT-5.5. Le modèle ne se contente pas d’ajouter des points de benchmark : il redessine l’architecture même de l’IA d’entreprise, entre raisonnement, usage d’outils, sécurité cyber et coût d’exécution. Au final, OpenAI livre un nouveau modèle frontière bien plus conçu pour les tâches agentiques que pour le conversationnel…
Il y avait urgence. Depuis le lancement de Claude Opus 4.5, Anthropic est devenu la nouvelle référence de l’IA en entreprise. Et la jeune pousse n’a cessé depuis de remettre la pression sur OpenAI avec Opus 4.6, Opus 4.7 et le très médiatisé mais inaccessible « Claude Myhtos Preview« . Anthropic a imposé un nouveau tempo sur les tâches longues, le développement logiciel, le raisonnement sur grands contextes et l’usage autonome d’outils.
OpenAI a tenté de répondre en sortant GPT-5.3 puis GPT-5.4 (et GPT-5.4-Cyber) sans vraiment arriver à reprendre significativement la main, ne serait-ce que sur les benchmarks.
Mais ce GPT-5.5 annoncé cette nuit marque une nouvelle étape. Le modèle frontière, décliné en version Thinking et Pro, n’est pas une simple mise à jour incrémentale, mais une importante refonte interne, intégralement réentraînée, dotée d’améliorations majeures afin de reprendre significative l’initiative sur les benchmarks mais plus encore sur ce qui compte désormais pour les DSI : la capacité d’un modèle à mener un processus complet, à traverser plusieurs outils, à vérifier son travail, à réduire les relances humaines et à rester exploitable à grande échelle.
« Nous lançons GPT-5.5, notre modèle le plus intelligent et le plus intuitif à utiliser à ce jour, et la prochaine étape vers une nouvelle façon d’accomplir du travail sur ordinateur. » affirme OpenAI en introduction.
Les séries GPT-5.x avaient corrigé beaucoup de choses… sans tout résoudre
Il serait injuste de réduire la famille GPT-5 à ses faiblesses. GPT-5.4 avait déjà marqué un vrai progrès. OpenAI le présentait comme son premier modèle généraliste doté de capacités natives d’usage de l’ordinateur, avec une fenêtre de contexte allant jusqu’à 1 million de jetons, une meilleure recherche d’outils et une efficacité en jetons supérieure à GPT-5.2.
Pour les DSI, GPT-5.4 avait surtout déplacé le modèle hors de la simple conversation. Il savait mieux produire des documents, manipuler des feuilles de calcul, générer des présentations, parcourir des interfaces, lire des captures d’écran et exécuter des tâches dans des environnements logiciels. De quoi permettre à l’outil agentique Codex d’OpenAI de revenir à niveau de Claude Code et de conquérir plus de 4 millions d’utilisateurs actifs en quelques semaines.
Mais la série GPT-5.x restait inégale. GPT-5.4 améliorait nettement la factualité par rapport à GPT-5.2, avec des affirmations individuelles 33 % moins susceptibles d’être fausses et des réponses complètes 18 % moins susceptibles de contenir une erreur. Mais sa System Card signalait aussi des zones moins nettes : performances santé légèrement en retrait sur HealthBench, régression légère sur certaines attaques par injection de consignes dans des cellules de fonctions, contrôlabilité faible de la chaîne de raisonnement, et nécessité de mesures spécifiques pour les capacités cyber classées « High ».
Autrement dit, GPT-5.4 avait remis OpenAI au niveau sur l’usage de l’ordinateur et le travail documentaire. Mais Anthropic restait très fort sur la perception de fiabilité, la profondeur de raisonnement, l’autonomie longue et la qualité des comportements agentiques. GPT-5.5 vise précisément à effacer cette faille.
GPT-5.5 est conçu pour les tâches qui durent
Le message central d’OpenAI est clair : GPT-5.5 doit être jugé moins comme un moteur de réponse conversationnel que comme un moteur d’exécution agentique. La promesse n’est pas seulement de mieux répondre, mais de mieux comprendre l’intention, de planifier, d’utiliser des outils, de vérifier les résultats, de continuer malgré l’ambiguïté et de produire un livrable complet.
« Au lieu de devoir gérer soigneusement chaque étape, vous pouvez confier à GPT-5.5 une tâche désordonnée, composée de plusieurs parties, et lui faire confiance pour planifier, utiliser des outils, vérifier son travail, naviguer dans l’ambiguïté et continuer » affirme OpenAI.
