


Data / IA
Microsoft Phi-4-Reasonning : Oui, les SLM aussi peuvent raisonner comme des grands !
Par Laurent Delattre, publié le 05 mai 2025
Quand 14 milliards de paramètres surpassent des modèles cinq fois plus grands… L’évolution des SLM franchit un cap stratégique avec l’introduction de modèles IA compacts « Phi-4 » capables de raisonnement avancé, conciliant faible latence, réflexion et performances comparables aux LLM massifs.
Microsoft a beau être un partenaire très privilégié d’OpenAI et travailler avec la plupart des acteurs pour intégrer leurs modèles IA dans Azure AI Foundry, l’éditeur ne s’interdit pas pour autant de poursuivre ses propres pistes technologiques, en travaillant sur des innovations au cœur des réseaux de neurones (comme son étonnant modèle BitNet b1.58 à base de Trit), sur ses propres SLM en open source et même sur des modèles frontières encore gardés secrets (projet MAI-1).
Un an après avoir inauguré sa gamme de petits modèles IA (SLM) Phi‑3 et deux mois après avoir inauguré la génération 4 avec un SLM multimodal (Phi-4-Multimodal) et un modèle minuscule (Phi-4-mini), Microsoft annonce trois nouvelles variantes de son SLM dernière génération : Phi‑4‑reasoning, Phi‑4‑reasoning‑plus et Phi‑4‑mini‑reasoning.
Publiées le 30 avril 2025, ces versions « à raisonnement intégré » élargissent l’offre open‑weight de modèles compacts destinés aux développeurs qui doivent maintenir une faible latence tout en exigeant un raisonnement complexe.
Au cœur de la démarche des ingénieurs de Microsoft pour rendre ses SLM « raisonnants » : se baser sur une supervision fine (SFT) à partir des chaînes de raisonnement issues d’OpenAI o3‑mini, et exploiter un renforcement par apprentissage par renforcement (RL) pour la déclinaison « plus ». « Grâce à la distillation, à l’apprentissage par renforcement et à des données de haute qualité, ces modèles concilient taille et performances », explique Microsoft.
Petits mais doués
Et les résultats aux différents principaux benchmarks du marché ont de quoi faire pâlir la concurrence : typiquement avec seulement 14 milliards de paramètres, Phi‑4‑reasoning devance DeepSeek‑R1‑Distill‑Llama‑70B (70 milliards de paramètres) sur les séries AIME 2025, MMLU‑Pro ou HumanEval‑Plus, et s’approche du modèle DeepSeek‑R1 complet (671 milliards de paramètres) ! La variante Phi-4-reasoning-plus, alignée sur les mêmes 14 Md de paramètres mais entraînée avec 1,5 fois plus de jetons, frôle les scores d’OpenAI o3‑mini sur OmniMath ! Pour information, Phi‑4‑reasoning bénéficie d’une fenêtre contextuelle classique de 128 000 tokens qui a été étendue à 256 000 tokens pour la version Phi-4-reasoning-plus.
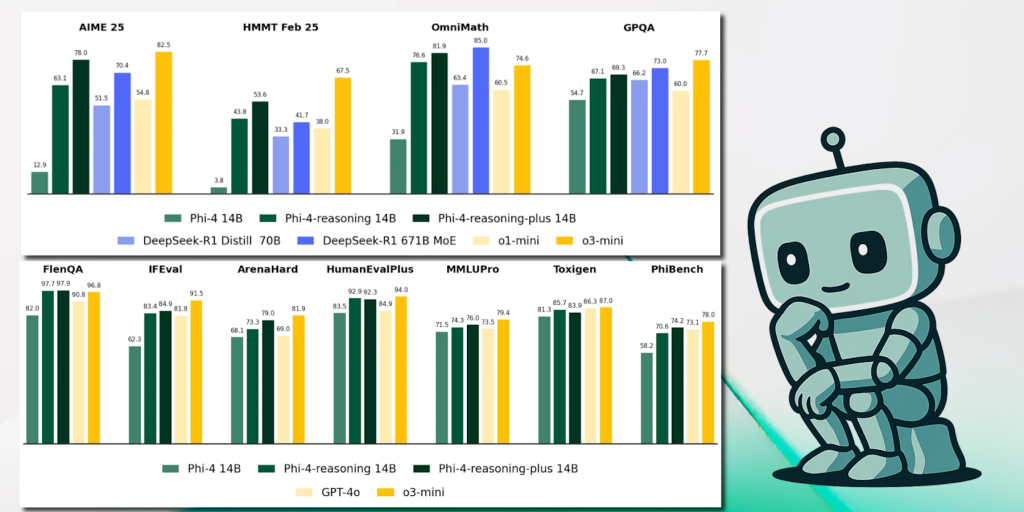
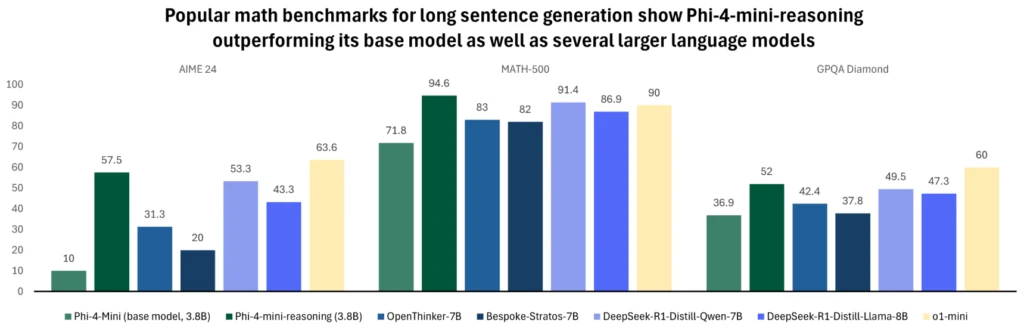
Conçu pour l’embarqué, Phi‑4‑mini‑reasoning affiche 3,8 milliards de paramètres, un jeu synthétique d’un million de problèmes mathématiques générés par DeepSeek‑R1, et atteint les performances d’o1‑mini sur Math‑500 tout en dépassant plusieurs modèles de 7 à 8 Milliards de paramètres.
Avec sa taille des plus minuscules, ce modèle sont idéaux pour une exécution locale, y compris sur terminaux mobiles et pour satisfaire les besoins de réponses quasi immédiates. Il est particulièrement adapté aux usages pédagogiques et aux chatbots locaux.
Des modèles ouverts aux usages variés
Côté déploiement, les DSI trouveront ces modèles déjà optimisés pour les PC Copilot+ : la variante NPU « Phi Silica » est préchargée en mémoire et fournit un temps‑de‑réponse quasi instantané, garantissant une cohabitation économe en énergie avec les applications métiers. Les API Windows permettent d’intégrer la génération hors‑ligne dans Outlook ou dans les outils internes.
Sur le plan sécuritaire, Microsoft revendique un pipeline aligné sur ses principes de responsabilité — responsabilité, équité, fiabilité, sécurité et inclusion. Les modèles subissent un post‑training combinant SFT, Direct Preference Optimization et RLHF à partir de jeux publics et internes orientés « helpfulness/harmlessness ». Microsoft publie par ailleurs les « Cards » de ses modèles qui détaillent les limites résiduelles et les mesures d’atténuation.
Disponibles dès à présent sur Azure AI Foundry, Hugging Face et GitHub Models, les trois modèles sont publiés sous la très permissive licence MIT, ouvrant la voie à l’inférence locale comme aux déploiements cloud hybrides. Pour les équipes sécurité et architecture, cette nouvelle génération de SLM offre une alternative crédible aux LLM massifs, avec un TCO réduit, une exécution en local comme à l’Edge et un contrôle accru des données. Ces modèles sont la preuve des incroyables progrès réalisés par les SLM depuis un an et de leur étonnant potentiel dans un univers en quête d’IA moins coûteuses et plus frugales en énergie et en ressources.
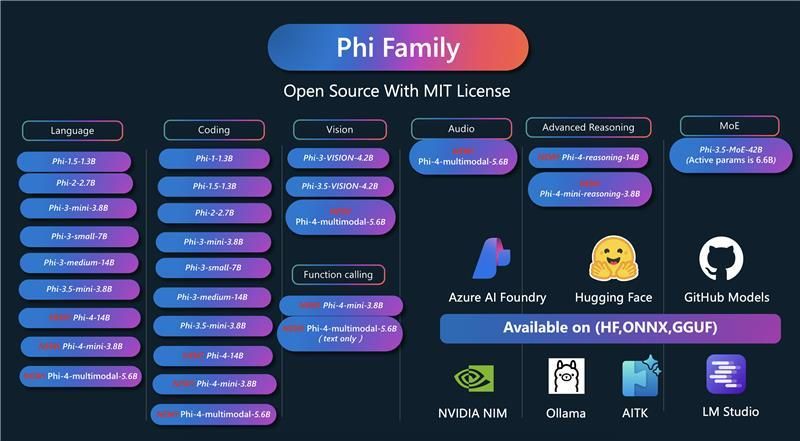
Toute la famille de modèles « Phi » de Microsoft au grand complet…
À LIRE AUSSI :
À LIRE AUSSI :

À LIRE AUSSI :











