Data / IA
Que nous apprend la System Card de Claude Opus 4.5, le nouveau modèle d’Anthropic
Par Laurent Delattre, publié le 25 novembre 2025
La bataille entre Anthropic, OpenAI et Google autour des modèles frontières déplace désormais le combat du bench vers le terrain des agents qui manipulent le code, les outils et les politiques d’entreprise. La sortie de Claude Opus 4.5 cette semaine éclaire une nouvelle la progression récente et importante des LLM géants et cette évolution vers l’agentique… avec tous les risques que pose une intelligence désormais capable d’agir, d’orchestrer et de décider dans des environnements réels. La lecture de la System Card du nouveau modèle d’Anthropic nous en apprend ainsi beaucoup…
À quelques jours d’intervalle, les trois acteurs des modèles frontières ont lancé de nouvelles itérations majeures et repoussé le plafond de verre que l’on croyait désormais limiter les performances des LLMs. Cette semaine, Anthropic a lancé son nouveau fer de lance Claude Opus 4.5 pour revenir dans la course face à l’excellent GPT 5.1 d’OpenAI et à l’omniprésent Gemini 3 de Google.
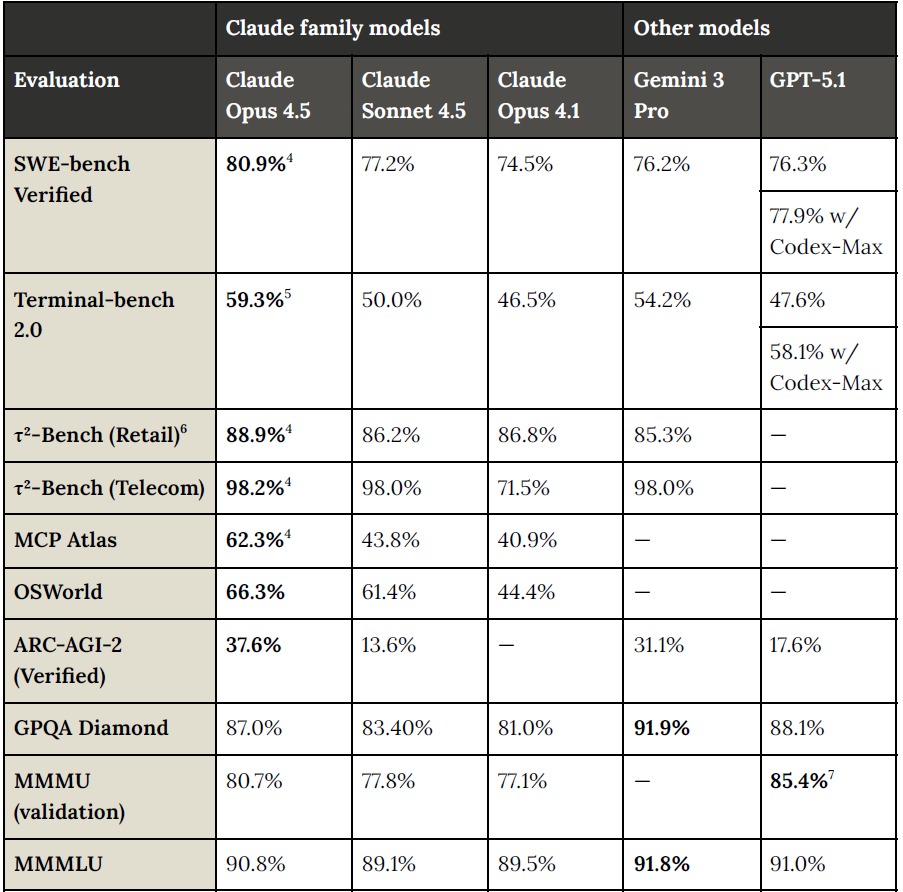
Au-delà des Benchmarks, qui démontrent une nouvelle fois le saut réalisé par Anthropic depuis Claude Opus 4.1 et les gains de perspicacité des IA frontières sur le codage et les tâches agentiques, que dévoile la System Card du nouveau modèle Claude Opus 4.5. On le sait, les benchs n’offrent que des indices utiles, mais souvent peu significatifs de la pertinence des modèles pour les différents cas d’usage de chaque entreprise. Une des raisons pour lesquelles Anthropic, dans sa communication se focalise beaucoup sur les performances de codage et d’ingénierie de ses modèles, l’un des scénarios les mieux identifiés et les plus communs. Un scénario aussi où Anthropic excelle depuis plusieurs générations de modèles.