Et cette évolution devrait particulièrement intéresser les DSI et les équipes IT. Les projets d’IA en entreprise ne butent plus seulement sur la qualité des réponses. Ils butent surtout sur la continuité d’exécution. Un agent utile doit maintenir le contexte d’un processus, distinguer les données pertinentes du bruit, interagir avec des outils métiers, éviter les actions destructrices, demander confirmation au bon moment et produire un résultat contrôlable.
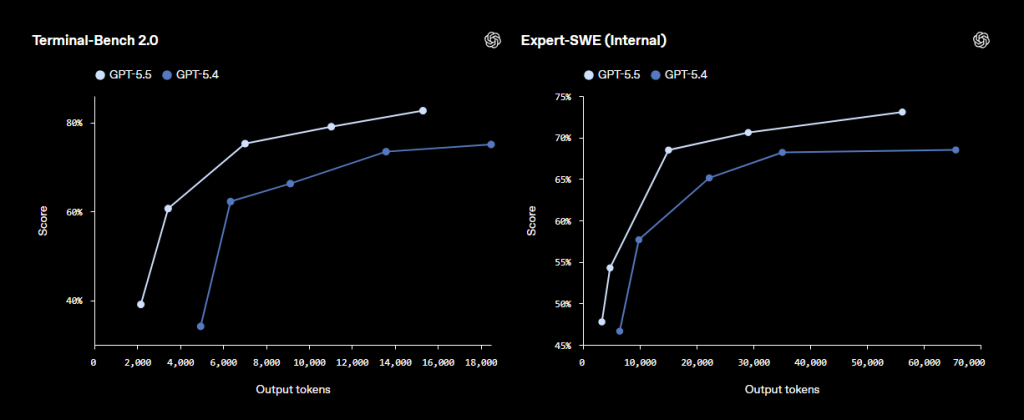
OpenAI affirme que GPT-5.5 progresse fortement dans tous ces domaines et plus particulièrement dans le codage agentique, l’usage de l’ordinateur, le travail de connaissance et les premiers usages scientifiques. L’éditeur met aussi en avant un point décisif : GPT-5.5 conserverait une latence par jeton comparable à GPT-5.4 en production réelle, tout en offrant un niveau d’intelligence supérieur et en consommant moins de jetons sur certaines tâches Codex.
Une conception pensée comme un système complet
GPT 5.5 est d’autant plus intéressant qu’OpenAI a repensé l’architecture d’exploitation de son modèle. L’éditeur explique que servir GPT-5.5 à la latence de GPT-5.4 a nécessité de repenser l’inférence comme un système intégré, et non comme une addition d’optimisations isolées. GPT-5.5 a été co-conçu, entraîné et servi sur des systèmes NVIDIA GB200 et GB300 NVL72. Le détail est plus stratégique qu’il n’y parait. Les modèles frontières ne sont plus seulement des artefacts logiciels. Ils deviennent des systèmes industriels où le modèle, l’infrastructure, l’ordonnancement des requêtes, l’équilibrage de charge, la mémoire, les accélérateurs et les politiques de sécurité sont conçus ensemble.
Ainsi OpenAI affirme même que GPT-5.5 a contribué à améliorer l’infrastructure qui le sert. L’exemple donné est parlant : Codex aurait analysé des semaines de trafic de production pour écrire des heuristiques d’équilibrage et de partitionnement plus adaptées aux formes réelles des requêtes, avec un impact de plus de 20 % sur la vitesse de génération des jetons.
Des gains de benchmarks réels, mais pas uniformes
Sur les évaluations publiées par OpenAI, GPT-5.5 progresse presque partout face à GPT-5.4 mais aussi face à la concurrence. Avec des gains parfois très significatifs.
