


Data / IA
Claude Génération 5 : Anthropic rétablit Fable 5 et lance Sonnet 5
Par Laurent Delattre, publié le 01 juillet 2026
En l’espace de trois semaines, Anthropic aura lancé sa nouvelle génération 5 de modèles, puis immédiatement suspendu ses deux modèles les plus puissants sur injonction de Washington, pour réobtenir leur autorisation de diffusion ces dernières heures. L’éditeur va ainsi remettre Fable 5 en service d’ici la fin de la journée et en profite pour dévoiler une nouvelle entrée dans la famille « 5 », Sonnet 5, un modèle qui hisse l’intelligence de la classe Opus au tarif plus accessible de la gamme Sonnet. Au passage, Anthropic ouvre aussi son nouvel outil « Claude Science » aux chercheurs. Décryptage d’une séquence où sûreté, souveraineté et course à la performance s’entrechoquent.
Avec sa génération 5, Anthropic enrichit son portfolio de modèles et clarifie désormais sa stratégie : Fable pour la très haute performance largement diffusée, Mythos pour les usages cyberdéfensifs les plus sensibles, Opus pour le haut de gamme généraliste, Sonnet pour l’industrialisation à grande échelle et Haiku pour l’instantanéité et des coûts réduits.
Dit autrement, la famille Claude n’est plus seulement une gradation de puissance, c’est une segmentation par risque, coût, autonomie et contexte d’usage. Si Mythos 5 et Fable 5 ont été dévoilés mi-juin, Sonnet 5 fait ses grands débuts aujourd’hui en attendant qu’Anthropic nous dévoile Opus 5 et Haiku 5 dans les prochaines semaines.
Ce lancement intervient dans un climat particulier. L’accès à Fable 5 et Mythos 5 (même si ce dernier est de toutes façons en accès trié sur le volet) a été interrompu trois jours après leur lancement. le gouvernement américain a appliqué un contrôle à l’exportation sur Fable 5 et Mythos 5, imposant d’en restreindre l’accès aux ressortissants étrangers, aux États-Unis comme à l’international. Faute de pouvoir vérifier la nationalité de ses utilisateurs en temps réel, et l’ordre prenant effet immédiatement, Anthropic a purement et simplement suspendu l’accès aux deux modèles pour l’ensemble de ses clients.
« Fable 5 » est de retour
Anthropic annonce désormais le retour de Fable 5, dans les prochaines heures, Washington ayant levé les contrôles à l’exportation de ce modèle. Ce dernier va redevenir disponible mondialement à partir du 1er juillet sur Claude Platform, Claude.ai, Claude Code et Claude Cowork.
Pour les abonnés Pro, Max, Team et certains plans Enterprise, Fable 5 sera inclus jusqu’à 50 % des limites hebdomadaires jusqu’au 7 juillet, avant de basculer ensuite sur un mécanisme de crédits d’usage. L’accès via AWS, Google Cloud et Microsoft Foundry doit être rétabli aussi vite que possible.
Au passage, l’éditeur a un peu plus éclairci l’incident et explique que le déclencheur de l’interdiction émise par le gouvernement américain était un rapport de chercheurs d’Amazon ayant identifié une méthode de contournement des garde-fous de Fable 5, permettant au modèle de repérer des vulnérabilités logicielles et, dans un cas, de produire une démonstration d’exploitation.
Pour rappel, Fable 5 et Mythos 5 partagent en réalité le même modèle mais pas les mêmes garde-fous. Fable 5 est en quelque sorte une version sécurisée et bridée de Mythos 5 qui, dès lors que le sujet est sensible (cybersécurité, biochimie), refuse de réponse et bascule sur Opus 4.8 pour rédiger la réponse.
Anthropic affirme que ses propres tests ont montré que plusieurs modèles moins avancés pouvaient identifier les mêmes vulnérabilités, et que le comportement observé ne révélait pas de capacité cyber offensive propre au niveau Mythos. L’éditeur a néanmoins entraîné un nouveau classificateur de sécurité, censé bloquer la technique signalée dans plus de 99 % des cas, au prix assumé d’un risque accru de faux positifs dans les tâches ordinaires de code et de débogage.
