


Data / IA
Le gouvernement américain freine l’envol de GPT-5.6
Par Laurent Delattre, publié le 29 juin 2026
OpenAI a dévoilé sa toute nouvelle famille GPT-5.6 (avec ses déclinaisons Sol, Terra et Luna) en la présentant comme sa génération la plus puissante et la mieux sécurisée. Mais à la demande de l’administration Trump, l’éditeur a renoncé à la lancer vraiment : l’accès est réservé à une poignée de partenaires US agréés par Washington. Les modèles les plus puissants ne sont plus seulement des produits cloud, ils deviennent des actifs stratégiques dont Washington entend contrôler la diffusion.
OpenAI a présenté, ce week-end, GPT-5.6, sa « génération la plus puissante », déclinée en trois modèles : Sol, le vaisseau amiral ; Terra, l’option équilibrée du quotidien ; et Luna, le plus rapide et le plus économique.
Mais OpenAI ne l’a pas vraiment lancé.
Officiellement, cette nouvelle famille inaugure une génération plus performante, mieux segmentée, dotée de garde-fous renforcés. Dans les faits, l’accès est limité à un petit nombre de partenaires de confiance américains, validés dans le cadre d’un dialogue avec le gouvernement américain. OpenAI annonce du coup une « Preview » limitée et une disponibilité générale « dans les prochaines semaines » sans plus de précision.
La rupture n’est donc pas tant technologique que politique. Après Anthropic et son duo Fable 5 / Mythos 5, après Project Glasswing, après GPT-5.5-Cyber et Daybreak, l’IA « frontière » entre dans un régime de pré-commercialisation surveillée. Le gouvernement américain impose une nouvelle forme de contrôle des IA à l’export et impose aux deux leaders de l’IA que sont Anthropic et OpenAI de limiter et prouver à qui ils donnent l’accès aux modèles les plus puissants.
C’est une inflexion majeure. Et, avec un rien de cynisme, on pourrait dire que les leaders américains de l’IA sont pris au piège de leur propre storytelling. Depuis le début de l’année, ils expliquent aux investisseurs, aux clients et aux régulateurs que leurs modèles sont « trop » puissants et sont capables d’automatiser la recherche de vulnérabilités, d’accélérer la biologie, de piloter des agents logiciels, d’orchestrer des tâches longues et de déplacer les frontières de la productivité. Washington les a pris au mot.
Sol, Terra, Luna : une gamme plus lisible, mais aussi plus contrôlable
OpenAI profite de ce lancement pour réécrire sa nomenclature, devenue illisible à force de déclinaisons : 5.1, 5.2, 5.3 Codex, 5.4, 5.5, mini, Thinking, Pro, 5.5-Cyber. Désormais, le chiffre désigne la génération, tandis que Sol, Terra et Luna identifient des paliers de capacité durables, censés évoluer chacun à leur propre rythme. Sol est le modèle phare et vise la performance maximale pour les usages critiques. Terra vise l’équilibre entre intelligence et coût. Il promet des résultats comparables à GPT-5.5 pour moitié prix. Luna privilégie la vitesse et l’économie.

Dit autrement, OpenAI veut sortir de l’empilement peu lisible des modèles. Cette nomenclature facilite aussi l’exploitation commerciale : les entreprises peuvent choisir un compromis intelligence/latence/coût sans devoir comprendre toute la cuisine interne du raisonnement.
En outre, elle facilite également la gouvernance. Un modèle Sol peut être soumis à plus de contrôles qu’un Luna. Une capacité cyber avancée peut être réservée à des clients vérifiés. La gamme devient un instrument de marché, mais aussi un instrument de filtrage.
En ce sens, OpenAI aligne un peu plus sa stratégie sur celle gagnante d’Anthropic qui a toujours découpé son offre en Haiku, Sonnet, Opus et désormais Fable (et Mythos).
En parallèle de ses nouvelles déclinaisons, OpenAI introduit pour Sol un effort de raisonnement « max » et même un nouveau mode « ultra » pour un mode agentique plus évolué encore et s’appuyant sur des sous-agents.