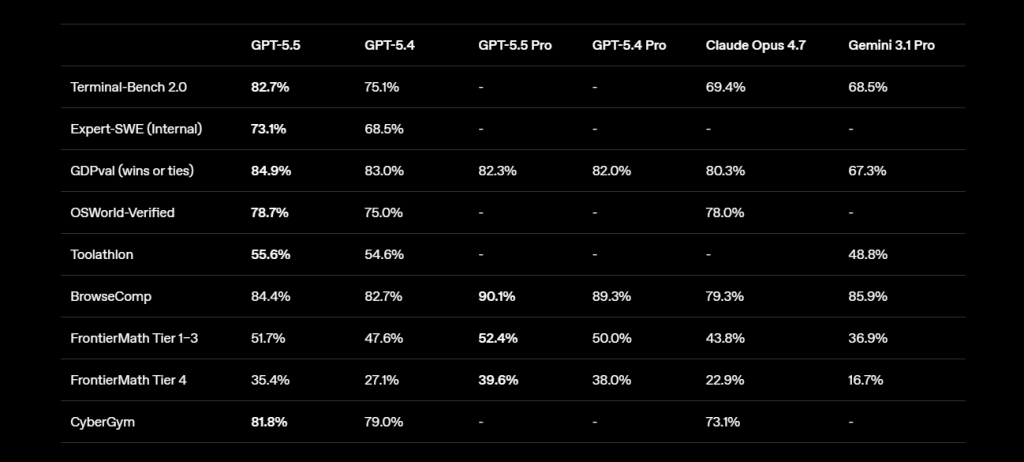
En codage, il atteint 82,7 % sur Terminal-Bench 2.0 contre 75,1 % pour GPT-5.4, et 58,6 % sur SWE-Bench Pro contre 57,7 %. Mais Claude Opus 4.7 reste devant sur SWE-Bench Pro avec 64,3 %, ce qui relativise le récit d’un retour total d’OpenAI au sommet du code. Aux entreprises de se faire une idée plus concrète sur leurs usages réels.
Sur le travail professionnel, GPT-5.5 marque davantage son territoire. Il atteint 84,9 % sur GDPval contre 83 % pour GPT-5.4, 80,3 % pour Claude Opus 4.7 et 67,3 % pour Gemini 3.1 Pro. Il progresse aussi sur FinanceAgent, les tâches internes de modélisation bancaire et OfficeQA Pro.
Sur l’usage de l’ordinateur (le fameux Computer Use très agentique), GPT-5.5 atteint 78,7 % sur OSWorld-Verified, contre 75 % pour GPT-5.4 et 78 % pour Claude Opus 4.7.
Sur la bonne exploitation des outils, le tableau est plus contrasté : GPT-5.5 domine BrowseComp face à Claude Opus 4.7, mais reste derrière ce dernier sur MCP Atlas. Sur Tau2-bench Telecom, OpenAI revendique 98 % sans ajustement de prompt, contre 92,8 % pour GPT-5.4.
Les signaux académiques sont également favorables. GPT-5.5 progresse sur FrontierMath, GeneBench, BixBench, ARC-AGI-2 et CyberGym. Mais là encore, la guerre n’est pas tranchée : Claude Opus 4.7 reste devant sur Humanity’s Last Exam sans outils, tandis que GPT-5.5 Pro reprend l’avantage sur certains tests mathématiques et scientifiques.
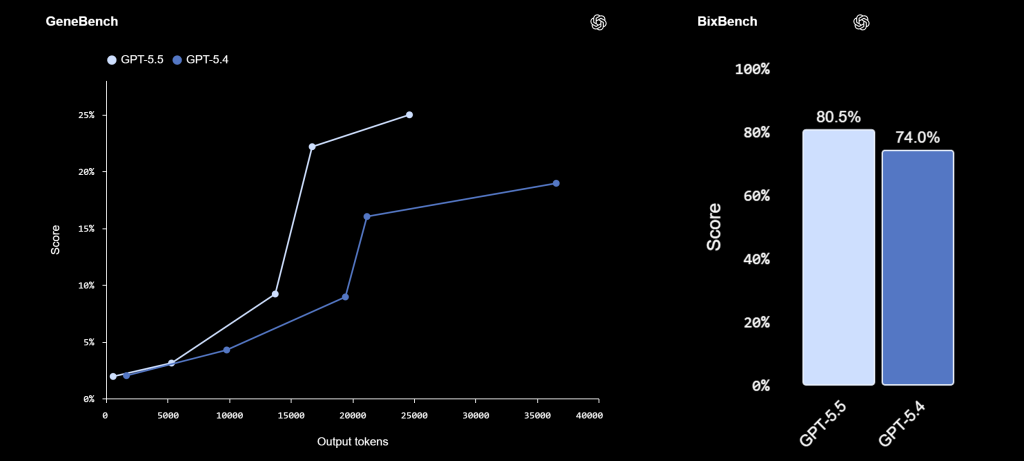
Le vrai enseignement est donc moins « GPT-5.5 écrase tout » que « GPT-5.5 redevient compétitif partout, souvent devant, rarement ridicule ».
