


Cloud
Google Cloud libère son puissant TPU Ironwood qui redessine les frontières de l’inférence IA XXL
Par Laurent Delattre, publié le 06 novembre 2025
Google Cloud ouvre l’accès à son TPU Ironwood qui promet une inférence à très grande échelle et à moindre coût. Avec en ligne de mire l’objectif pour les DSI de réduire le coût unitaire des requêtes IA et stabiliser les SLO des applications en production. Car c’est là où se joue désormais la bataille de l’IA.
Les hyperscalers travaillent à des échelles difficiles à appréhender pour le commun des mortels. Ils déploient tellement d’équipements à travers le monde, qu’il leur est souvent rentable de développer leurs propres processeurs plutôt que d’acquérir ceux des leaders du marché des semi-conducteurs.
Alors, oui, bien sûr, les coûts initiaux, notamment de conception, de validation et d’industrialisation sont énormes, mais ils s’amortissent sur des centaines de milliers, parfois des millions, d’unités. C’est justement à cette échelle que les hyperscalers déploient des processeurs et autres accélérateurs. Il suffit d’un petit gain par puce (que ce soit au niveau du prix, de la performance par watt, ou du taux d’utilisation) répété pendant 3 à 5 ans pour rendre l’opération rentable : par exemple, 800 M$ de coûts non récurrents sont couverts si chaque puce économise environ 600 $/an sur quatre ans, soit un seuil d’environ 333 000 unités.
Sans compter que développer sa propre puce permet des optimisations de bout en bout pour aligner au mieux silicium, réseau, pile d’infrastructure, logiciels. Résultat : une infrastructure plus stable, des latences optimales, un meilleur coût par requête et une flotte de serveurs mieux utilisée, donc au final un TCO en baisse.
Par ailleurs, alors que l’approvisionnement en CPU, en GPU, en mémoire est tendu depuis la crise COVID, développer ses propres puces permet de sécuriser l’approvisionnement mais aussi de renforcer la négociation avec les fournisseurs (notamment avec Intel, AMD et Nvidia), de remplacer des marges “achetées” par des coûts internes plus bas, et lancer des offres d’instances différenciées avec des garanties de service difficiles à reproduire.
En bref, à l’échelle hyperscale, le silicium « maison » est à la fois un atout stratégique et un levier direct de marge : moins d’énergie, meilleure prévisibilité, moindre dépendance, chaque pourcent gagné, multiplié par des millions d’instances, faisant la différence.
Fabriquer CPU et NPU plutôt qu’acheter
Tout ceci pour expliquer pourquoi depuis quelques années, les hyperscalers ont lancé des grands chantiers pour développer leurs puces maison. AWS a ouvert le tir avec ses Graviton lancés en 2018 et qui sont désormais disponibles en 4ème génération (Graviton4) pour animer des instances à grande efficacité énergétique pour les bases de données, les microservices et l’IA. AWS a complété sa stratégie en lançant des accélérateurs IA dénommés Trainium2 (pour l’entrainement des modèles) et Inferentia2 (pour l’inférence des modèles).
Azure aura attendu 2025 avant de proposer lui aussi ses propres puces avec son processeur ARM Cobalt-100 et son accélérateur IA Maia-100.
De son côté, Google a commencé à concevoir ses Tensor Processing Units (des accélérateurs IA) il y a une décennie pour accélérer ses propres modèles, avant d’ouvrir la technologie aux clients via Google Cloud. Cette intégration verticale (recherche de modèles, logiciel et matériel sous un même toit) a contribué à l’émergence d’architectures comme les Transformers et à des innovations d’infrastructure (refroidissement liquide, disponibilité “five nines” depuis 2020). Les TPU sont notamment utilisés pour l’entraînement et l’inférence des modèles phares de Google que sont Gemini, Veo et Imagen mais aussi par d’autres acteurs à commencer par Anthropic et ses modèles Claude.
Cette semaine, Google Cloud a officialisé la disponibilité sur GCP de sa dernière génération de puces IA, les IronWood, dévoilées en avril dernier à l’occasion de Google Next.
IronWood marque un vrai changement d’échelle
Ironwood (7ᵉ génération de TPU) est pensé pour l’inférence à très grande échelle… sans abandonner l’entraînement ni le RL. Google annonce au moins 4 fois plus de performances que sur la génération précédente et une efficacité énergétique en hausse.