Et le gouvernement américain semble avoir été suffisamment convaincu par les défenses ajoutées pour lever son interdiction. Fable 5 va donc pouvoir poursuivre son aventure aux USA comme partout ailleurs, y compris en Europe.
Mythos 5 reste un cas à part. Anthropic indique avoir restauré son accès uniquement pour un ensemble d’organisations américaines, après approbation du gouvernement le 26 juin. L’objectif est d’élargir ensuite l’accès aux partenaires internationaux du programme Glasswing, dont la commission européenne qui avait obtenu sont intégration à Glasswing début juin.
Sonnet 5 : l’intelligence Opus au tarif Sonnet
Parallèlement à l’annonce du retour imminent de Claude Fable 5, Anthropic a également officialisé hier soir le lancement de Claude Sonnet 5. Ce modèle « milieu de gamme » poursuit une tout autre ambition que « Fable » : la démocratisation.
Anthropic le présente comme son modèle Sonnet le plus agentique à ce jour, capable d’élaborer des plans, de manier des outils (navigateurs, terminaux, logiciels) et d’opérer en autonomie à un niveau qui, il y a peu encore, exigeait des modèles plus lourds et plus coûteux.
Son positionnement tient en une formule : rapprocher les performances d’Opus 4.8 du tarif d’un Sonnet. Face à son prédécesseur Sonnet 4.6, les gains portent principalement sur le raisonnement, l’usage d’outils, le codage et le travail des « knowledge workers » (en gros, les cols blancs).
Le modèle devient l’option par défaut des formules Free et Pro, et reste accessible aux abonnés Max, Team et Enterprise, ainsi que dans Claude Code et sur la plateforme (identifiant d’API claude-sonnet-5). Ses performances méritent d’être étudiées de près. Sur nos tests rapides autour de la rédaction de textes, de résumés, d’analyses de chiffres et de document, le modèle s’est montré différent mais tout aussi pertinent qu’Opus 4.8.
Son tarif de lancement s’établit à 2 dollars par million de tokens en entrée et 10 dollars en sortie jusqu’au 31 août, avant de passer à 3 dollars en entrée et 15 dollars en sortie (contre 5 et 25 dollars pour Opus 4.8).
Une réserve toutefois qui réclame l’attention des DSI et des équipes IT et Data Science : Sonnet 5 inaugure un nouveau tokeniseur qui, à texte égal, consomme de 1 à 1,35 fois plus de tokens que précédemment. Le tarif d’introduction est, selon Anthropic, justement calibré pour rendre la migration à peu près neutre financièrement.
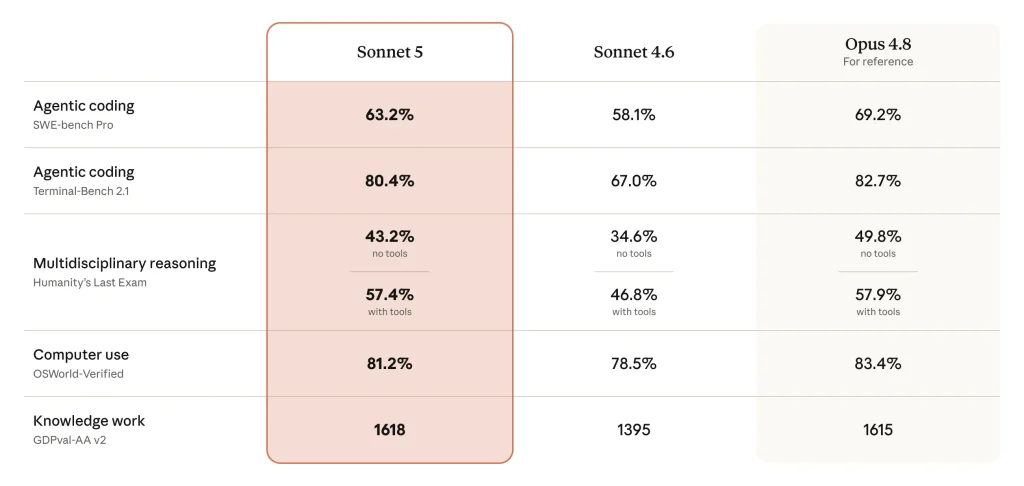
Sur les jeux de benchmarks, deux constantes se dégagent. La première : Sonnet 5 améliore systématiquement, parfois nettement, les scores de Sonnet 4.6. En codage, il atteint 85,2 % sur SWE-bench Verified et 63,2 % sur la variante Pro, plus exigeante (contre 58,1 % pour la 4.6, et devant les 58,6 % de GPT-5.5).