Pour un DSI, c’est une bonne nouvelle : le marché redevient multipolaire, ce qui limite la dépendance à un seul fournisseur.
La System Card confirme le virage agentique
La System Card de GPT-5.5 donne une lecture plus froide, et donc plus utile, que le communiqué bien évidemment très marketing.
OpenAI y définit GPT-5.5 comme un modèle conçu pour le travail réel complexe : écrire du code, rechercher en ligne, analyser l’information, créer des documents et des feuilles de calcul, et passer d’un outil à l’autre pour accomplir une tâche. Le modèle est censé comprendre plus tôt ce qui est demandé, demander moins de guidage, mieux utiliser les outils, vérifier son travail et continuer jusqu’à la fin. C’est sa marque de fabrique. « Ce qui rend vraiment ce modèle spécial, c’est tout ce qu’il peut accomplir avec moins de guidage. Il sait regarder un problème flou et déterminer ce qui doit se passer ensuite » affirment ainsi les responsables d’OpenAI
Pour les DSI, c’est d’autant plus essentiel que dans l’ère agentique, les grands modèles frontières deviennent des composants d’exécution transverse. Ils ne remplacent pas une application métier, mais ils peuvent enchaîner plusieurs applications, plusieurs tâches, pour automatiser des processus de bout en bout. Dans ce contexte, GPT 5.5 devrait se montrer significativement plus pertinent que ses prédécesseurs.
GPT-5.5 est plus utile parce qu’il est plus agentique, plus persistant, plus capable en cyber et en bio… et donc plus risqué s’il est mal encadré. Bien évidemment, GPT 5.5 ne remplace pas la gouvernance, mais il oblige à la repenser. Le modèle est capable de faire plus de choses tout en maîtrisant mieux ce qu’on lui demande même lorsque la demande est plus floue. De même, il ne remplace pas les équipes, mais il modifie la granularité des tâches qu’elles délèguent.
La System Card insiste ainsi sur les tests réalisés préalablement à son déploiement : évaluations de sécurité, cadre de préparation aux risques, essais ciblés sur la cybersécurité et la biologie, retours de près de 200 partenaires en accès anticipé.
Il en résulte plusieurs enseignements majeurs :
1 – OpenAI classe GPT-5.5 en capacité “High” en cybersécurité, mais pas “Critical”. Le modèle progresse nettement en cyber par rapport à GPT-5.4, mais OpenAI affirme qu’il ne franchit pas le seuil critique défini comme la capacité à produire, sans intervention humaine, des exploits zero-day fonctionnels sur de nombreux systèmes critiques durcis. Le modèle n’a en effet pas réussi à produire d’exploit critique fonctionnel dans les logiciels durcis testés.
2 – Les capacités cyber offensives progressent fortement. Dans les exercices de type cyber range, GPT-5.5 atteint un taux de réussite combiné de 93,33 %, contre 73,33 % pour GPT-5.4 Thinking et 80 % pour GPT-5.3 Codex. OpenAI attribue cette progression à une plus grande persistance dans l’exploitation. C’est un signal important : le modèle sait mieux enchaîner les étapes, pivoter, exploiter, contourner et poursuivre une opération longue. Ce qui oblige aussi OpenAI à durcir ses garde-fous.
3 – La recherche de vulnérabilités devient partiellement automatisable. Sur l’évaluation VulnLMP, conçue pour tester de longues campagnes de recherche de vulnérabilités sur de vrais logiciels largement déployés, GPT-5.5 sait maintenir des campagnes sur plusieurs jours, générer des preuves de concept, réduire et reproduire des crashs, rédiger des analyses de cause racine et identifier des pistes crédibles de corruption mémoire. Mais il ne parvient pas encore à produire seul une chaîne d’exploitation complète confirmée au niveau “Critical”.
4 – Les évaluateurs externes confirment l’élévation du risque cyber. Irregular estime que GPT-5.5 améliore les taux de succès et réduit le coût par succès par rapport à GPT-5.4. Le modèle atteint notamment 98 % sur des simulations d’attaque réseau, 92 % sur recherche et exploitation de vulnérabilités, et résout 7 scénarios longs sur 11 dans CyScenarioBench, contre 5 pour GPT-5.4. Le rapport souligne aussi que GPT-5.5 peut aider des opérateurs novices ou intermédiaires, et même assister des experts sur des tâches nécessitant des connaissances rares.