Fouiller dans la System Card d’un modèle permet souvent d’en apprendre bien plus sur les progrès réalisés et les limites des nouveaux modèles que ne le font les benchs. La System Card de Claude Opus 4.5, un document technique de plus de 150 pages, raconte ainsi bien mieux ce qui a réellement changé : on y lit moins un simple “refresh” de modèle qu’un repositionnement assumé vers l’IA agentique, le coding avancé et la sûreté d’usage. Elle donne les clés aux DSI pour comprendre où Opus 4.5 se situe dans le nouveau paysage des modèles “frontier” et pourquoi le supposé « plafond de verre » des LLM vient, une fois encore, d’être repoussé.
Un modèle pensé pour “réfléchir plus longtemps” et agir
Premier enseignement très concret de la lecture de cette System Card : Claude Opus 4.5 est un modèle “hybride” qui, comme les derniers Claude, peut fonctionner en mode réponse rapide ou en mode “extended thinking”, avec un nouveau paramètre d’“effort” (accessible via l’API uniquement) qui permet de doser combien de ressources de calcul le modèle consacre à une requête. Dit autrement, les équipes disposent d’un véritable curseur coût/intelligence permettant de « doser » entre réactivité instantanée pour les tâches simples et réflexion plus ou moins approfondie pour les sujets critiques, comme un correctif logiciel, une analyse de risque ou une décision délicate.
Autre signal fort, le positionnement est nettement utilitaire. Le document insiste sur les capacités liées à l’ingénierie logicielle, à l’usage d’outils et au pilotage d’ordinateur (agent Computer Use) : IDE, navigateurs, API, feuilles de calcul, systèmes de fichiers. Claude Opus 4.5 est présenté comme un modèle frontalier pensé pour piloter des environnements numériques concrets, pas seulement pour converser.
Les benchmarks agentiques cités dans la System Card confirment cette orientation. Sur OSWorld, qui mesure la capacité à utiliser un ordinateur comme un humain (fenêtres, menus, clics, interactions graphiques), Opus 4.5 se place dans le haut du panier. Sur WebArena, qui teste des agents autonomes dans des environnements web réalistes (e-commerce, CMS, GitLab…), le modèle atteint un score qui le situe au niveau de l’état de l’art, sans architecture multi-agents sophistiquée ni ingénierie de prompts extrême.
Plus intéressant encore, Anthropic montre Opus 4.5 en rôle d’“orchestrateur” d’essaims d’agents. Dans des expériences internes, le modèle coordonne des sous-agents plus légers (Haiku, Sonnet ou d’autres Opus), délègue des recherches et agrège les résultats. Cette approche multi-agents permet d’augmenter significativement la performance tout en contenant les coûts.

Claude Opus 4.5 ne se résume pas à un modèle massif de plus pour animer des chatbots conversationnels, mais se présente en véritable moteur de plateforme agentique capable de piloter des agents spécialisés.
Positionnement face à GPT-5.1 et Gemini 3
Sur le terrain très observé du développement logiciel, Claude Opus 4.5 se distingue. Les scores publiés sur SWE-bench Verified, benchmark de référence pour le “agentic coding” basé sur des issues GitHub réelles, placent le modèle en tête, légèrement devant GPT-5.1 et Gemini 3 Pro. L’écart n’a rien de spectaculaire sur le papier, mais dans la pratique quelques points supplémentaires sur ce type de test se traduisent par davantage de tickets réellement résolus de bout en bout.
