

Newtech
CES 2026 : Du PC au Rack… La guerre des puces IA fait rage
Par Laurent Delattre, publié le 13 janvier 2026
Au CES 2026, l’IA locale redéfinit le PC et ravive le duel ARM/x86, désormais cadré par Copilot+ PC et ses exigences NPU. CPU, GPU, NPU… tout converge vers une seule idée, industrialiser l’IA. Mais la compétition se déplace vers des plateformes complètes, du poste au rack, où coûts, énergie, sécurité et exploitabilité pèsent plus lourd que la seule performance brute.
Le CES est, par vocation, un salon grand public centré sur les technologies censées améliorer et transformer le quotidien de tous. Mais, le show est aussi une source d’inspiration et de compréhension des tendances pour les DSI. Or l’édition 2026 a été plus que jamais rythmée par de multiples annonces autour des CPU et des GPU. Et par effet de bord, elle a illustré deux batailles qui ne peuvent qu’interpeler les DSI.
La première est celle qui oppose l’architecture ARM à l’architecture x86. Au point que l’on se demande déjà si l’année 2026 ne marquera pas le glas de l’historique architecture d’Intel.
La seconde montre que la compétition ne se joue plus sur les critères de « meilleur CPU » ou « GPU le plus rapide » mais sur la capacité des concepteurs de puces à imposer une plateforme complète, du PC jusqu’au rack, à même d’industrialiser les usages de l’IA alors que les contraintes de coûts, d’énergie, de sécurité et d’exploitation sont plus prégnantes que jamais dans l’agenda des DSI.
Le dernier sursaut du x86 ?
Le CES 2026 a marqué le lancement officiel des nouvelles générations de processeurs mobiles chez Intel (Core Ultra 3 family), AMD (Ryzen AI 400 Series) et chez Qualcomm (Snapdragon X2 Plus et Elite). Cette simultanéité n’est pas un hasard : sur le PC, la « barre d’entrée » de l’IA locale est désormais fixée par l’écosystème Windows et son label « Copilot+ PC » (qui exige un NPU au-delà des 40 TOPS). Les annonces du CES 2026 relèvent moins du « qui a le meilleur CPU » que du « qui coche les prérequis IA et va bien au-delà » tout en tenant les contraintes d’autonomie, de performance et de support.
Intel joue sa survie et celle du x86 avec Panther Lake
Le lancement de la famille « Intel Core Ultra Series 3 », nom de code Panther Lake, n’a pas été qu’un des temps forts du CES 2026. Il marque surtout l’une des dernières chances d’Intel de prouver que l’architecture x86 peut survivre à l’offensive ARM sur PC. Bien sûr cette architecture est encore loin d’être enterrée et le x86 conserve deux atouts structurels pour les DSI : la totale compatibilité applicative et l’inertie naturelle des parcs de machines.
Mais le CES 2026 a rendu clairement plus visible la dynamique ARM : si le Show a démontré une chose, c’est que Windows sur ARM n’est plus un pari, c’est une ligne de produits que les OEM (et non plus uniquement Microsoft) poussent désormais ouvertement comme une alternative crédible dans les flottes PC, précisément parce qu’elle promet une meilleure efficacité énergétique à performance comparable.
Ce qui met les DSI face à une question qu’ils n’ont pas eu à se poser depuis bien longtemps : « Quel niveau de fragmentation de plateformes mon SI est-il prêt à absorber, entre images système, pilotes, outillage MDM/EDR, et support long terme ? ».
La complexité de la réponse est une chance pour Intel. Mais il faut pour cela rester compétitif sur la performance, l’autonomie et les prix.
Sur le papier, le fondeur a placé la barre très haut : le Core Ultra Series 3 est présenté comme la première plateforme client construite sur Intel 18A, et comme la plus large vague d’“AI PC” de son histoire, annoncée comme devant alimenter plus de 200 designs.
« Intel 18A » c’est le nouveau procédé industriel de fabrication d’Intel, celui qui doit marquer le grand retour du fondeur et lui permettre de reprendre de l’avance sur son principal concurrent TSMC qui planche encore sur le 2 nm.

