
Data / IA
GTC 2026 : NVIDIA peaufine son usine à tokens pour l’entreprise agentique
Par Laurent Delattre, publié le 19 mars 2026
À la GTC 2026, NVIDIA a déplacé le débat de la puissance brute vers l’économie du token. Avec Vera Rubin, Dynamo et Agent Toolkit, le groupe redéfinit le datacenter comme une usine d’inférence où se jouent simultanément coût unitaire, souveraineté, sécurité et orchestration hybride. Voici ce que les DSI doivent absolument retenir de cet évènement marquant.
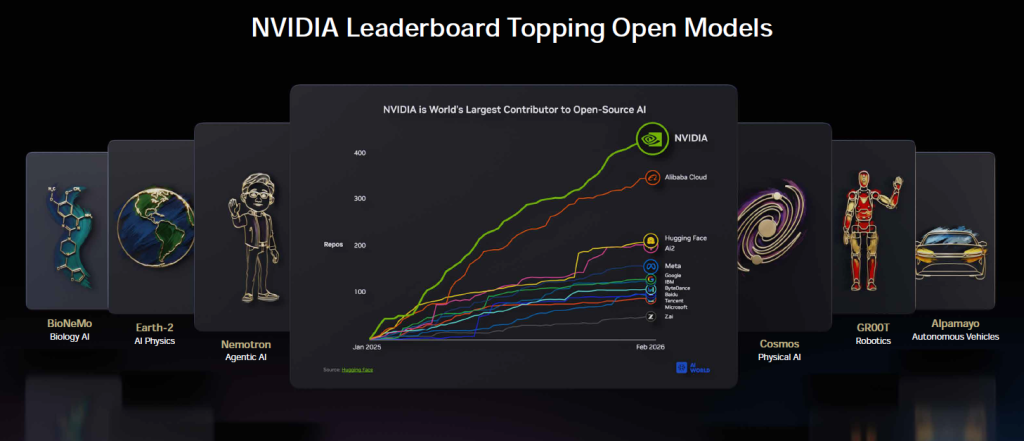
Si NVIDIA est la société la plus valorisée au monde et domine de la tête et des épaules le marché mondial de l’IA d’entreprise, ce n’est pas uniquement parce que ses GPU motorisent les principaux modèles génératifs. C’est surtout parce qu’elle a su imposer à la fois des designs matériels pour intégrer des usines IA dans les datacenters d’entreprise et une plateforme logicielle complète et hybride « NVIDIA Enterprise AI » pour déployer l’IA, ses modèles, ses garde-fous, ses outils à l’échelle dans les organisations et dans le Cloud. Une plateforme composée de briques comme NIM, NeMo, Nemotron, que l’on retrouve en fondations de bien des plateformes clés en main proposées par HPE, Dell, Nutanix, etc.
À la GTC 2026, NVIDIA n’a ainsi pas simplement déroulé une nouvelle feuille de route matérielle. Le groupe a surtout tenté d’imposer une nouvelle grille de lecture du SI : le datacenter n’est plus un entrepôt de données ni même un simple cluster GPU, c’est une usine à tokens. Toute l’architecture annoncée, de Vera Rubin à Dynamo, de BlueField-4 STX à Agent Toolkit, vise le même objectif : transformer plus vite, plus sûrement et à moindre coût des watts en inférence utile, puis cette inférence en agents et, demain, en robots. C’est moins une conférence sur les puces qu’un manifeste sur l’industrialisation de l’IA.
Et si NVIDIA s’est évertué à démontrer sa maîtrise des puces et technologies matérielles de l’IA, le groupe a surtout exposé sa main-mise sur l’ensemble de l’IA Factory, cette usine à fabriquer et à traiter du token, nouvelle unité économique de l’ère agentique. Une emprise sur toutes les couches matérielles (cluster de calcul, réseau dopé pour l’IA, stockage adapté à l’IA) avec sa plateforme « Vera Rubin » mais aussi sur toutes les couches logicielles et middlewares, avec des couches fondamentales comme Dynamo, Agent Toolkit, NemoClaw et autres pour permettre très concrètement aux entreprises de piloter le coût par token de leurs IA et orchestrer la multiplicité des agents (ces intelligences autonomes qui consomment et génèrent du token à foison).
NVIDIA n’a pas tant cherché à démontrer sa suprématie technologique qu’à basculer vers une économie du token industrialisé et s’aligner sur les préoccupations très concrètes des DSI : coût unitaire de l’inférence, orchestration des ressources, sécurité des agents, arbitrage cloud/on-prem/hybride, et dépendance croissante à un fournisseur qui monte toute la chaîne de valeur.

Toutes les annonces officielles de cette GTC 2026 vont dans ce sens : NVIDIA parle de POD-scale systems, d’AI factories, de souveraineté, de coût par token, d’OS d’inférence et de garde-fous de sécurité pour les agents. Bref, NVIDIA veut fournir l’infrastructure complète du SI agentique et ne laisser aucun boulevard libre à la concurrence… du datacenter au cloud, de l’automobile au robot humanoïde, des parcs Disney jusque dans l’espace…
Voici, dans le détail, ce qu’il faut retenir des grandes annonces.
Vera Rubin : plus qu’un superchip, un supercalculateur éclaté en racks
La première idée forte de cette GTC est bien là : « Vera Rubin » n’est pas une superpuce, c’est une plateforme matérielle complète qui comprend sept puces (Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, Spectrum-6 Ethernet Switch, et le tout nouveau Groq 3 LPU), cinq racks spécialisés (NVL72 GPU, Vera CPU, Groq 3 LPX, BlueField-4 STX stockage, Spectrum-6 SPX Ethernet) et un superordinateur intégré. Une façon d’enterrer définitivement la vieille lecture qui comparait encore l’IA à coups de GPU unitaires. Chez NVIDIA, la concurrence ne se joue plus puce contre puce, mais architecture complète contre architecture complète. L’objectif est de couvrir chaque phase de l’IA, du pré-entraînement au post-entraînement, du test-time scaling à l’inférence agentique en temps réel.

« Vera Rubin est un bond générationnel conçu pour alimenter chaque phase de l’IA » explique ainsi Jensen Huang, le CEO de NVIDIA en ouverture de conférence. « Le point d’inflexion de l’IA agentique est arrivé, et Vera Rubin lance le plus grand chantier d’infrastructure de l’histoire. »
Vera remet le CPU au centre, mais pas pour les raisons d’hier
La surprise la plus intéressante de cette GTC n’est peut-être pas le GPU Rubin, déjà longuement présenté précédemment, mais étrangement le CPU Vera. NVIDIA le présente comme le premier processeur conçu nativement pour l’ère de l’IA agentique et du reinforcement learning.
Basé sur l’architecture ARM, Vera offre deux fois l’efficacité énergétique et 50 % de performances en plus par rapport aux CPU traditionnels à l’échelle du rack.
Car, oui, NVIDIA compte bien commercialiser Vera comme un CPU « autonome ». Il a déjà prévu de l’intégré au sein de « Vera CPU Rack ». Chacun de ces racks embarque 256 CPU Vera avec refroidissement liquide afin de fournir une base dense et synchronisée aux environnements CPU qui testent, valident, pilotent les outils et exécutent le « travail latéral » des agents.

« L’IA a besoin de CPU pour l’utilisation d’outils, et le CPU Vera a été conçu exactement pour ce point d’équilibre » justifie Jensen Huang. Autrement dit, l’agentique redonne un rôle stratégique au CPU, non plus comme simple compagnon d’un GPU dominant, mais comme chef d’orchestre des environnements, des navigateurs, des outils, du code et des vérifications. C’est une mauvaise nouvelle pour les fournisseurs x86 : NVIDIA ne veut plus seulement l’accélérateur principal, il veut aussi le plan de contrôle de l’usine. Et les partenaires de déploiement (Alibaba Cloud, ByteDance, Meta, Oracle, Dell, HPE, Lenovo, Supermicro) signalent que Vera s’impose déjà comme le nouveau standard CPU des charges IA.
« Nous ne pensions jamais vendre des CPU de façon autonome. Et voilà que nous en vendons beaucoup. C’est déjà assurément une activité de plusieurs milliards de dollars pour nous. Nos architectes CPU ont conçu un processeur révolutionnaire » a ainsi lancé Jensen Huang, confirmant au passage que CPU Vera et racks Vera étaient effectivement entrés en production.
NVidia avait déjà au travers de ces puces « GH100 », « GH200 », « GB200 », « GB300 » intégrant le CPU « Grace » (prédécesseur de Vera) beaucoup contribué à faire grimper en flèche les parts de marché d’ARM dans les datacenters et les HPC. Les annonces autour de Vera sont donc une dure nouvelle pour Intel et AMD.
Rubin et Rubin Ultra : la puissance GPU à l’échelle du POD
Le GPU Rubin constitue le cœur de calcul de la plateforme. Avec ses 288 Go de RAM HBM4, ses 22 To/sec de bande passante mémoire, ses 50 PFLOPS en inférence NVFP4 et 35 PFLOPS en training, Rubin apporte surtout un saut d’efficience pour l’IA de raisonnement et l’inférence agentique, avec jusqu’à 10x moins de coûts par token et 10 fois plus de débit d’inférence par Watt mais aussi, sur certains modèles MoE, jusqu’à 4x moins de GPU nécessaires à l’entraînement.
Un GPU que NVIDIA présente presque systématique dans sa configuration rack NVL72 qui associe 72 GPU Rubin et 36 CPU Vera connectés par NVLink 6, avec des SuperNIC ConnectX-9 et des DPU BlueField-4.

Rubin Ultra, lui, apparaît surtout comme la preuve que NVIDIA veut maintenir cette cadence annuelle et empêcher tout rattrapage. Rapidement évoqué par Jensen Huang, il intègrera un nouveau rack « Kyber » qui connectera 144 GPU dans un seul domaine NVLink.

Le CEO de NVIDIA a confirmé que des « milliers de systèmes Vera Rubin par semaine » sortaient déjà de production laisse entrevoir une montée en charge industrielle que ni AMD ni Intel ne semblent pouvoir égaler à cette échelle intégrée. Et Satya Nadella, le CEO de Microsoft, a confirmé que des systèmes Vera Rubin étaient déjà en phase de validation sur le cloud Azure.
Groq 3 LPU/LPX : l’inférence à basse latence entre dans l’usine NVIDIA
L’intégration du Groq 3 LPU (Language Processing Unit) est l’une des autres grandes surprises de cette GTC 2026. NVIDIA a acquis l’équipe derrière les puces Groq (rien à voir avec l’IA Grok et xAI) l’an dernier et licencié la technologie pour créer un processeur déterministe à flux de données statique, compilé entièrement en logiciel, conçu exclusivement pour l’inférence des LLM.

Bien des acteurs du marché estiment qu’il existe une alternative aux GPU quand on parle d’inférence. Et certains y ont vu, à l’instar de Groq, une opportunité. Que NVIDIA n’a pas laissé filé. Et c’est l’une des grandes leçons de la GTC 2026. NVIDIA se passionne désormais pour l’inférence. Jensen Huang l’a martelé durant sa keynote : « L’inférence est le summum de la difficulté. L’inférence est extrêmement difficile. Elle est aussi extrêmement importante, parce que c’est elle qui génère vos revenus. »
La phrase est tout sauf anodine. En réalité toute la conférence GTC 2026 découle de cette remarque. Quand l’IA devient service continu, l’enjeu n’est plus seulement de savoir entraîner un gros modèle : il est de servir les bons tokens, au bon prix, à la bonne vitesse, pour le bon niveau de service.
Et pour tous les cas d’usage où les racks à GPU « NVL72 » se montrent inadaptés, NVIDIA dégaine son rack « Groq 3 LPX » ! Il embarque 256 processeurs Groq 3 LPU avec 128 Go de SRAM on-chip et 640 To/s de bande passante de scale-up. Associé à Vera Rubin NVL72, l’ensemble promet un débit d’inférence jusqu’à 35x supérieur par mégawatt. Le principe est celui de l’inférence désagrégée : le prefill et l’attention du décodage se font sur Vera Rubin (qui dispose de la mémoire massive pour le KV cache), tandis que la génération de tokens dans le feed-forward network est déchargée sur les puces Groq. Les deux processeurs travaillent en couplage étroit, pilotés par l’OS Dynamo (cf plus loin).

Une façon pour NVIDIA de reconnaître que le GPU généraliste n’est pas optimal partout. « Optimiser pour un haut débit et optimiser pour une faible latence sont en réalité des ennemis l’un de l’autre » explique ainsi Jensen Huang. Avec ses racks Groq LPX, le groupe transforme une faiblesse potentielle en avantage systémique et intègre l’ultra-faible latence dans sa propre pile. Fermant au passage ce qui aurait pu être une autoroute pour la concurrence.
NVLink 6 Switch : le tissu nerveux de l’usine IA
Il n’y a pas d’infrastructure de l’IA sans interconnexion et sans réseau adapté. Et l’IA agentique déplace la douleur. Le problème n’est plus seulement la puissance brute : c’est la circulation interne des contextes, du KV cache, des appels outils, des accès mémoire et du trafic est-ouest entre racks.
D’où la nécessité de passer à de nouvelles technologies.
Le Switch NVLink 6 est la sixième génération du système de commutation scale-up propriétaire de NVIDIA. Complètement refroidi par liquide, il permet de connecter jusqu’à 72 GPU (ou 144 avec Rubin Ultra et le rack Kyber) en un seul domaine NVLink cohérent. Ce n’est ni Ethernet, ni InfiniBand : c’est un tissu interne dédié qui offre une bande passante et une latence impossibles à atteindre avec les standards ouverts actuels. Or c’est précisément ce qui explique le bond de 10x annoncé avec Vera Rubin dans les tiers d’inférence les plus rentables.

« C’est la sauce secrète. Nous sommes aujourd’hui la seule entreprise au monde à avoir construit le système de commutation scale-up de sixième génération. Et c’est incroyablement difficile à faire » se gargarise Jensen Huang. Avec NVLink 6, NVIDIA ne vend pas un bus plus rapide, le constructeur revendique un monopole d’intégration sur le scale-up de l’IA agentique !
ConnectX-9 SuperNIC : le pont vers le monde extérieur
Le SuperNIC ConnectX-9 est le contrôleur réseau de nouvelle génération qui équipe chaque nœud Vera Rubin. Alimenté par le CPU Vera, il gère la connectivité Ethernet et InfiniBand vers l’extérieur du POD (scaling horizontal), tandis que NVLink gère l’intérieur (scaling vertical). Associé au réseau Spectrum-X Ethernet ou Quantum-X800 InfiniBand, le nouveau CX-9 réalise un couplage réseau à très haut débit tout en assurant que l’utilisation GPU reste haute même sur des clusters de plusieurs milliers de GPU.
Spectrum-6 SPX : l’Ethernet pour l’ère IA
L’interconnexion au sein d’un rack est fondamentale. Mais la connexion inter-rack ne l’est pas moins. L’IA est probablement l’un des workloads les plus éclatés par nature. Et là encore, NVIDIA ne veut laisser à personne la prise de contrôle d’une pièce aussi stratégique. Alors, pour prendre les devants, et servir l’IA à la vitesse maximale imaginable, NVIDIA remplace les électrons par les photons !
Le switch Spectrum-6 est le premier switch Ethernet en production avec co-packaged optics (CPO), une technologie développée conjointement avec TSMC sous le nom de COOP.
« Voici le premier switch CPO au monde. Il est en pleine production. Les optiques arrivent directement sur cette puce. Les électrons sont traduits en photons et connectés directement au silicium. Nous avons inventé le process avec TSMC. Nous sommes les seuls en production aujourd’hui » se félicite Jensen Huang.

Les photons sont générés directement sur le silicium du switch, éliminant les modules optiques traditionnels. Le rack SPX Ethernet héberge 256 nœuds refroidis par liquide. Pour un DSI, Spectrum-X représente l’alternative Ethernet au verrouillage InfiniBand tout en restant dans l’écosystème NVIDIA.
NVIDIA met en avant jusqu’à 5 fois plus d’efficacité optique et 10 fois plus de résilience que les transceivers enfichables traditionnels. Là encore, le discours est clair : la bataille de l’IA agentique se gagnera autant dans les interconnexions que dans les FLOPS.
BlueField-4 DPU et STX : le stockage devient AI-natif
Le DPU BlueField-4 combine un CPU Vera et un SuperNIC ConnectX-9 dans un seul composant, posant les fondations du rack BlueField-4 STX, une infrastructure de stockage AI-native qui étend la mémoire GPU de façon transparente à travers le POD.
Car oui, l’IA se montre exigeante sur le stockage et NVIDIA ne pouvait laisser la main non plus dans ce secteur. Car pour le groupe, à l’ère de l’IA agentique, le stockage n’est plus un silo séparé du calcul IA, il en devient une extension fluide.
« 100 % de l’industrie mondiale du stockage nous rejoint sur ce système. Et la raison, c’est qu’ils voient exactement la même chose : le système de stockage va être complètement réinventé » assure Jensen Huang.

L’infrastructure STX est optimisée pour conserver et restituer le KV cache des grands modèles et des workflows agentiques. Le groupe promet jusqu’à 5 fois plus de débit de tokens, jusqu’à 4 fois plus d’efficacité énergétique et 2 fois plus de rapidité d’ingestion de données. Ce n’est pas un détail de tuyauterie. C’est une tentative de capter le marché naissant de la mémoire contextuelle, là où se joueront une partie de la cohérence, de la personnalisation et de la fluidité des agents longue durée.
Des racks spécialisés et un assemblage à l’échelle du super POD
Vous l’aurez compris aux annonces ci-dessus, l’approche « Vera Rubin » de NVIDIA consiste à proposer cinq types de racks spécialisés (GPU, CPU, LPU, stockage, Ethernet) qui s’assemblent en PODs, puis en super POD, grâce au design de référence DSX (AI Factory Reference Design).
« Ce qui prenait deux jours à installer se fait maintenant en deux heures. Incroyable. Le temps de cycle de fabrication va diminuer de façon spectaculaire » s’émerveille Jensen Huang.
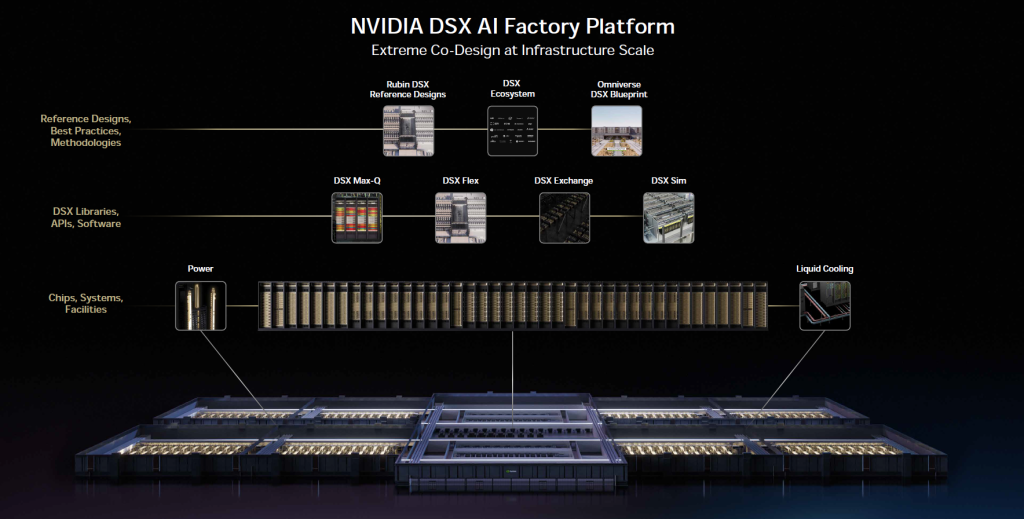
Chaque POD bénéficie d’un système de câblage structuré, de connecteurs blind-mate, le tout refroidi par eau chaude à 45°C, libérant la puissance de refroidissement du datacenter pour le calcul. NVIDIA publie également un blueprint Omniverse DSX Digital Twin pour simuler l’usine IA avant de la construire.
Avec plus de 80 partenaires et une chaîne d’approvisionnement capable de produire des milliers de systèmes par semaine, NVIDIA atteint une échelle de production qui rend très difficile pour tout concurrent de proposer une offre aussi intégrée. Le risque pour les entreprises est néanmoins évident clair : la simplicité d’intégration masque un verrouillage croissant de toute la chaîne de valeur.
« Quand nous pensons Vera Rubin, nous pensons au système tout entier. Verticalement intégré, complètement avec le logiciel. Étendu de bout en bout. Optimisé comme un seul système géant » confirme Jensen Huang.
Ce glissement est crucial. Il nous rappelle que la valeur ne se situe pas au niveau du composant, mais au niveau du couplage entre calcul, mémoire, stockage, réseau, énergie, refroidissement et logiciel d’orchestration. C’est exactement là qu’AMD, Intel ou même les hyperscalers auront le plus de mal à répliquer rapidement à l’offre de NVIDIA. Car, bien évidemment, NVIDIA prépare la même emprise sur toute la stack logicielle de l’IA d’entreprise.

Orchestrer l’usine de l’IA agentique
Une usine IA n’est pas que du hardware. Il lui faut des piles logicielles et des modèles spécialement optimisés. NVIDIA le sait et dispose déjà d’une plateforme logicielle redoutable avec « Enterprise AI » : NIM pour l’inférence optimisée, NeMo pour l’entraînement et le fine-tuning, Nemotron pour les modèles ouverts, le tout distribué via chaque cloud majeur et chaque constructeur de serveurs (Dell, HPE, Lenovo) et de couches d’infrastructure (Nutanix, VMware). À GTC 2026, trois annonces logicielles marquent un nouveau cap.
Dynamo 1.0 : l’« OS d’inférence » qui change la donne
C’est probablement l’annonce la plus sous-estimée de cette GTC 2026. Dynamo 1.0 est un logiciel open source qui se positionne comme le « système d’exploitation distribué » des usines IA. Tout comme l’OS d’un ordinateur coordonne matériel et applications, Dynamo orchestre les ressources GPU et mémoire à travers le cluster pour alimenter les charges IA complexes. Concrètement, Dynamo découpe le travail d’inférence entre GPU en ajoutant un « contrôle du trafic » intelligent et la capacité de déplacer les données entre GPU et stockage moins coûteux, réduisant le gaspillage et contournant les limites mémoires. Il sait même aiguiller les requêtes longues vers les GPU qui détiennent déjà le bon « court terme » mémoire.
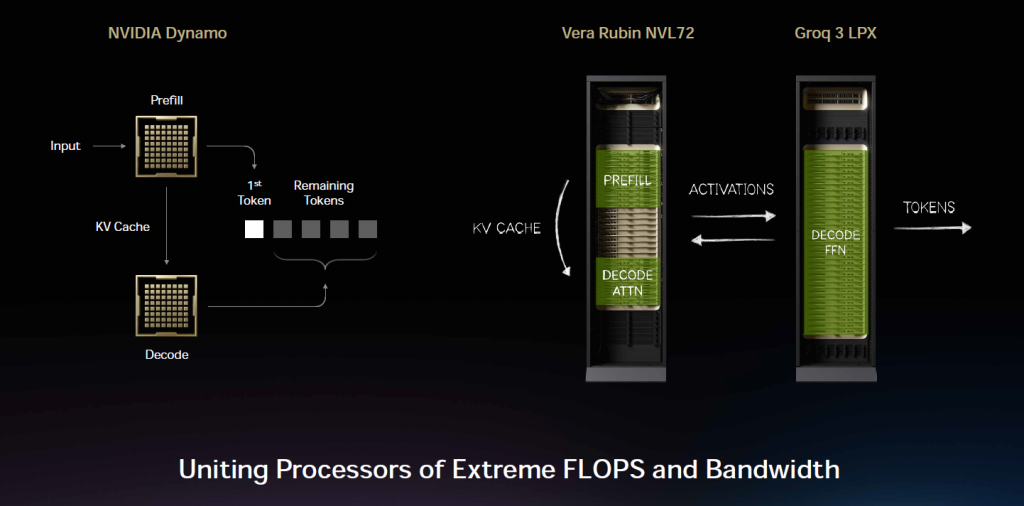
« L’inférence est le moteur de l’intelligence, qui alimente chaque requête, chaque agent et chaque application. Avec NVIDIA Dynamo, nous avons créé le tout premier ‘système d’exploitation’ pour les usines IA. L’adoption rapide à travers notre écosystème montre que cette prochaine vague d’IA agentique est là, et NVIDIA l’alimente à l’échelle mondiale » explique Jensen Huang. Officiellement, NVIDIA affirme que Dynamo peut augmenter jusqu’à 7 fois les performances d’inférence de Blackwell, tout en réduisant le coût du token et en augmentant l’opportunité de revenus.
NVIDIA dominait surtout par CUDA, par ses bibliothèques et par la cohérence de son hardware. Avec Dynamo, le groupe tente de verrouiller le niveau d’abstraction qui arbitrera demain la valeur économique du cluster. Ce que VMware a représenté pour la virtualisation, ce qu’OpenShift représente pour des infrastructures conteneurisées, Dynamo ambitionne de le devenir pour l’inférence à grande échelle dans les AI Factories.
Dynamo est open source, certes, mais il est optimisé pour les GPU NVIDIA et TensorRT-LLM.
Dès lors le danger, pour les DSI, n’est pas seulement le verrouillage technologique : c’est aussi le verrouillage opérationnel. Une fois que le bon routage de mémoire, de GPU, de stockage et de latence dépend du runtime NVIDIA, sortir de l’écosystème devient mécaniquement plus coûteux et laborieux. NVIDIA repositionne ainsi l’inférence non pas comme un problème matériel mais comme un problème d’exploitation, ce qui lui confère un rôle analogue à celui de VMware dans la virtualisation : invisible, indispensable, et extrêmement difficile à remplacer. On l’a bien vu depuis que l’hyperviseur a été racheté par Broadcom.
Agent Toolkit, OpenShell et AI-Q : NVIDIA capte la couche d’exécution des agents
Et bien évidemment, NVIDIA ne compte pas s’arrêter à « faire tourner des modèles ». Avec Agent Toolkit, l’entreprise veut capter la couche d’exécution des agents IA dans l’entreprise, en y ajoutant sécurité, confidentialité, pilotage des accès et intégration dans les workflows. Agent Toolkit comprend des modèles ouverts (Nemotron), des agents ouverts (AI-Q), des compétences ouvertes (cuOpt) et un runtime ouvert baptisé OpenShell.
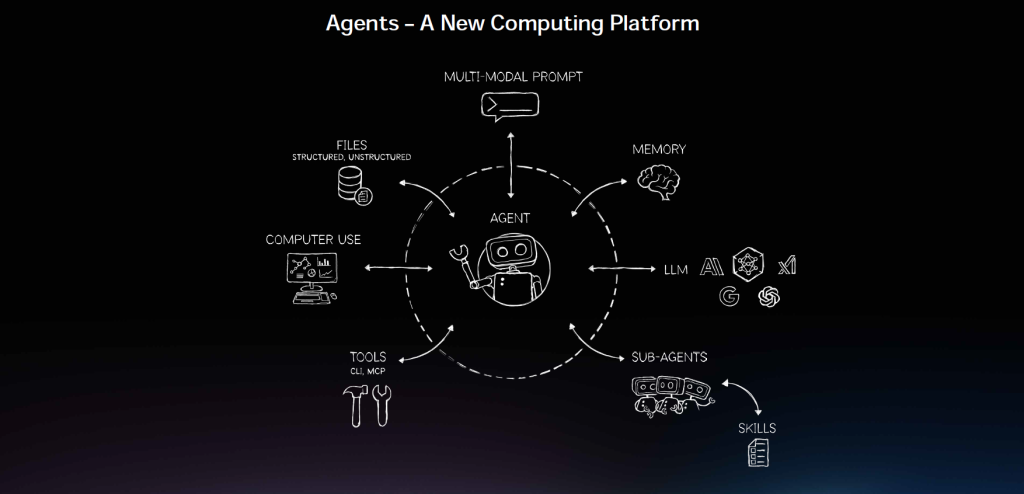
OpenShell est la brique clé de l’édifice agentique : c’est un runtime open source qui impose des garde-fous de sécurité, de réseau et de confidentialité aux agents autonomes (« claws » dans la terminologie NVIDIA). Il fournit un bac à sable isolé où les agents peuvent agir de manière productive tout en respectant des politiques définies. NVIDIA collabore déjà avec Cisco AI Defense, CrowdStrike, Google, Microsoft Security et TrendAI pour rendre OpenShell compatible avec leurs outils de cybersécurité.
De son côté, AI-Q est un blueprint d’agent qui utilise une architecture hybride : modèles frontier exécutés dans le cloud pour l’orchestration, modèles ouverts Nemotron exécutés localement pour la recherche et le RAG, réduisant les coûts de requête de plus de 50 % tout en atteignant le premier rang des classements DeepResearch Bench.
« Claude Code et OpenClaw ont déclenché le point d’inflexion des agents, en étendant l’IA au-delà de la génération et du raisonnement, vers l’action. Les employés seront démultipliés par des équipes d’agents frontier, spécialisés et sur mesure qu’ils déploieront et géreront. L’industrie du logiciel d’entreprise va évoluer vers des plateformes agentiques spécialisées, et l’industrie IT est au bord de sa prochaine grande expansion » affirme Jensen Huang.
Cela ne signifie pas que NVIDIA remplacera SAP, Salesforce ou ServiceNow. Cela signifie que le groupe veut fournir la couche basse qui standardise la manière dont ces éditeurs exécuteront leurs futurs agents. L’analogie n’est pas celle d’un concurrent frontal ; c’est celle d’un fournisseur de centre de gravité. Les partenariats déjà annoncés sont éloquents : Adobe (workflows créatifs et marketing agentiques), SAP, Salesforce, ServiceNow (automatisation des processus métier), Siemens et Cadence (agents de conception semi-conducteur), Synopsys, Red Hat, Atlassian (Jira, Confluence), Box, Cohesity, CrowdStrike… L’offensive vise directement les briques applicatives de l’entreprise. NVIDIA ne fournit plus seulement le moteur d’inférence : il fournit l’usine à agents et les garde-fous qui vont avec.
Cette stratégie positionne NVIDIA en concurrent direct des plateformes d’orchestration d’agents comme celles de Microsoft (Copilot Studio, Agent 365) ou Salesforce (Agentforce). Différence clé : NVIDIA mise sur l’open source et l’infrastructure, pas sur l’interface utilisateur. C’est un jeu de couche basse qui vise à rendre le middleware NVIDIA incontournable, quel que soit l’orchestrateur choisi en surface.
NemoClaw : NVIDIA industrialise la frénésie OpenClaw
NemoClaw est peut-être l’annonce la plus opportuniste, mais aussi l’une des plus intelligentes. En substance, NVIDIA s’approprie l’engouement OpenClaw et lui ajoute ce qui manque pour l’entreprise : isolation, politique, confidentialité, routage et modèles. Au passage, l’annonce illustre aussi la grande réactivité de NVIDIA et la force de sa plateforme.
OpenClaw, le projet open source de Peter Steinberger qui permet à chacun de créer ses propres agents IA autonomes (les « claws »), est devenu le projet open source à la croissance la plus rapide de l’histoire. Jensen Huang ne s’y est pas trompé : « OpenClaw a ouvert la prochaine frontière de l’IA à tout le monde. Mac et Windows sont les systèmes d’exploitation de l’ordinateur personnel. OpenClaw est le système d’exploitation de l’IA personnelle. C’est le moment que l’industrie attendait, le début d’une nouvelle renaissance du logiciel. »
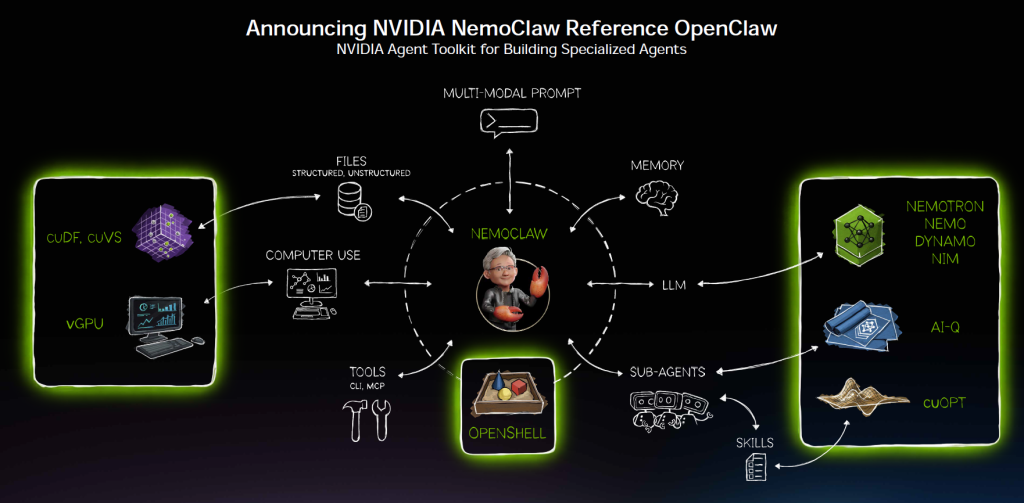
L’installation s’effectue en une commande depuis OpenShell et y appose la couche NVIDIA (modèles Nemotron, runtime OpenShell, garde-fous de sécurité et de confidentialité) pour rendre les agents autonomes plus fiables et plus déployables du cloud à l’on-prem.
Le résultat : des agents autonomes « toujours actifs » qui peuvent tourner sur n’importe quelle plateforme dédiée – PC GeForce RTX, stations RTX PRO, DGX Station, DGX Spark – avec un mélange de modèles locaux (pour la confidentialité) et de modèles frontier dans le cloud (pour la puissance), orchestré par un routeur de confidentialité.
« OpenClaw a, en substance, open sourcé le système d’exploitation des ordinateurs agentiques » ajoute Jensen Huang. « Chaque entreprise dans le monde doit désormais avoir une stratégie OpenClaw et une stratégie pour les systèmes agentiques. Clairement, l’évènement OpenClaw ne doit pas être sous-estimé. Il est aussi important que HTML, aussi important que Linux ».
L’analogie avec Linux, HTML ou Kubernetes est évidemment hyperbolique, et il faut la lire comme telle. Mais elle dit aussi quelque chose de très juste : les entreprises commencent à comprendre qu’elles n’achèteront pas seulement des modèles, mais aussi des cadres d’exécution pour des agents capables d’accéder à des données sensibles, d’exécuter du code et de communiquer vers l’extérieur.
NVIDIA a vu le vide immédiatement : avec NemoClaw et OpenShell, le groupe tente de transformer une solution communautaire enthousiaste mais hautement risquée en une version acceptable par les RSSI et les DSI. Ce qui manque encore, en revanche, c’est une intégration native avec les IAM d’entreprise (Active Directory, Okta), un véritable framework d’audit et de conformité réglementaire (RGPD, AI Act) et bien évidemment une vraie neutralité multi-plateformes. NVIDIA se dit ouvert et l’est réellement côté frameworks et modèles. Il l’est beaucoup moins dès qu’il s’agit du runtime optimal, du réseau optimal, du stockage optimal et, in fine, de l’infrastructure optimale. C’est précisément là que se loge sa puissance.
Industrialiser l’IA industrielle
Mais la stratégie NVIDIA ne se cantonne pas à l’IT classique. Elle déborde déjà largement au-delà, vers l’univers industriel.
Les annonces sur la Physical AI, Omniverse, Cosmos et les partenariats industriels prouvent que NVIDIA veut devenir la colonne vertébrale des environnements de conception, simulation, fabrication et robotique.
Cadence, Dassault Systèmes, PTC, Siemens et Synopsys construisent des agents IA alimentés par NVIDIA pour planifier, optimiser et vérifier des workflows complexes de conception de puces et de systèmes. FANUC, Honda, JLR, Mercedes-Benz, PepsiCo, Samsung, TSMC utilisent déjà CUDA-X et les logiciels industriels accélérés NVIDIA pour leur conception, leur ingénierie et leur fabrication.
« L’aube d’une nouvelle révolution industrielle est arrivée, où l’IA physique et les agents IA autonomes réinventent fondamentalement la façon dont le monde conçoit, ingénierie et fabrique » avertitJensen Huang. « En unissant notre écosystème mondial de géants du logiciel, de fournisseurs cloud et d’OEM, NVIDIA délivre une plateforme de calcul accéléré full-stack qui permet à chaque industrie de transformer cette vision en réalité à une échelle et une vitesse jamais vues. »
La Physical AI Data Factory Blueprint, annoncée en open source, fournit un cadre complet pour accélérer le développement de la robotique, des agents de vision IA et des véhicules autonomes.
Côté automobile, BYD, Hyundai, Nissan et Geely ont rejoint la plateforme robotaxi DRIVE Hyperion (18 millions de véhicules construits par an), en plus des partenaires existants (Mercedes, Toyota, GM). Un partenariat avec Uber pour déployer ces véhicules autonomes dans son réseau complète le tableau.

Pour NVIDIA, l’ère des robots intelligents est déjà là. Bientôt dans toutes les usines, plus loin dans les foyers, mais dès aujourd’hui dans les parcs d’attractions !Le moment le plus folklorique de la keynote 2026 restera sans conteste l’entrée sur scène d’Olaf, le bonhomme de neige de La Reine des Neiges, devenu pour les besoins du Parc Disneyland Paris (et l’ouverture du Land « La Reine des Neiges » le 29 mars) un robot physique fonctionnel propulsé par Jetson (la plateforme NVIDIA pensée pour embarquer l’inférence et l’intelligence temps réel dans des objets et machines physiques) et entraîné dans Omniverse (la plateforme NVIDIA de bibliothèques, microservices, API et SDK pour entraîner des World Models et créer des applications d’IA physique, comme des jumeaux numériques industriels et des simulations robotiques 3D réalistes) avec le solveur de physique Newton. Jensen Huang a dialogué en direct avec Olaf, démontrant la capacité du robot à se déplacer et interagir dans le monde réel, en temps réel. Le message est limpide : de Disneyland aux usines, les robots NVIDIA sont prêts pour le monde physique.

Et comme pour démontrer qu’aucun territoire n’est trop lointain, NVIDIA a annoncé Space-1 Vera Rubin Module, un module de calcul spatial offrant 25x plus de capacité de calcul IA que le H100 pour l’inférence en orbite. Aetherflux, Axiom Space, Kepler Communications, Planet Labs et Sophia Space veulent l’adopter pour concrétiser des datacenters orbitaux, mais aussi pour le renseignement géospatial et les opérations spatiales autonomes.
« Le space computing, l’ultime frontière, est arrivé. À mesure que nous déployons des constellations de satellites et explorons plus profondément l’espace, l’intelligence doit vivre partout où les données sont générées. […] Avec nos partenaires, nous étendons NVIDIA au-delà de notre planète en emmenant audacieusement l’intelligence là où elle n’est jamais allée » a lancé Jensen Huang avec une certaine espièglerie.

Que retenir au final ?
En 2026, la question n’est plus « faut-il des GPU et moderniser son SI ? ». Elle est : « comment et qui contrôle l’économie du token ? ». Et clairement, aujourd’hui, le « qui », c’est NVIDIA. Et le « comment » a pris clairement forme durant cette GTC 2026.
NVIDIA y a donné une forme presque définitive à son ambition : contrôler l’économie du token de bout en bout. Le matériel augmente le débit, le logiciel arbitre les ressources, le runtime sécurise les agents, la pile industrielle étend le modèle aux usines et aux robots, et l’ensemble est empaqueté comme une infrastructure durable et financièrement pilotable, éventuellement « souveraine ».
Aujourd’hui, NVIDIA veut être à la fois le fournisseur de la machine, le système d’exploitation de l’usine et la norme implicite de son exploitation.
Et ce n’est, effectivement, qu’un début. Car lors de son keynote, Jensen Huang ne s’est pas arrêté à « Vera Rubin ». Il a déjà laissé entrevoir « Feynman », la prochaine génération. Ne vous méprenez pas. Chez NVIDIA, cette feuille de route n’est pas un calendrier. C’est un instrument de pression permanente sur tout le marché. Un marché qui pourrait bien suffoquer tant le groupe laisse peu de places libres aux concurrents pour s’infiltrer…
À LIRE AUSSI :
À LIRE AUSSI :