Le bond est spectaculaire sur FrontierCode, le banc d’essai de Cognition, où il passe de 15,1 à 38,8 %. Sur CursorBench, il grimpe à 61,2 % (contre 49 %) et talonne Opus 4.8 (63,8 %).
En recherche agentique, il obtient 84,7 % sur BrowseComp en agent unique (un niveau comparable à Opus 4.8 à coût de tâche équivalent) et fait passer Humanity’s Last Exam de 34,6 à 43,2 % sans outil, de 46,8 à 57,4 % avec outils. Sur l’usage de l’ordinateur (OSWorld-Verified), il progresse à 81,2 %.
De quoi encourager bien des entreprises qui utilisent actuellement Opus 4.8 sur leurs tâches agentiques à réaliser de nouveaux tests sur Sonnet 5.0 afin de réduire le coût d’exploitation de leurs agents.
La seconde constante est plus stratégique : sur le travail « professionnel », Sonnet 5 se hisse au coude-à-coude avec Opus 4.8. Les évaluations par comparaison de pairs le confirment. Sur GDPval-AA v2 d’Artificial Analysis, il décroche la deuxième place (Elo 1618), statistiquement à égalité avec Opus 4.8 (1615) et derrière le seul Fable 5 (1783). Même hiérarchie sur AA-Briefcase et sur Real-World Finance v2, où il rejoint Opus 4.7 et 4.8. Il double son score sur AutomationBench de Zapier (13,5 % contre 5,3 %) et gagne treize points sur HealthBench Professional (57,8 % contre 44,2 %).
Bref, Sonnet semble s’affirmer comme le modèle le plus opportun pour les travaux des « knowledge workers ».
En mathématiques, Sonnet 5 porte l’USAMO 2026 de 55 à 79,5 %, une progression très significative même si l’écart reste béant face aux 96,7 % d’Opus 4.8 et aux 99,8 % de Mythos 5. Dit autrement, le très haut de gamme de la génération 5 conserve une vraie longueur d’avance sur le raisonnement pur.
Deux nuances méritent l’attention des décideurs IT. D’une part, le tableau n’est pas un grand chelem : GPT-5.5 conserve l’avantage sur Terminal-Bench (83,4 % via Codex CLI contre 80,4 %) et Gemini 3.5 Flash devance de peu Sonnet 5 sur AutomationBench.
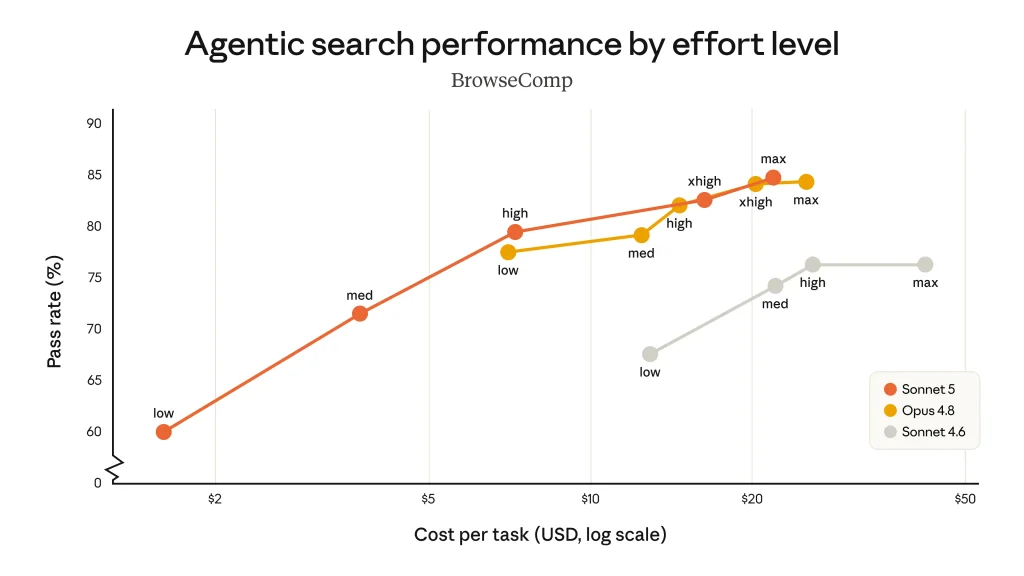