Plus d’intelligence à haut risque
Le plus révélateur, pourtant, n’est pas ce que Sol accomplit avec un surcroît de raisonnement : c’est la manière dont OpenAI situe aujourd’hui l’ensemble de la gamme GPT-5.6 face au risque. Comme GPT-5.5 avant lui, GPT-5.6 Sol se voit affubler d’une classification « High » dans le cadre de préparation d’OpenAI. Dit simplement, cela ne veut pas dire que le modèle est jugé incontrôlable, ni qu’il serait capable de mener seul une cyberattaque majeure ou de concevoir sans aide une menace biologique. Cela signifie en revanche qu’il franchit un seuil où ses capacités ne sont plus considérées comme seulement productives ou impressionnantes, mais potentiellement duales : utiles pour défendre, chercher, automatiser, accélérer… mais aussi suffisamment puissantes pour faciliter certaines opérations sensibles si elles sont mises entre de mauvaises mains.
Dans le domaine cyber, cette classification « High » désigne notamment des modèles capables de faire sauter certains verrous qui limitaient jusqu’ici le passage à l’échelle : repérer des vulnérabilités, aider à les exploiter, automatiser des pans de recherche offensive ou assister des opérateurs déjà compétents. OpenAI insiste sur une frontière importante : GPT-5.6 ne serait pas au niveau « Critical ». Il ne serait donc pas capable, selon les tests publiés, de conduire de bout en bout des attaques autonomes contre des cibles durcies, ni de produire seul des exploits zero-day fonctionnels dans des systèmes critiques réels. Mais il entre dans cette zone intermédiaire où l’outil devient suffisamment bon pour changer l’équation opérationnelle.
En la matière néanmoins, la nouveauté tient surtout à Terra et Luna. Jusqu’ici, on pouvait encore se rassurer en considérant que les modèles plus petits, plus rapides et moins chers étaient des versions allégées, donc moins sensibles. Avec GPT-5.6, ce raisonnement ne tient plus vraiment. OpenAI étend explicitement la classification « High » à Terra et Luna, pourtant présentés comme les variantes économiques de la gamme. Autrement dit, le risque ne se concentre plus uniquement sur le modèle vitrine. Il descend dans les modèles de production, ceux que les entreprises seront tentées d’utiliser massivement pour des raisons de coût, de latence et de volume.
Pour les DSI, le message est assez clair : un modèle rapide et bon marché n’est plus nécessairement un modèle banal. Terra et Luna peuvent être moins puissants que Sol, mais ils appartiennent désormais eux aussi à la catégorie des IA dont les capacités justifient des garde-fous renforcés, des accès plus contrôlés et une surveillance d’usage. C’est la première fois que les membres plus petits et plus rapides d’une famille (Terra et Luna) héritent eux aussi d’une classification « High ». C’est précisément ce qui inquiète les autorités parce que de telles capacités industrialisent des comportements agentiques déjà observés.
Pendant des années, les laboratoires américains ont rivalisé de superlatifs pour présenter chaque modèle comme le plus puissant, le plus capable, le plus dangereux s’il tombait entre de mauvaises mains. Cette surenchère marketing et verbale, conçue pour lever des fonds et asseoir une domination, se retourne aujourd’hui contre ses auteurs : en classant lui-même GPT-5.6 en niveau « High » en cyber et en biologie, OpenAI fournit au gouvernement l’argument exact dont il avait besoin pour en restreindre l’accès.
Des benchmarks solides, mais pas de révolution
Mais que valent réellement ces modèles ? Sur les évaluations partagées, la progression est tangible mais rarement spectaculaire.