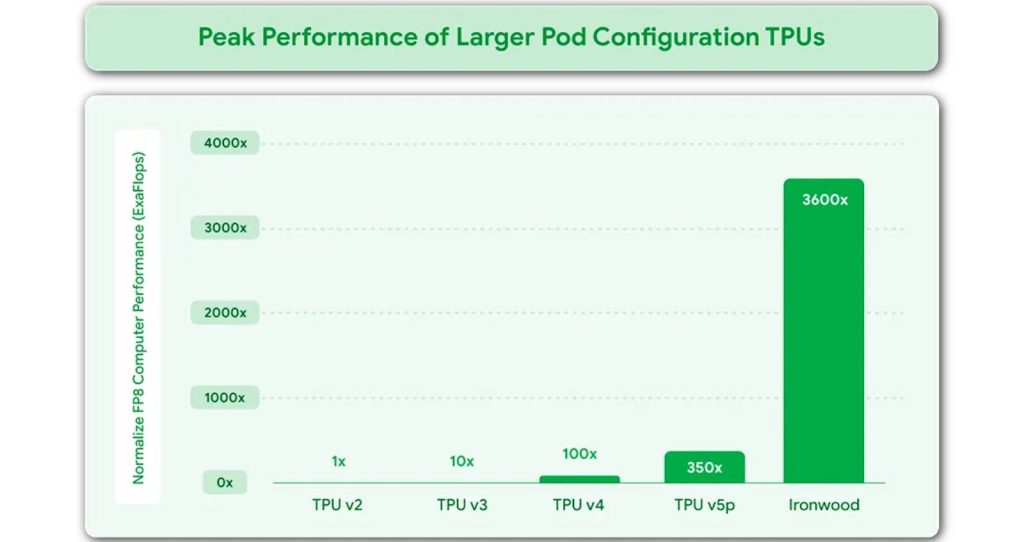
Mais ce qui fait la force et l’intérêt des TPU comme IronWood, ce n’est pas tant les capacités de la puce elle-même mais plutôt la façon dont Google peut les combiner en clusters massifs pour faire monter les IA à l’échelle. Typiquement un pod IronWood relie jusqu’à 9 216 puces via l’Inter-Chip Interconnect (une technologie de réseau dédié propriétaire) d’une bande passante de 9,6 Terabits/sec, exposant au total 1,77 Po (pétaoctets) de mémoire HBM partagée.

Ce qui permet au final à Google de revendiquer 118 fois plus d’ExaFLOPS en FP8 par pod que son concurrent le plus proche (concurrent que la firme ne nomme pas). Du coup on ne sait pas trop à quoi cela correspond. Parce qu’un NVL72 Blackwell chez Nvidia, c’est environ 720 PetaFLOPS en FP8. Mais, ici, on ne compare pas vraiment des choses comparables en mettant un Pod face à un NVL72.
Ce qui est sûr, ce qu’un Pod IronWood est optimisé pour l’inférence en FP8 et que c’est un sacré monstre de puissance. Lors de Google Next’25, l’hyperscaler annonçait une performance de 42,5 ExaFLOPS en FP8 par POD. Le graphique suivant illustre bien le saut de performance réalisé depuis la génération précédente :
Un TPU de choix pour l’AI HyperComputer
Mais chez Google, le « Pod » n’est qu’une entité de base qui sert à construire des machines surpuissantes en les combinant : l’AI HyperComputer, une plateforme unifiée qui assemble tout ce qu’il faut pour entraîner et surtout servir des modèles à grande échelle. Ironwood s’y insère comme le moteur d’inférence “gros débit” : des grappes (pods) de TPU reliées par un réseau optique interne qui fait circuler les données comme dans un seul grand système, avec une mémoire HBM vue de façon quasi partagée pour éviter les goulots d’étranglement. Autour, les GPU NVIDIA prennent le relais quand le logiciel ou le modèle y gagne, tandis que les CPU Axion font tourner les API, la préparation des données et tout l’“aval” applicatif. L’intérêt pour une DSI ? Déployer sur une même pile des charges différentes (entraînement, fine-tuning, inférence), orchestrer l’ensemble depuis les services managés de Google Cloud, et obtenir des SLO plus prévisibles avec un coût par requête mieux maîtrisé.
Et, histoire de célébrer comme il se doit l’accès d’IronWood à d’autres équipes que celles internes (Deepmind), Google Cloud annonce que la jeune pousse Anthropic a signé un accord visant à déployer d’ici la fin 2026 plus d’un gigawatt de capacité de calcul avec un accès jusqu’à un million de puces TPU pour ses futurs modèles Claude. « Ironwood améliore l’inférence et l’échelle d’entraînement, tout en conservant la vitesse et la fiabilité attendues », justifie timidemnt James Bradbury, Head of Compute chez Anthropic.
À l’âge de l’inférence IA, la capacité de servir des modèles, vite, à coût prévisible, et sous des SLO tenables fait la différence. Pour les organisations qui industrialisent l’IA, TPU Ironwood promet un bond significatif aussi bien en performance qu’en économie de ressources de calcul et optimisation des coûts. C’est aussi un pas de plus vers des IA plus frugales même si le chemin est encore long.
Axion aussi prend de l’ampleur
Disponible sur l’infrastructure de Google depuis la fin de l’année dernière, Axion est le processeur maison en ARM pour serveurs de Google. Google Cloud profite des annonces de la semaine pour étendre la disponibilité de ce processeur.
Ainsi deux nouvelles instances GCP à base d’Axion viennent rejoindre les instances C4A déjà en production. La première se nomme « N4A (preview) », il s’agit d’une instance VM de type “N series” (des VM équilibrées et tous usages) qui affirme offrir un rapport prix/performance deux fois supérieur et plus de 80% de performance par Watt comparé aux VM x86 comparables. Google Cloud y voit la solution universelle la plus accessible pour les microservices, les bases open-source, la préparation de données, ou les backends Web.
La seconde, nommée « C4A metal (preview) » constitue la première offre « bare-metal » en ARM chez Google Cloud. A l’opposée de l’instance N4A, elle vise en priorité les workloads spécialisés (hyperviseurs, dev Android, simulations, contraintes de licences).
À LIRE AUSSI :
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