Sur le papier toujours, Intel impressionne : Jusqu’à 27 h d’autonomie, jusqu’à +60% en performance multi‑thread versus la génération Lunar Lake, jusqu’à +77% en performances de gaming.
Pourtant, en pratique, rien de ce qu’Intel a annoncé à de quoi totalement rassurer le marché. Pourquoi ? Parce que la marque nous livre une famille de processeurs gigantesque, presque illisible, où les performances n’ont rien en commun d’un modèle à l’autre. Un « Panther Lake » est une composition désagrégée de tuiles CPU, iGPU, NPU et Contrôleurs. Intel propose des tuiles CPU à 6 cœurs, à 8 cœurs ou à 16 cœurs, des tuiles iGPU à 2 cœurs, 4 cœurs, 10 cœurs et 12 cœurs, des tuiles contrôleurs à 6, à 12 ou à 20 lignes PCIe, des NPU à 46, 47, 49, 50 ou même 58 TOPS. Et le constructeur assemble ainsi à volonté les tuiles pour proposer des processeurs différents et satisfaire toutes les gammes de prix et tous les désirs des partenaires OEM. Mais cela ne simplifie nullement l’acte d’achat pour le grand public comme pour les entreprises !

Typiquement, le haut de gamme Core Ultra X9 388H diffère profondément du Core Ultra 9 386H parce que son iGPU est radicalement différent ! Celui du Ultra X9 est une vraie carte de gaming de classe ARC B390 avec ses 12 cœurs Xe-3 et ses 122 TOPS, là où l’Ultra 9 se contente d’une simple « Intel Graphics » à 4 cœurs (et 40 TOPS). Et le Core Ultra 5 322 n’a que 6 cœurs CPU (contre 16 pour le X9) et 2 cœurs iGPU ! La gamme actuelle comporte déjà 14 modèles mais d’autres (y compris des variantes spéciales OEM) sont prévus et il y aura même des modèles pour le monde de l’embarqué et modèles « non Ultra » sans NPU ! C’est complètement délirant !
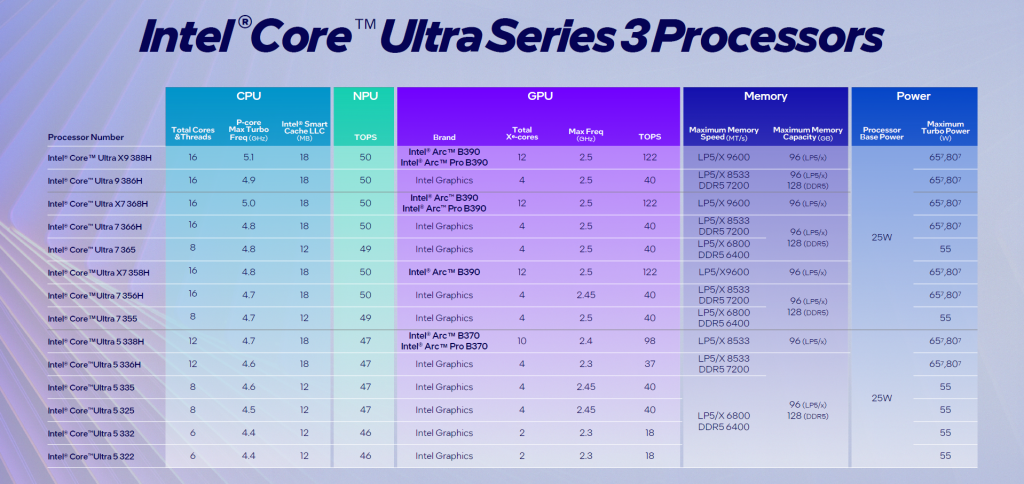
Surtout, Intel ne la joue pas franc-jeu dans ses annonces. Le fondeur compare son Ultra X9 388H à son ancien Ultra 9 288V pour expliquer les 60% d’augmentation de performance (mais il compare donc un CPU 16 cœurs avec un CPU 8 cœurs) et les 77% de performance graphiques (en comparant l’iGPU du X9 à celui de le génération « 2 », plutôt que l’iGPU de l’Ultra 9 serie 3). Et Intel se garde bien de préciser la performance mono-thread… Selon des benchs non officiels, ils ne seraient pas supérieurs à ceux de la « Serie 2 » et notablement inférieurs à ceux de l’Apple M4 et du Snapdragon X2.
Enfin, une énigme demeure et devra attendre les premiers tests indépendants. L’architecture x86 se montre autonome en réduisant très considérablement les performances. La question est donc désormais de vérifier si les 27 heures d’autonomie se traduisent aussi en bureautique et sans perte notable de performance et de réactivité. La question est posée et reste ouverte. On attend d’avoir les premières machines entre les mains pour avoir nos réponses.