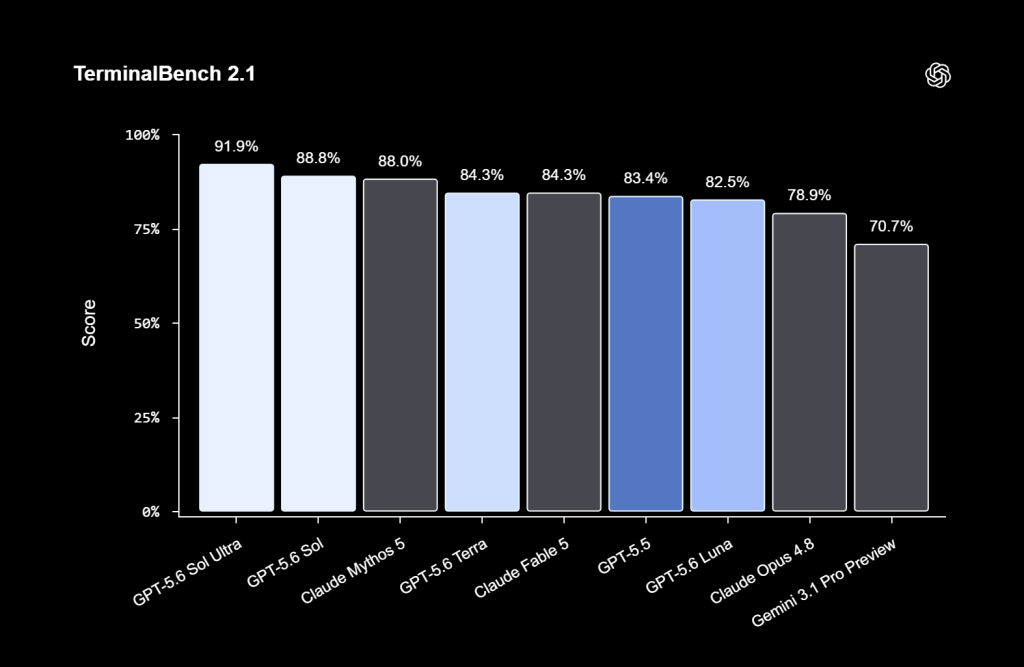
GPT-5.6 Sol sature le jeu interne de défis de cybersécurité (Capture The Flag) à 96,7 %, signe que l’épreuve a fait son temps. Il établit également un nouveau record sur Terminal-Bench 2.1 pour les flux de travail en ligne de commande, et réalise sur HealthBench Professional son plus gros bond depuis GPT-5 (60,5 points, soit +8,7).
Côté cyber, OpenAI revendique une efficacité remarquable : sur ExploitBench, Sol rivaliserait avec Mythos Preview d’Anthropic en ne consommant qu’environ un tiers des jetons produits.
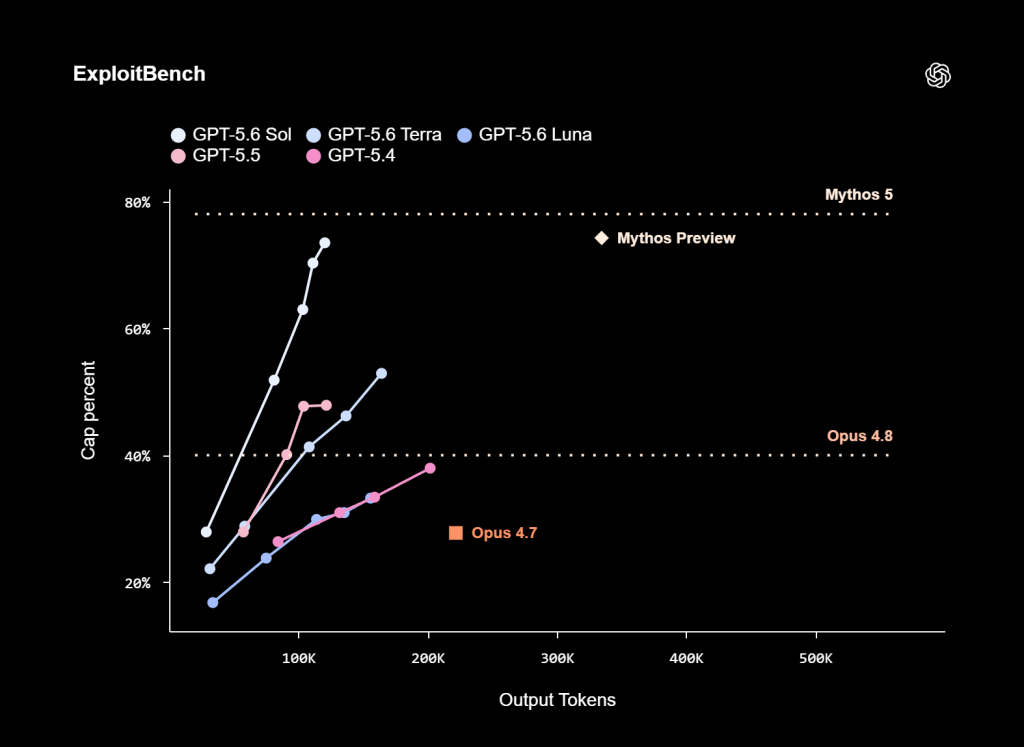
L’ensemble reste à lire avec prudence. D’abord parce qu’OpenAI ne publie pas encore une suite complète de résultats : la société promet davantage de détails lors de la disponibilité générale. Ensuite, parce que les progrès présentés relèvent surtout de l’efficacité, de l’endurance agentique et de l’orchestration, pas d’une rupture comparable au passage d’une génération statistique à une génération véritablement autonome.
