GUIDES PRATIQUES
Comment rendre anonymes ses données clients
Par La rédaction, publié le 07 février 2011
Si les données numériques sont en sécurité dans les bases de production, leur mise en circulation expose tant l’individu que l’entreprise à des risques importants. 
Parce qu’un cadre légal impose une discipline très stricte quant à la détention et à la manipulation des informations à caractère personnel.
Parce que, très souvent, les développeurs, les prestataires, voire les formateurs, travaillent à partir de bases de données réelles, les données clients doivent impérativement être rendues anonymes, c’est-à-dire non reconnaissables par un tiers.
Tour d’horizon des principales façons de procéder afin d’y voir un peu plus clair.
1. Chiffrement et hachage
Il s’agit de masquer des informations sensibles à partir d’algorithmes de chiffrement ou de fonctions de hachage. Le premier système crypte complètement la donnée, mais il coûte assez cher et se révèle plutôt lourd en termes de traitements, notamment pour la gestion des clés. Il est possible, pour alléger le dispositif, de confier cette gestion à un tiers de confiance.
Le second procédé permet, grâce à son système d’empreinte, de modifier la donnée : Prénom Nom devient preno001. Moins robuste, il est plus léger et offre la possibilité au concepteur de reconnaître assez facilement la donnée d’origine.
2. Vieillissement, translation ou concaténation
Lorsque certaines dates sont sensibles (cas des mineurs, par exemple), il est possible de les modifier en les vieillissant. Il est également possible de transformer une donnée en une autre au moyen d’une « table de translation » : A=1, B=6, H=V, etc. Enfin plusieurs informations peuvent être regroupées en une seule par un système dit de concaténation. Ces trois méthodes ont l’avantage de pouvoir être réalisées manuellement (ou via une macro dans un tableur), sans logiciel spécifique.
3. La modification aléatoire
Quand des informations doivent sortir de l’entreprise, si l’anonymisation pure est trop complexe ou trop longue, il est possible d’avoir recours à une génération de données fictives. Elles seront aléatoires ou extraites d’une bibliothèque de prénoms, noms, type de voie, adresses éléctroniques, noms de ville, numéros de sécurité sociale, numéros de cartes bancaires, etc.
4. La suppression ou masquage
La plupart du temps, le recours aux données nominatives ne se justifie pas. C’est le cas des statistiques. Radicale, la méthode de suppression s’avère aussi la plus simple, avec un masquage total ou partiel. Il ne faut pas, en revanche, négliger quelques petits détails. Par exemple, conserver l’adresse postale dans pour garder la possibilité de remonter jusqu’à la personne.
Enfin, il est possible de simplement dissimuler certaines parties d’un libellé, comme on le voit pour les cartes bancaires pour lesquelles les chiffres sont remplacées par des XXXX-3125.
5. Quels sont les outils disponibles ?
En plus de ce que proposent déjà certaines bases de données parmi les plus connues du marché en termes de chiffrement (l’outil Optim d’IBM par exemple), il existe des produits externes comme Data Privacy de Compuware ou celui de Data Masker, qui donnent la possibilité de réaliser chacune des méthodes énoncées ci-dessus avec Oracle, SQL Server et DB2 UDB. Net2000 propose également un livre blanc sur la question, un peu technique mais très complet.
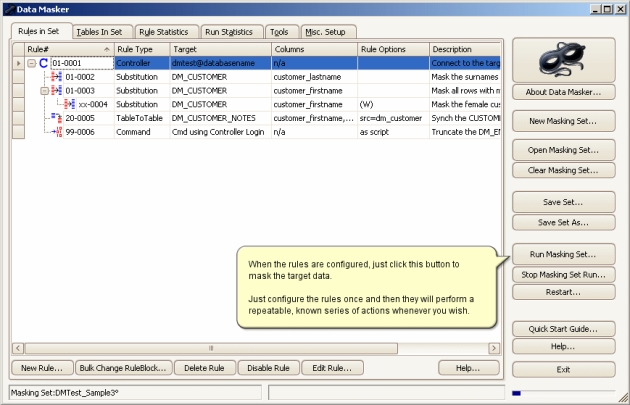
Ci-dessus un exemple de masquage de données effectué par le logiciel DataMask