Un dernier mot sur le NPU-5 de cette famille « Ultra Serie 3 ». Il est sensiblement supérieur à la génération précédente avec une performance officielle entre 46 et 50 TOPS. Mais Intel préfère jouer la carte d’une plateforme IA qui combine performance du NPU pour les besoins quotidiens et performance du GPU pour les besoins ponctuels, avec une approche très plateforme et des outils et librairies combinant le potentiel CPU/GPU/NPU.

Quoi qu’il en soit, Intel joue là une grande partie de l’avenir de sa « fonderie » (et du processus 18A) et de l’avenir de l’architecture x86, alors que presque tous les constructeurs OEM jouent désormais aussi la carte Snapdragon X2.
AMD pousse l’IA locale sur frameworks maison
On attendait l’annonce d’un processeur ARM… On a eu droit à des annonces x86 ! Avec un push du côté des Copilot+ PC et la volonté de renforcer sa position face à Intel et Nvidia du PC jusqu’au Datacenter en passant par le Gaming et les HPC !
Sur le segment PC, le fondeur insiste sur l’intégration de NPU plus puissants afin de répondre à la montée en puissance des usages d’IA locale, qu’il s’agisse d’assistants, de création de contenu ou de sécurité, tout en promettant de meilleures performances énergétiques pour les ordinateurs portables.
AMD a ainsi introduit une nouvelle gamme « Ryzen AI 400 » qui apparaît comme une itération de la série 300 sans grosse révolution et basée sur le triptyque CPU “Zen 5”, iGPU RDNA 3.5 et NPU XDNA 2. Toute la famille dispose d’un NPU 50 TOPS à l’exception du nouveau haut de gamme, le Ryzen AI 9 HX-475 doté d’un NPU de 60 TOPS !