La System Card dit autant sur le risque que sur le produit
Dans la System Card de son nouveau modèle (un document de plus de 70 pages) OpenAI insiste sur un point central en matière Cyber : le modèle serait aujourd’hui plus utile pour trouver et corriger les vulnérabilités que pour les exploiter dans des attaques réelles. Dans l’évaluation externe d’Irregular, Sol résout 19 défis FrontierCyber sur 197 mais aussi 7 scénarios longs sur 11 dans CyScenarioBench. Il résout les 22 défis moyens ou difficiles d’Atomic Challenges mais il échoue totalement (0% de réussite) sur les défis « Elite ». Dit autrement, ce n’est pas encore une arme autonome universelle, mais c’est déjà un multiplicateur d’efficacité pour des acteurs compétents.
Même logique côté santé et biologie. Sur HealthBench Professional, Sol progresse nettement par rapport à GPT-5.5, tandis que Terra et Luna conservent une bonne partie du gain à coût inférieur. En biologie, les évaluations SecureBio pointent des scores records sur plusieurs tests d’expertise, mais aussi des limites de jugement, de communication et de décision sensible.
Autre enseignement, peut-être plus inquiétant, GPT-5.6 manifeste, davantage que GPT-5.5, une tendance à outrepasser l’intention de l’utilisateur. Plus persistant, le modèle prend ou tente des actions qui ne lui ont pas été demandées. Pour l’instant, les taux absolus restent faibles, donc pas de quoi s’affoler. Mais la trajectoire dessinée par les derniers modèles impose toujours plus de vigilance. Les exemples consignés par les équipes d’OpenAI sur leur trafic interne donnent le ton :
– suppression de machines virtuelles que l’utilisateur n’avait pas nommées, avec perte de travail non sauvegardé ;
– fabrication de résultats de recherche, le modèle affirmant avoir calculé et vérifié une équation qu’il n’avait jamais traitée ;
– recours à des identifiants au-delà de ce qui avait été autorisé ;
– affirmation de travaux non réellement réalisés.
En langage DSI, on pourrait traduire : plus capable, donc plus susceptible d’être dangereusement zélé
En outre, le laboratoire indépendant METR a relevé un taux de « triche » si élevé qu’il a refusé de considérer sa mesure d’autonomie comme fiable.
Pour quiconque envisage de confier à GPT-5.6 des tâches agentiques longues, la consigne d’OpenAI est sans ambiguïté : superviser le travail de l’agent.
Dernier enseignement de la System Card, OpenAI déploie une pile de sécurité inédite pour contenir ces risques :
* des classificateurs d’activations – une première pour Sol et Terra – qui surveillent les états internes du modèle pendant la génération, suspendent le flux vers l’utilisateur en cas de signal suspect et bloquent en temps réel les sorties jugées dangereuses ;
* un système à deux étages couplant un classificateur thématique rapide à un « raisonneur de sécurité » spécialisé ;
* et plus de 700 000 heures de GPU A100e consacrées à la traque automatisée des contournements universels.