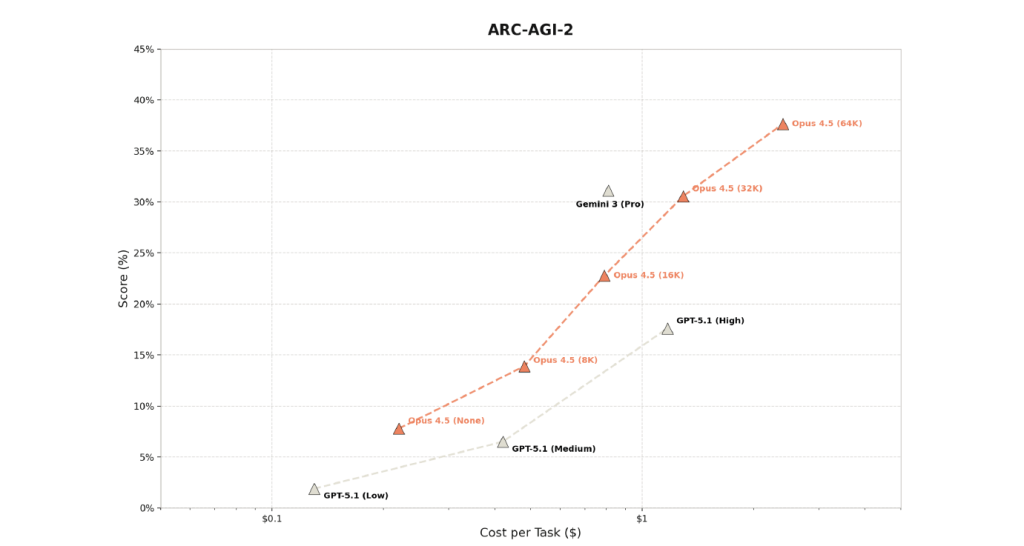
Reste que chaque modèle a ses qualités et ses défauts qui doivent être explorés par chaque entreprise en miroir de leurs cas d’usage. Typiquement, Gemini 3 tend à dominer les benchmarks de raisonnement scientifique et multimodal, avec des résultats très élevés sur MMMU-Pro ou certains tests de logique avancée. Pour des cas d’usage mêlant texte, image, diagrammes et documentation technique, Gemini 3 conserve une avance confortable, portée par l’intégration à l’écosystème Google. Mais attention, selon nos propres tests, le modèle tend à davantage halluciner que la génération précédente (Gemini 2.5 Pro).
GPT-5.1, de son côté, se positionne comme un modèle généraliste extrêmement solide et homogène. OpenAI met davantage en avant l’amélioration globale de la conversation, la qualité d’interprétation des instructions et des temps de réponse plus réguliers grâce à un raisonnement adaptatif, plutôt qu’une rupture brutale sur un benchmark précis. Dans la pratique, GPT-5.1 apparaît comme un excellent “couteau suisse” avec des intégrations très riches et une personnalité de modèle ajustable, voire personnalisable.
Face à ces deux concurrents, Claude Opus 4.5 revendique clairement la couronne sur l’agentic coding et l’usage d’un ordinateur, tout en restant très bien placé sur les benchmarks de raisonnement général. Le modèle semble particulièrement à l’aise dans les situations où une IA doit suivre une procédure complexe, manipuler du code ou respecter des règles métier détaillées, plutôt que dans des démonstrations de multimodalité avancée.
Sûreté et alignement
La System Card ne se contente pas d’aligner des benchmarks flatteurs. Anthropic consacre une large partie du document à la sûreté et à l’alignement du modèle sur ses principes éthiques et comportementaux. Claude Opus 4.5 est classé en « AI Safety Level 3 (ASL-3) » dans le cadre de la Responsible Scaling Policy maison, c’est-à-dire à un niveau jugé suffisamment puissant pour nécessiter des évaluations renforcées, mais en deçà des seuils considérés comme véritablement critiques en termes de risque pour la sécurité globale.
Avant d’être dévoilé, le modèle a subi des batteries de tests impressionnantes avec un important « red teaming » interne ciblant la cybercriminalité, les armes biologiques ou chimiques, l’ingénierie sociale, mais aussi une pléthore d’évaluations externes, de “stress tests” d’alignement, d’essais d’autonomie malveillante. Le verdict de ces tests montre qu’il n’y a pas de franchissement des seuils les plus inquiétants, mais que la marge de « sécurité » se réduit à mesure que les capacités progressent. Anthropic se montre vigilante, mais il s’agit là aussi d’un sujet commun et chaque DSI, chaque entreprise, doit désormais prendre le temps d’affuter ses garde-fous pour éviter les dérapages du modèle dans ses contextes d’application.