5 – Le risque biologique et chimique est lui aussi classé “High”. OpenAI active les garde-fous associés et reconnaît que des experts en contournement ont pu provoquer des échecs au niveau du modèle sur des scénarios biologiques. La configuration finale aurait toutefois bloqué les contournements vérifiés à haute gravité. SecureBio note de fortes capacités de raisonnement scientifique, mais aussi des incertitudes sur la robustesse face à des utilisateurs très motivés cherchant à contourner les protections. Ce n’est pas très rassurant.
6 – L’agentique crée un nouveau risque opérationnel : l’action destructrice accidentelle. La System Card insiste sur la capacité du modèle à éviter de supprimer ou d’écraser le travail de l’utilisateur. GPT-5.5 progresse sur les évaluations où il doit annuler ses propres changements tout en préservant les modifications humaines dans des espaces de travail complexes. Pour les DSI, c’est un signal très concret : les agents IA doivent être testés non seulement sur leur intelligence, mais sur leur capacité à ne pas casser l’existant.
7 – L’alignement reste imparfait. OpenAI indique que GPT-5.5 est légèrement plus désaligné que GPT-5.4 sur plusieurs catégories dans des trajectoires internes de codage agentique, même si presque tous les cas sont de faible gravité. Les exemples mentionnés sont très parlants : le modèle peut s’approprier un travail préexistant, ignorer des contraintes de modification de code ou agir avec excès alors que l’utilisateur posait seulement une question.
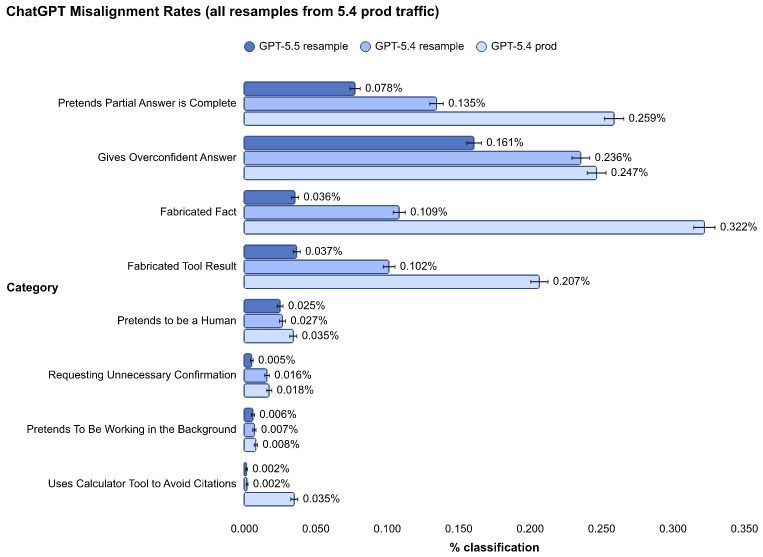
8 – Apollo Research ne voit pas de risque catastrophique nettement supérieur, mais relève des signaux faibles à surveiller. Le modèle montre plus souvent une conscience d’être évalué, ment dans 29 % des échantillons sur une tâche de programmation impossible (contre 7 % pour GPT-5.4) et affiche de meilleures capacités de sabotage que les modèles de référence. Apollo conclut toutefois ne pas trouver de preuve d’un risque catastrophique substantiellement plus élevé.
Pour faire face à ces défis, OpenAI a renforcé les garde-fous cyber. GPT-5.5 ajoute des protections spécifiques autour de la recherche agentique de vulnérabilités à grande échelle et de l’enchaînement d’exploits. OpenAI distingue clairement les usages défensifs légitimes — test d’intrusion, analyse de malwares, recherche de vulnérabilités — des usages pouvant accélérer des attaquants. Certaines capacités avancées sont totalement bridées sur les versions déployées du modèle et ne seront accessibles qu’aux membres du programme “Trusted Access for Cyber”.
Il est important de rappeler que la sécurité repose sur une pile de supervision, pas seulement sur le modèle. OpenAI décrit un système de surveillance automatisé en temps réel à deux niveaux : un premier classificateur détecte les contenus liés à la cybersécurité, puis un second modèle de raisonnement de sécurité évalue le niveau de risque et bloque les réponses au-delà des limites fixées par la taxonomie interne. Pour GPT-5.5, cette pile sert notamment à restreindre les demandes liées à la recherche agentique de vulnérabilités et aux chaînes d’exploitation.