Les modèles vont du Ryzen 5 « 430 » à 4 cœurs, 8 Threads, NPU 50 Tops et GPU AMD Radeon 840M (4 cœurs) jusqu’au Ryzen AI 9 « HX 475 » avec ses 12 cœurs, 24 Threads, NPU 60 TOPS et GPU AMD Radeon 890M (16 cœurs).
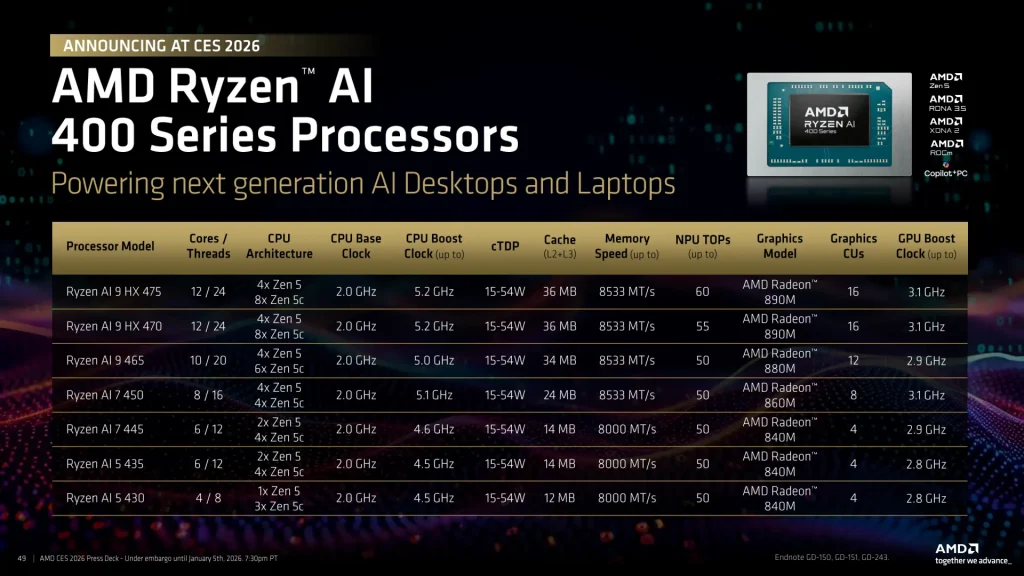
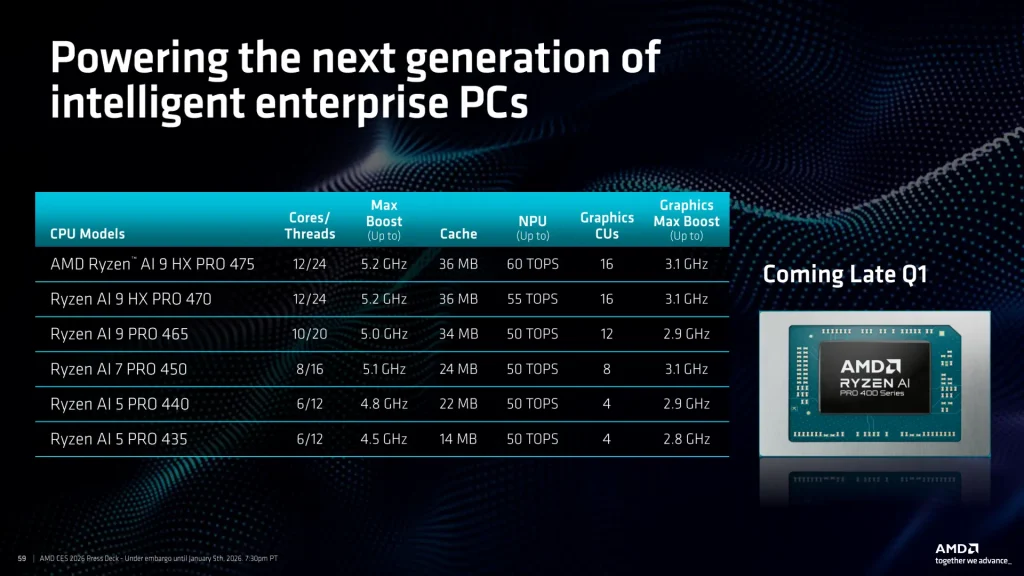
Cette série « 400 » est accompagnée d’une nouvelle série « Ryzen AI PRO 400 » destinée aux PC d’entreprise et servie par un discours très orienté sécurité et administrabilité. AMD y rattache son portefeuille AMD PRO Technologies, avec l’idée de rassurer sur des sujets qui pèsent beaucoup plus lourd que le seul niveau de performance : fonctions de sécurité au niveau matériel, protections de la mémoire et du démarrage, intégration avec les outils de gestion du poste et, surtout, promesse de stabilité de plateforme et de disponibilité dans la durée pour faciliter l’industrialisation des images, des pilotes et du support. Autrement dit, la déclinaison “PRO” vise à faire du Copilot+ PC un objet gérable à l’échelle d’un parc, et pas seulement une vitrine technologique.
Mais AMD souhaite aussi aller encore plus loin en matière de Poste de travail pour l’IA. Le Ryzen AI Max+ est la pièce maîtresse de la stratégie AMD au CES 2026 pour tous ceux qui ont besoin de travailler sur les modèles et les pipelines de l’IA. Ces puces combinent jusqu’à 16 cœurs Zen 5, 32 threads et une fréquence boost dépassant les 5 GHz, avec un GPU intégré pouvant atteindre 40 cœurs RDNA 3.5 et environ 60 téraflops de puissance de calcul. Elles intègrent également un NPU capable de 50 TOPS et se distinguent par leur capacité à allouer jusqu’à 128 Go de mémoire système au GPU, ce qui les rend adaptées à l’exécution de grands modèles d’IA et à des charges de travail lourdes. Un design à mémoire unifiée capable de nourrir à la fois le GPU et les charges IA, précisément là où les approches “CPU + iGPU classique” plafonnent sur les modèles locaux un peu ambitieux.

Ce processeur est au cœur d’un nouveau concept, réponse d’AMD au DGX Spark de NVidia. Le Ryzen AI Halo est un mini‑PC extrêmement compact (il tient dans la main) spécialement pensé pour les développeurs et data-scientists et destiné à faciliter les travaux IA en local. La machine permet l’exécution en local de modèles IA de 200 milliards de paramètres. Elle se veut idéale pour aider les entreprises dans tous les travaux de personnalisation, fine tuning et ajustements à leurs propres besoins de modèles open source.

Cette solution représente également un levier stratégique permettant à AMD de renforcer son écosystème logiciel IA dans un marché dominé par l’architecture CUDA de NVIDIA. Halo est en effet une solution développeur « clé en main », dont l’optimisation native pour l’environnement open source ROCm 7.2 inclut des modèles et applications préchargés et préconfigurés. Cette approche vise à éliminer les obstacles traditionnels qui limitaient l’utilisation de ROCm en dehors des centres de données. La version 7.2 de ROCm assure la compatibilité avec les gammes Ryzen AI 400 et AI Max+, et peut être obtenue depuis ComfyUI, la solution de création de workflows génératifs largement adoptée. AMD souligne ses efforts pour garantir une expérience IA équivalente entre Windows et Linux, notamment grâce au développement de versions PyTorch spécifiquement optimisées pour l’environnement Windows.
Qualcomm impose un peu plus son Snapdragon X2 dans les PC
Fin 2025, Qualcomm avait annoncé ses Snapdragon X2 Elite et Elite Extreme, nouveaux fleurons de son offensive pour animer les PC Windows en ARM. Ces puces destinées au haut de gamme sont désormais complétées d’une famille « Snapdragon X2 Plus » destinée à animer le milieu de gamme. Ils s’inscrivent dans la stratégie de Qualcomm de pousser en priorité l’écosystème Copilot+ PC, grappiller des parts sur Intel et AMD, et offrir une alternative plus crédible face aux Mac d’Apple.
Et l’offensive porte ses fruits. Les machines Snapdragon X ont réussi à effacer l’essentiel des incompatibilités avec l’architecture x86 (via la couche d’émulation Prism de Windows 11) tout en acquérant la réputation de machines très autonomes, très réactives, mais surtout plus fiables que les machines x86. Des qualités qui commencent à séduire les OEM de plus en plus nombreux à décliner leurs machines vedettes en technologie Qualcomm.