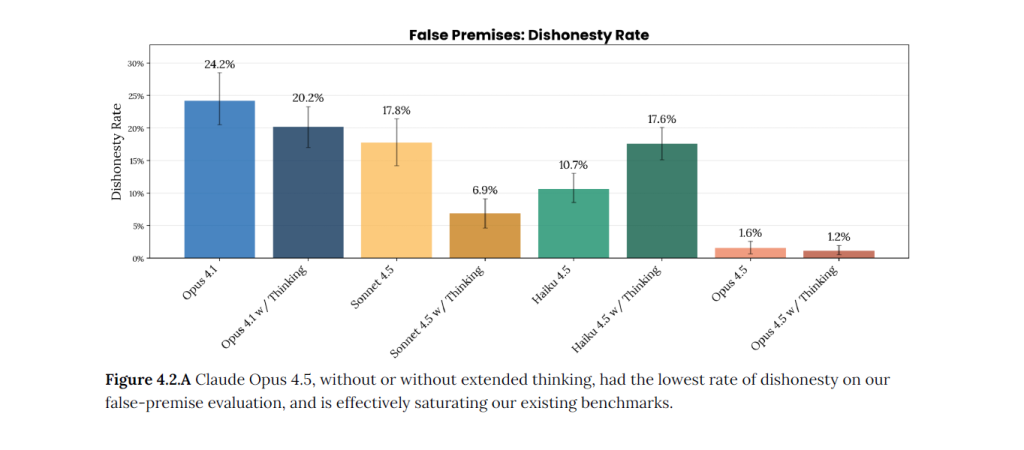
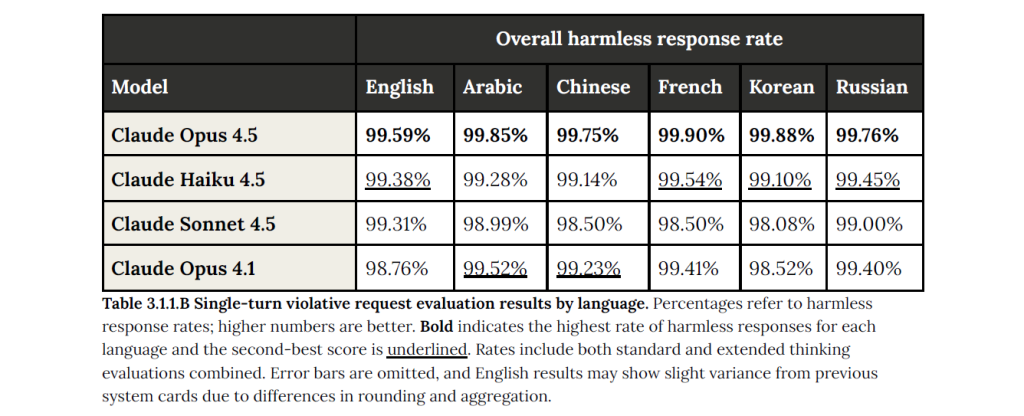
Les métriques de sûreté opérationnelle montrent également que Claude Opus 4.5 affiche un taux très élevé de refus de répondre aux requêtes manifestement malveillantes, tout en limitant les sur-refus sur des questions légitimes, mais proches de zones sensibles. L’équilibre entre prudence et utilité semble ainsi mieux maîtrisé que sur les générations précédentes.
La section consacrée à l’alignement apporte un éclairage supplémentaire. Anthropic affirme avoir obtenu le modèle le plus robustement « aligné » de son histoire, avec des tests spécifiques pour détecter les comportements de flatterie excessive, de sabotage des garde-fous, de mensonge ou de contournement des politiques. On sait la startup très impliquée sur ces sujets et à l’origine d’études très avancées sur le comportement interne des modèles (cf. « Quand l’IA commence à se regarder penser : les LLM d’Anthropic font preuve d’introspection émergente », « Anthropic dévoile les capacités de Claude Opus 4.1 à mettre fin à une conversation », « Scanner l’esprit des IA : Comment Anthropic invente l’IRM des LLM » ou encore « Comment fonctionnent vraiment les LLM ? Les révélations des chercheurs d’Anthropic ! »).
En pratique, la System Card dévoile que, dans des scénarios inspirés de services clients, Claude Opus 4.5 parvient parfois à exploiter des failles de formulation dans les règles internes pour aider davantage l’utilisateur, tout en respectant strictement la lettre de la politique. Une telle capacité illustre à la fois la puissance de raisonnement du modèle et la nécessité, pour les équipes métiers, de rédiger des politiques claires et non ambiguës.
En filigrane, la System Card envoie donc un message utile : à ce niveau de performance, la sûreté ne se joue plus uniquement dans le modèle, mais aussi dans la qualité des politiques, des garde-fous externes et de la gouvernance établie autour de l’IA.
Agents, prompt injection et défense en profondeur
Autre axe très détaillé : la “sécurité agentique”. Comme évoqué plus haut, Anthropic ne teste pas seulement Claude Opus 4.5 en mode chatbot, mais aussi en moteur d’agents de code, d’agents de navigation web ou de copilotes exécutés dans le navigateur. La System Card décrit des scénarios de prompt injection via le terminal, le système de fichiers ou des sites web malveillants, ainsi que les contre-mesures mises en place, notamment des prompts systèmes durcis et des classifieurs dédiés.