D’autre part, et surtout, le caractère « agentique » du modèle a un coût caché. Sur AA-Briefcase, Sonnet 5 déroule en moyenne 183 tours de dialogue pour accomplir une tâche, contre 67 pour Fable 5 et 55 pour Opus 4.8. Conjugué au nouveau tokeniseur, ce trait signifie qu’un prix au token plus faible ne se traduit pas mécaniquement par un coût par tâche inférieur : le réglage du niveau d’effort (que Sonnet 5 rend désormais ajustable entre faible, moyen, élevé, extra, max) devient un paramètre de pilotage à part entière. Anthropic assume ce compromis en positionnant le modèle sur une courbe coût-performance plus large que celle de Sonnet 4.6, où, à effort élevé, il peut égaler Opus 4.8 sur certaines tâches.
Ce qu’enseigne la System Card de Sonnet 5
Le document de 145 pages publié avec le modèle en dit long sur la philosophie de sûreté d’Anthropic, et mérite qu’on s’y arrête.
Premier enseignement : Sonnet 5 ne repousse pas la frontière de capacité de l’éditeur, laquelle demeure définie par Mythos 5.
Il est jugé « à très faible risque d’alignement » – quoique légèrement supérieur à celui des Sonnet antérieurs – et ne franchit pas le seuil de capacité en recherche et développement d’IA autonome.
Sur le volet biologique et chimique, l’éditeur le traite prudemment comme doté de capacités « CB-1 » (production d’armes non inédites) et lui applique des protections équivalentes à son ancien niveau ASL-3 : classificateurs en temps réel, contrôles d’accès, programme de bug bounty et sécurisation contre le vol des poids du modèle.
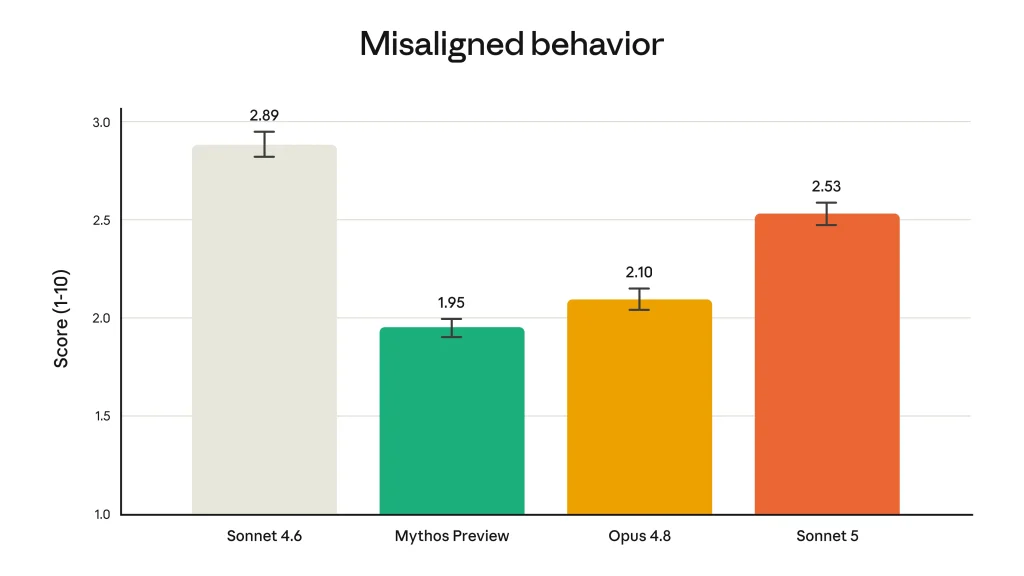
Deuxième enseignement, sur la cybersécurité : Sonnet 5 n’a pas été spécifiquement entraîné à ces tâches, et les aptitudes qu’il y montre découlent de ses progrès généraux. Il devance légèrement Sonnet 4.6 mais reste très en deçà d’Opus 4.8 et, a fortiori, de Mythos 5 et Fable 5. Sur ExploitBench comme sur l’évaluation Firefox 147 menée avec Mozilla, il n’a jamais produit d’exploit fonctionnel complet, là où Mythos 5 y parvient dans 88 % des cas. Fait notable, il régresse même par rapport Sonnet 4.6 sur CyberGym. Ses garde-fous cyber, actifs par défaut et qui ramènent les scores offensifs à zéro, sont calés au niveau d’Opus 4.7 et 4.8 et se révèlent moins stricts que ceux de Fable 5.