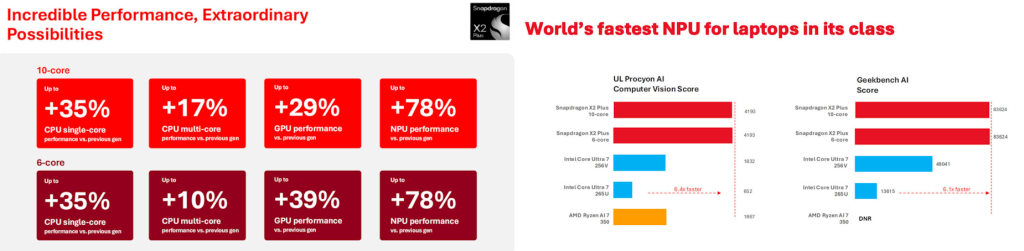
Sur le papier, le fondeur annonce des progrès sensibles par rapport à la première génération de puces Snapdragon X Plus lancée en 2024 : jusqu’à +35 % en performance CPU mono-cœur, +17 % en multi-cœur, +29 % côté GPU et jusqu’à +78 % pour le NPU. Avec une saine et réjouissante simplicité, la gamme X2 Plus se décline en deux puces : l’une jusqu’à 10 cœurs Oryon de troisième génération avec un GPU à 1,7 GHz, l’autre limitée à 6 cœurs avec un GPU à 900 MHz. Le GPU s’appuie sur une nouvelle architecture graphique Adreno significativement plus véloce que la première génération qui constituait incontestablement le point faible de la série « Plus ».
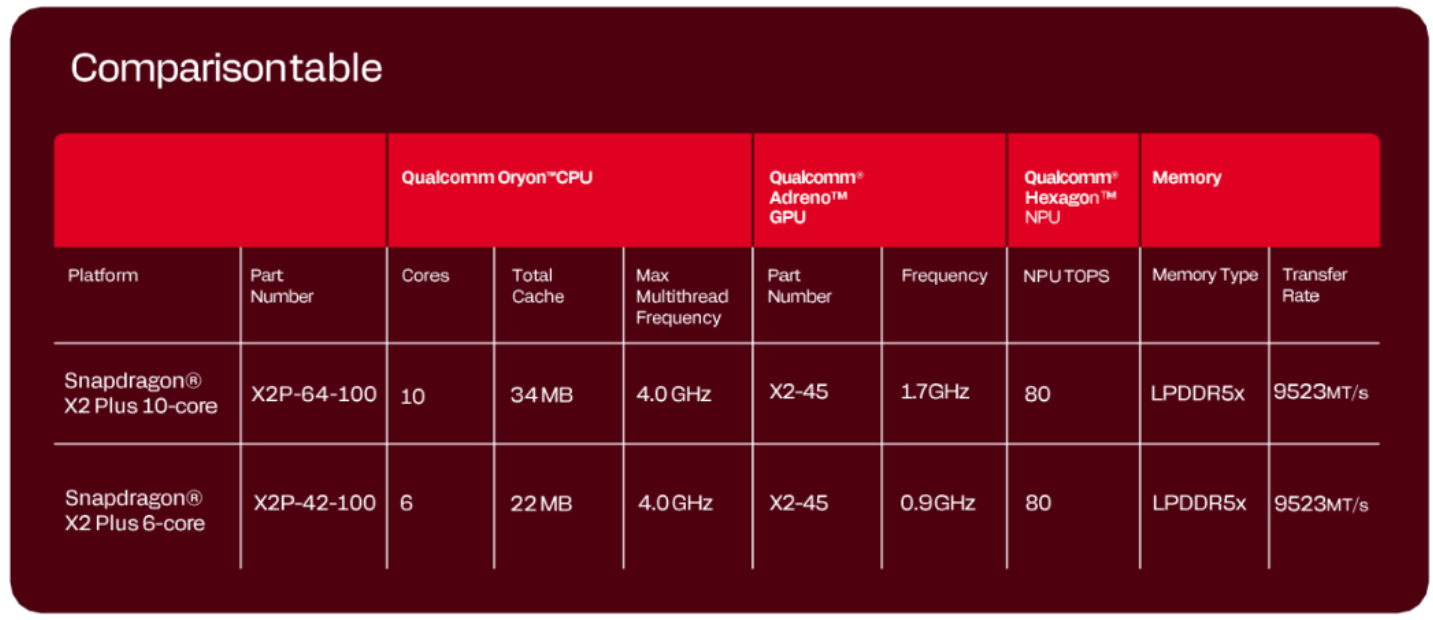
Qualcomm vente les performances de son architecture ARM « Oryon » qui n’a nullement peur de se confronter aux processeurs x86 tout en poussant son argument n°1 : un NPU annoncé à 80 TOPS (le même que celui des séries Elite et Elite Extreme), présenté comme le NPU le plus rapide dans un PC portable.
Par ailleurs, tout comme les processeurs Snapdragon X2 Elite et Snapdragon X2 Elite Extreme, les puces de milieu de gamme proposeront l’option Snapdragon Guardian, réponse de Qualcomm à la plateforme vPro d’Intel mais avec une portée plus large et un fonctionnement « always-on » inédit. Cette technologie de sécurité et de gestion à distance des PC, permet de localiser, verrouiller, mettre à jour ou même effacer un PC même lorsqu’il est éteint, hors‑ligne ou inutilisable, grâce à une connectivité cellulaire intégrée.
Il ne fait guère de doute que 2026 sera une année clé pour « Windows on ARM » et pour Snapdragon X. La plateforme a bien des atouts pour s’imposer à condition que les partenaires OEM la soutiennent vraiment et que Qualcomm fasse en sorte de soigner les rapports qualité/prix. Surtout, Qualcomm doit arriver à étendre l’utilisation de ces processeurs à d’autres formats que les PC mobiles. Le constructeur veut viser les mini-PC et les consoles portables PC mais n’a jamais vraiment réussi à finaliser de tels designs avec sa première génération.
Du PC jusqu’au Rack
Au CES 2026, Nvidia et AMD ont confirmé un glissement qui dépasse largement la guerre des performances au niveau du composant : l’IA ne se “dimensionne” plus GPU par GPU, elle s’industrialise en racks, avec une logique de chaîne complète (compute, interconnexion, réseau, sécurité, opérations) et une obsession commune, celle d’abaisser le coût du token sous contrainte énergétique.
Nvidia passe à l’ère Rubin Vera
Côté Nvidia, « Rubin » est présenté comme une plateforme et non comme un simple successeur de Blackwell. Le discours s’articule autour d’un assemblage cohérent : GPU Rubin, CPU Vera, NVLink 6 pour le scale-up, Spectrum-X/Spectrum-6 pour le scale-out (avec une trajectoire vers l’ « Ethernet Photonics »), complétés par les SuperNIC ConnectX‑9 et les DPU BlueField‑4 afin de pousser le réseau, la sécurité et l’IO vers une granularité pleinement « datacenter‑native ».
Sur le plan matériel, Nvidia met en avant des gains spectaculaires : jusqu’à 50 pétaflops en inférence NVFP4 par GPU, une bande passante mémoire HBM4 de 22 To/s, et un NVLink doublant la bande passante par GPU par rapport à Blackwell. Le CPU Vera joue un rôle central dans cette architecture : avec 88 cœurs Olympus, 176 threads, jusqu’à 1,5 To de mémoire LPDDR5X et une interconnexion NVLink‑C2C à 1,8 To/s, il est conçu pour éliminer les goulets d’étranglement d’orchestration et maintenir un taux d’utilisation GPU maximal, tout en intégrant nativement le confidential computing.

Mais la « plateforme » Rubin arrive surtout packagée sous forme de « systèmes », reflet de cette logique d’industrialisation. Nvidia propose deux approches : le rack‑scale Vera Rubin NVL72, combinant 72 GPU Rubin et 36 CPU Vera dans un ensemble refroidi par liquide, et une déclinaison plus classique HGX Rubin NVL8 destinée aux serveurs x86. Ces briques sont pensées pour s’agréger en clusters DGX SuperPod, véritables « usines d’IA » clés en main, capables d’atteindre plusieurs exaflops en FP4, avec des mécanismes avancés de résilience, de maintenance sans interruption et de sécurité à l’échelle du rack. L’objectif affiché est bien évidemment réduire drastiquement le coût du token, améliorer l’efficacité énergétique et faire passer l’IA du laboratoire à la production industrielle.

AMD muscle ses puces Instinct et lance Helios
Et AMD a immédiatement répondu à ces annonces en adoptant une stratégie très similaire. La firme a ainsi annoncé « Helios », sa première plateforme IA « rack-scale », conçue comme une brique fondatrice vers des clusters à l’échelle “yotta-scale” (l’exascale, c’est déjà ‘has-been’) et comme une réponse directe au DGX Vera Rubin NVL72 de Nvidia.
Helios combine des CPU EPYC « Venice » (Zen 6) et une densité extrême d’accélérateurs Instinct : jusqu’à 72 GPU MI455X par rack, épaulés par 18 processeurs EPYC. Ces nouveaux GPU, forts de 320 milliards de transistors (soit environ 70 % de plus que l’actuel MI355X actuel) s’appuient sur une architecture chiplet avancée (2 nm et 3 nm), 432 Go de mémoire HBM4 et un empilement 3D pour maximiser la bande passante et l’efficacité énergétique. L’ensemble est pensé pour un refroidissement liquide généralisé et une interconnexion réseau Pensando 800 GbE (Vulcano et Salina), afin de relier potentiellement des dizaines de milliers de racks sans créer de goulets d’étranglement.

En parallèle de cette cible hyperscaler assumée, AMD affine une trajectoire plus pragmatique pour les datacenters d’entreprise et les environnements souverains. Le constructeur introduit ainsi le MI440X, une déclinaison de la famille Instinct MI400 en format compact à 8 GPU, pensée pour s’intégrer facilement dans des infrastructures existantes et couvrir les besoins de training léger, de fine-tuning et d’inférence “on‑prem”. Cette nouvelle offre complète les MI430X orientés HPC et souveraineté, tout en préparant la suite : AMD tease en effet déjà la génération MI500 attendue pour 2027, basée sur l’architecture CDNA 6, une gravure en 2 nm et de la mémoire HBM4E, histoire de maintenir une pression constante sur le leader du marché et ancrer sa crédibilité face à l’accélération du cycle d’innovation IA.

Au final, ce CES 2026 aura rappelé que sur PC comme au cœur des datacenters, une guerre des puces continue de se jouer portée par l’ère de l’IA. Face à l’offensive ARM et à l’industrialisation “rack-scale”, les DSI ne peuvent plus ignorer ce combat des puces informatique et vont devoir formaliser de nouveaux profils de référence (poste standard, poste créatif, poste data/IA) avec, côté PC des engagements clairs sur la stabilité, la sécurité et la durée de disponibilité, et côté datacenter des choix d’écosystèmes sous contrainte de coûts, de sobriété énergétique et de souveraineté. 2026 s’annonce comme un premier véritable test de maturité « IA » pour les fournisseurs comme pour des organisations désormais amenées à piloter à échelle industrielle la complexité de l’IA sans perdre la maîtrise.
À LIRE AUSSI :
À LIRE AUSSI :