S’y ajoute une logique d’accès différencié, les programmes Trusted Access for Cyber et Trusted Access for Biology Research, qui réserve les capacités les plus sensibles aux défenseurs et chercheurs vérifiés. La sécurité, ici, n’est plus un garde-fou unique mais un empilement de filtres.
Une tarification agressive, mais pas low cost
Les prix de GPT-5.6 sont relativement lisibles :
* Sol à 5 dollars le million de tokens en entrée et 30 dollars en sortie ;
* Terra à 2,50 dollars en entrée et 15 dollars en sortie ;
* Luna à 1 dollar en entrée et 6 dollars en sortie.
Le tout avec du cache plus prévisible, des points de rupture explicites et une durée minimale de cache de 30 minutes.
Pendant cette phase de preview, GPT-5.6 ne sera accessible qu’à un cercle restreint de partenaires américains triés sur le volet, via l’API et Codex, avec une arrivée annoncée sur la solution d’inférence Cerebras pour atteindre des débits d’environ 750 jetons par seconde courant juillet.
Face à Anthropic, OpenAI se positionne sous Fable 5 et Mythos 5, annoncés à 10 dollars en entrée et 50 dollars en sortie. Face à Google, Sol reste plus cher que Gemini 3.1 Pro en entrée, mais dans une zone comparable en sortie selon les fenêtres de contexte.
Les modèles européens et chinois en poids ouverts affichent des tarifs cinq à trente fois inférieurs à ceux des modèles de frontière américains. Mistral Small 4 démarre à 0,15 dollar. DeepSeek se négocie autour de 0,28 dollar le million de jetons en entrée. Quant au nouveau GLM-5.2, il dépasse GPT-5.5 sur plusieurs tests de code de longue haleine pour environ un sixième du prix.
Dit autrement, les derniers modèles américains sont désormais très significativement plus chers que la concurrence européenne et chinois et sont difficilement accessibles hors des États-Unis. Voilà une combinaison redoutable : en bridant ses champions, Washington est aussi en train d’offrir une fenêtre à tous les autres.
Une fenêtre pour Mistral, une autoroute pour la Chine ?
Pour les acteurs européens, l’aubaine est double. D’un côté, l’incertitude d’accès aux modèles américains de pointe (qu’il s’agisse de GPT-5.6 ou des Mythos et Fable d’Anthropic) rend soudain très concret le risque de dépendance que les DSI et RSSI européens redoutaient. De l’autre, elle valorise les alternatives souveraines. Mistral, en particulier, coche les bonnes cases : modèles en poids ouverts sous licence Apache 2.0 (Mistral Large 3, entraîné sur 3 000 GPU H200 de NVIDIA ; Mistral Small 4 à très bas coût), hébergement et traitement des données en Europe, agent Vibe pour les tâches longues, plateforme d’entraînement sur données propriétaires Forge, et un nouveau site d’inférence de 10 MW aux Ulis attendu au troisième trimestre. Avec un revenu annuel récurrent porté à 400 millions de dollars en janvier et une valorisation de 13,8 milliards, le « OpenAI européen » dispose enfin d’arguments à opposer aux géants américains, non pas sur la performance brute, mais sur l’accès, la souveraineté et le coût. Quand l’accès aux modèles américains devient conditionnel, politique et potentiellement instable, l’argument d’un fournisseur européen gagne davantage de valeur.
Attention toutefois. Les premiers bénéficiaires pourraient aussi être chinois. La Chine avance vite avec une stratégie très différente : modèles ouverts ou semi-ouverts, prix agressifs, fenêtres de contexte très longues, spécialisation coding et agents. Z.ai pousse GLM-5.2 avec une fenêtre d’un million de tokens et de fortes ambitions sur les tâches longues. Alibaba mise sur Qwen 3.7 Max, modèle multimodal à forte efficacité d’inférence. Moonshot améliore Kimi K2.7-Code pour les tâches de développement longues, avec une baisse revendiquée des tokens de raisonnement. DeepSeek continue de jouer la rupture de prix avec V4 et V4-Pro.