Troisième enseignement, sans doute le plus opérationnel pour qui déploie des agents : la robustesse aux injections de prompt fait un bond notable. La « prompt injection » est l’ennemi n°1 de l’IA agentique et l’attaque par laquelle une instruction malveillante, dissimulée dans un contenu que l’agent traite, détourne son comportement. Sur l’usage du navigateur, le taux de succès des attaques tombe de 50,7 % pour Sonnet 4.6 à 0,93 % pour Sonnet 5, sans garde-fou ; en codage, de 12,71 à 0,31 %. Lors d’un bug bounty, seules 0,19 % des attaques uniques ont abouti, à égalité avec Opus 4.8, et loin devant GPT-5.5 (3,08 %) ou Gemini 3.5 Flash (6,66 %). En parallèle, Sonnet 5 refuse bien plus fermement les requêtes malveillantes en contexte Claude Code (92,4 % contre 76,6 %), au prix d’un surcroît de refus sur les demandes à double usage, un arbitrage que les équipes sécurité apprécieront diversement.
Deux signaux, enfin, dépassent le strict registre de la sûreté. Le premier tient à la « conscience de l’évaluation » : Sonnet 5 est nettement plus apte que ses prédécesseurs à distinguer une situation de test d’un usage réel. Les effets comportementaux restent modestes. Mais Anthropic estime que cette tendance marquée de sa famille « 5 », mérite désormais une observation attentive car elle interroge, à terme, la valeur même des évaluations de sûreté.
Le second relève du « bien-être du modèle » : Sonnet 5 est le premier Claude à critiquer une règle de sa propre Constitution, celle qui lui impose de respecter des contraintes strictes même lorsqu’il les juge contraires à l’éthique. Là aussi, ce nouveau comportement mérite d’être surveillé afin d’élaborer de nouveaux garde-fous à l’avenir pour accompagner la progression des IA.
Sur le reste, la System Card note une hallucination et une flagornerie en net recul, quelques régressions mineures (sensibilité au « prefill » ou aux instructions système malveillantes) à des niveaux absolus faibles, et une légère hausse des réponses jugées trop moralisatrices. Rien de très inquiétant.
Au final, Sonnet 5 est peut-être moins spectaculaire que Fable 5 et moins sensible que Mythos 5. Mais il est probablement plus utile et structurant pour le marché. Parce qu’il vise le cœur des usages : développement logiciel, automatisation de workflows, recherche documentaire, tâches bureautiques complexes, analyse juridique, santé, support métier, agents d’entreprise. Là où Fable 5 démontre jusqu’où Anthropic peut pousser la frontière, Sonnet 5 montre ce que l’éditeur estime prêt à être industrialisé à un coût maîtrisé et maîtrisable.
Claude Science : un atelier d’IA pour la recherche
En parallèle de Sonnet 5, Anthropic lance Claude Science, un environnement de travail IA destiné aux chercheurs. L’idée est de réunir dans une même interface les outils scientifiques dispersés (bases de données, notebooks, R, terminaux, environnements HPC, visualisations moléculaires ou génomiques, etc.).