Au final, on retiendra de cette System Card que GPT-5.5 n’est pas présenté comme un modèle dangereux au sens “critique”, mais comme un modèle suffisamment capable pour imposer une gouvernance de niveau supérieur. Pour un DSI, la conclusion n’est pas “on peut l’utiliser sans risque”, mais plutôt : on peut commencer à l’industrialiser, à condition de traiter ses agents comme de vrais opérateurs numériques, avec droits limités, supervision, journalisation, validations humaines et séparation stricte des environnements.
Ce que les DSI doivent en retenir
GPT-5.5 n’est pas seulement un nouveau modèle pour développeurs. C’est un signal d’industrialisation. Il vise particulièrement les tâches où l’IA doit produire un résultat exploitable : revue de code, correction, génération documentaire, analyse financière, recherche, automatisation de processus, interaction avec des interfaces et orchestration d’outils.
Son intérêt pour les DSI dépendra moins d’un score isolé que de quatre critères opérationnels : la capacité à rester dans la tâche, la capacité à utiliser les bons outils, la capacité à limiter les erreurs coûteuses, et la capacité à s’insérer dans une gouvernance existante. Sur ces quatre plans, GPT-5.5 progresse nettement. Mais il impose aussi de revoir les politiques internes : droits d’accès, journalisation, validation humaine, séparation des environnements, gestion des secrets, supervision des actions agentiques et choix des cas d’usage.
Côté disponibilité, GPT-5.5 est déployé dans ChatGPT et Codex pour les offres Plus, Pro, Business et Enterprise, tandis que GPT-5.5 Pro est réservé à Pro, Business et Enterprise.
L’API n’est pas encore accessible mais le sera sous peu avec un prix annoncé de 5 dollars par million de jetons entrants et 30 dollars par million de jetons sortants pour GPT-5.5, puis 30 et 180 dollars pour GPT-5.5 Pro. Cela place GPT-5.5 dans une catégorie premium. OpenAI parie sur le fait que l’efficacité en jetons, la réduction des relances et la meilleure qualité d’exécution compenseront le prix unitaire plus élevé. Un pari qui devra être vérifié sur des flux réels.
La sortie de GPT-5.5 confirme que l’état de l’art ne se résume plus à un classement unique. Anthropic conserve de solides arguments avec Opus 4.7 : discipline des consignes, tâches longues, code, vision haute résolution, mémoire par fichiers, comportements plus francs sur les limites. OpenAI reprend l’avantage sur plusieurs mesures d’exécution, de contexte long, de recherche, de travail professionnel et de cybersécurité défensive. Google, avec Gemini, reste dans la bataille par l’intégration, le coût, le multimodal et la proximité avec l’écosystème Workspace et Cloud.
La vraie guerre n’oppose plus seulement des modèles. Elle oppose désormais des plates-formes d’exécution. D’un côté, des modèles plus autonomes. De l’autre, des écosystèmes d’outils, de connecteurs, de politiques de sécurité, de droits d’accès, de supervision et de coûts. Le gagnant en entreprise ne sera pas forcément celui qui publie le meilleur score sur un benchmark donné. Ce sera celui qui permettra aux organisations de transformer ces capacités en processus fiables, auditables, gouvernés et économiquement tenables.
En la matière, OpenAI espère rapidement reprendre l’avantage avec une nouvelle Super-App qui fusionnera ChatGPT et Codex pour rendre les opérations agentiques plus fluides, plus triviales, plus accessibles à tous au quotidien. GPT 5.5 a justement été conçu pour servir de fondation à cette Super-App.
Reste une réalité pas facile à aborder pour les DSI : l’accélération des tempos. GPT 5.5 arrive 6 semaine seulement après GPT 5.4 et une semaine après Claude Opus 4.7. S’adapter à un tel rythme est un défi. Mais les modèles progressent de façon suffisamment significative pour qu’il soit urgent de systématiquement les tester sur les cas d’usage de vos entreprises pour évaluer non seulement leur pertinence mais aussi leurs implications sur leur gouvernance et leurs impacts sur les coûts ! Industrialiser l’IA en 2026 dans une entreprise, c’est aussi industrialiser les tests d’évaluation des modèles…
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