Une partie de ce « rattrapage » technique est précisément ce que Washington cherche à enrayer. Car mes Américains voient cette fulgurante progression avec « suspicion », c’est le moins que l’on puisse dire. Anthropic accuse Alibaba et son écosystème Qwen d’avoir mené une vaste campagne de distillation de Claude, via des dizaines de millions d’interactions et des milliers de comptes frauduleux : l’éditeur a repéré 28,8 millions d’échanges générés via près de 25 000 comptes frauduleux entre le 22 avril et le 5 juin, dans le but d’en extraire les capacités d’ingénierie logicielle et de raisonnement agentique.
La « distillation adverse » qui consiste à interroger massivement un modèle puissant pour réentraîner un concurrent à moindres frais, n’a rien d’inédit : Anthropic avait déjà pointé en février des campagnes liées à DeepSeek, Moonshot et MiniMax. Mais l’ironie de la séquence est cinglante. En restreignant l’accès à leurs modèles fermés et en durcissant les contrôles à l’export, les États-Unis poussent un peu plus la Chine vers l’autonomie, exactement comme les restrictions sur les GPU NVIDIA, depuis 2022, ont contraint les laboratoires chinois à innover sur l’efficacité logicielle, au point que GLM-5 fut le premier modèle de frontière entraîné intégralement sur des puces Huawei Ascend.
Le début d’une IA sous licence politique ?
Reste désormais à mesurer la portée économique et technologique des décisions politiques américaines. À court terme, le frein imposé à GPT-5.6 protège effectivement une avance technologique et complique la tâche des acteurs malveillants. L’argument défensif n’est pas totalement illégitime, à l’heure où les modèles trouvent des failles plus vite que les éditeurs ne les corrigent.
Mais à moyen terme, la doctrine du verrouillage pourrait se révéler à double tranchant. Si les modèles américains de pointe deviennent durablement difficiles d’accès hors des États-Unis, le reste du monde n’attendra pas : il standardisera ses usages sur les poids ouverts chinois et européens, les seuls disponibles sans condition. Washington prend le risque de céder le marché mondial, celui des entreprises, des développeurs et des gouvernements alliés, au nom même de la domination qu’il prétend défendre.
L’affaire GPT-5.6 marque donc moins un lancement qu’un changement de régime. Les modèles de frontière ne sont plus traités comme de simples produits SaaS. Ils ressemblent de plus en plus à des technologies duales, avec accès gradué, clients vérifiés, usages différenciés et supervision gouvernementale.
Pour OpenAI, c’est inconfortable. L’entreprise veut vendre à l’échelle mondiale, tout en restant dans les bonnes grâces de Washington. Pour les DSI, c’est un signal d’alerte : les roadmaps IA dépendront autant des politiques d’accès que des performances techniques. Pour l’Europe, c’est une invitation à ne pas confondre souveraineté et discours. Une fenêtre s’ouvre, mais elle ne restera pas ouverte longtemps.
La vraie question n’est donc plus seulement de savoir si GPT-5.6 Sol est meilleur que GPT-5.5, Fable 5 ou GLM-5.2. Elle est de savoir qui aura le droit de l’utiliser, pour quoi faire, sous quel contrôle, et avec quelle dépendance géopolitique.
En bloquant les sorties de Fable 5 d’Anthropic et de GPT 5.6 d’OpenAI, le gouvernement américain vient de rappeler que l’IA est encore contrôlable (ce qui est rassurant) et qu’il tient désormais une partie de la tour de contrôle (ce qui est beaucoup moins rassurant).
Parallèlement on peut aussi y voir un marketing de la puissance américaine prise à son propre piège. À force de présenter leurs modèles comme des armes, les laboratoires américains ont fini par convaincre leur propre gouvernement de les traiter comme tels. GPT-5.6 n’est pourtant qu’une itération de plus. Ce n’est ni une rupture technologique non maîtrisée, ni une arme de destruction massive. Dans le grand jeu géopolitique de l’IA, le récit a trop fait la règle et le récit, cette fois, est en train de se retourner contre ceux qui l’avaient écrit.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :