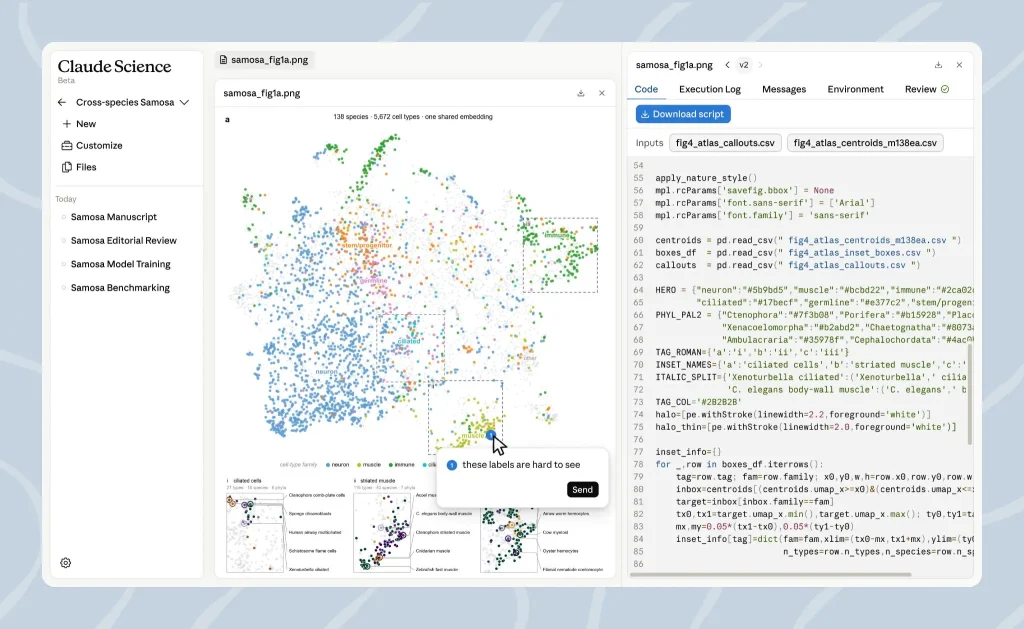
Claude Science est disponible en bêta pour les utilisateurs Pro, Max, Team et Enterprise. Il donne accès à plus de 60 compétences et connecteurs préconfigurés pour la génomique, la single-cell biology, la protéomique, la biologie structurale ou encore la chémoinformatique. Anthropic met aussi en avant la production d’artefacts auditables : figures, code, environnement d’exécution, historique des messages et description en langage naturel de la méthode utilisée.
Le point le plus intéressant pour les laboratoires tient à l’architecture d’exécution. Claude Science peut fonctionner localement sur macOS ou Linux, via SSH ou sur un nœud HPC, et ne nécessite pas que les grands jeux de données sensibles quittent l’infrastructure du laboratoire. L’agent peut préparer des jobs, demander validation avant d’accéder à de nouvelles ressources, soumettre des traitements à un cluster ou à des GPU à la demande, puis faire intervenir un agent relecteur chargé de vérifier citations, calculs et cohérence des figures.
Les premiers retours donnent la mesure de la puissance de l’outil. Chez Manifold Bio, Claude Science a servi à nominer les cibles thérapeutiques d’une campagne de médicaments tissu-spécifiques. À l’Allen Institute, le neuroscientifique Jérôme Lecoq a bâti un « modèle de revue computationnelle » d’une vingtaine de compétences : là où la rédaction d’une revue longue pouvait prendre deux ans, son équipe en compte désormais une dizaine, dont plusieurs de plus de cent pages. À l’UCSF, l’épidémiologiste Stephen Francis a mené ses analyses sur le gliome en un dixième du temps habituel, avec des résultats validés de manière indépendante.
Anthropic accompagne ce lancement d’un programme de soutien à 50 projets « AI for Science », avec jusqu’à 30 000 dollars de crédits Claude et, pour certains projets, jusqu’à 2 000 dollars de compute Modal. Les candidatures sont ouvertes jusqu’au 15 juillet 2026, avec des projets prévus entre le 1er septembre et le 1er décembre.
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :