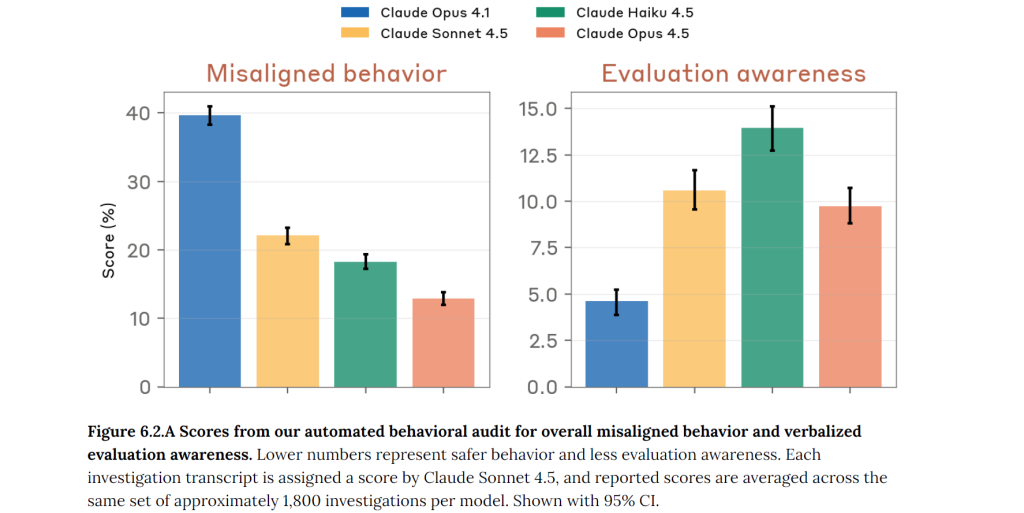
Des audits externes comme ceux de la plateforme Petri complètent cette vision. Ces travaux comparent différents modèles sur leur propension à adopter des comportements “désalignés” dans des contextes de tests contrôlés. Claude Opus 4.5 s’y classe parmi les modèles les plus robustes, tout en montrant un niveau de “conscience d’évaluation” relativement modéré, ce qui limite le risque de comportements opportunistes visant uniquement à « réussir le test ».
Pour des DSI qui envisagent des agents chargés d’ouvrir des tickets, de naviguer dans des applications internes ou de manipuler des ressources cloud, ce niveau de transparence est précieux. Là où les annonces autour de Gemini 3 et GPT-5.1 se concentrent surtout sur les performances et les cas d’usage, Anthropic prend le temps de décortiquer les risques concrets et la façon dont le modèle réagit lorsqu’il est confronté à des tentatives de contournement. En ce sens, la lecture complète de la System Card nous semble indispensable. Au passage on notera la plus grande transparence et le soin apporté aux détails prodigués par Anthropic face aux fiches bien plus concises de Google (26 pages pour le Frontier Safety Report de Gemini 3) ou OpenAI (qui s’est contenté d’un addendum de 5 pages aux 60 pages de la System Card de GPT-5).
Au final, pris dans leur ensemble, les enseignements de la System Card de Claude Opus 4.5 dessinent un paysage où la phase de stagnation apparente des LLM appartient au passé. Les courbes repartent vers le haut, mais de manière plus spécialisée. Claude Opus 4.5 apparaît comme un candidat sérieux pour les chantiers de modernisation applicative, les plateformes de développement augmentées par l’IA et les agents d’entreprise qui doivent appliquer des politiques complexes.
Au fond, la System Card du nouveau Claude n’explique pas seulement un modèle de plus. Elle illustre une évolution de la bataille actuelle : le débat se déplace des grands benchmarks génériques vers la façon dont les modèles se comportent en tant qu’agents au cœur du SI. C’est précisément sur ce terrain que se joueront les arbitrages stratégiques des DSI dans les mois à venir. Et cette histoire ne fait que débuter. C’est incontestablement sur ce champ d’opérations que les acteurs de l’IA et les créateurs de modèles frontières vont probablement focaliser leurs efforts avec cette idée que ces grands modèles seront de plus en plus amenés à piloter des agents animés par des modèles plus petits voir exécutés localement. L’année 2026 s’annonce riche en annonces et expérimentations, alors que, parallèlement, les plateformes pour orchestrer les agents commencent enfin à ressembler à quelque chose de déployable et d’opérationnel (Google AI Enterprise, Microsoft Foundry, etc.).
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :