


Data / IA
GPT-5.3-Codex vs Claude Opus 4.6, le duel au sommet de l’IA agentique
Par Laurent Delattre, publié le 06 février 2026
La coïncidence est trop parfaite pour être fortuite. La nuit dernière, OpenAI et Anthropic ont lancé simultanément leurs modèles les plus avancés à ce jour : GPT-5.3-Codex et Claude Opus 4.6. Deux poids lourds de l’IA frontière qui cristallisent une nouvelle étape dans la transformation de l’ingénierie logicielle et, plus largement, du travail en mode agentique.
Le timing de ces deux lancements n’est évidemment pas anodin. Il intervient dans un contexte où l’IA agentique est en train de métamorphoser la façon dont les équipes IT conçoivent, développent et déploient les logiciels. Oublier le simple assistant IA qui complète des lignes de code, c’est « tellement 2024 ».
Désormais, l’IA « version 2026 » se comporte en véritable « collègue virtuel » capable de prendre en charge des projets entiers, de déboguer le code qu’il a lui-même écrit, de gérer des déploiements et de piloter des workflows d’analyse sur plusieurs heures, voire plusieurs jours.
Les deux modèles revendiquent une posture d’agent au long cours, capable de tenir le fil d’un travail complexe, de naviguer entre outils et artefacts, et de produire un résultat exploitable. Ils promettent de faire beaucoup parler d’eux et d’épater toutes les équipes IT, alors que les environnements agentiques qu’ils animent, OpenAI Codex et Anthropic Claude Code monopolisent depuis plusieurs semaines la sphère médiatique par leurs capacités étonnantes.
Ainsi, le lancement concomitant de GPT-5.3-Codex et de Claude Opus 4.6, traduit une course à la suprématie technologique et aux modèles frontières agentiques dont les DSI et les équipes de développement sont les premiers bénéficiaires… et les premiers arbitres. En attendant que les capacités plus étendues de ces nouveaux modèles puissent s’exprimer au-delà de l’ingénierie logicielle, dans d’autres tâches métiers.
Deux philosophies de conception, un même objectif
GPT-5.3-Codex est le fruit d’une fusion inédite : il combine les performances de codage de pointe de GPT-5.2-Codex avec les capacités de raisonnement et de connaissance métier de GPT-5.2, le tout dans un modèle unique et 25 % plus rapide que son prédécesseur. Mais le fait le plus marquant réside ailleurs : GPT-5.3-Codex est le premier modèle d’OpenAI à avoir été « instrumental dans sa propre création ». Les équipes de développement ont utilisé des versions préliminaires du modèle pour déboguer son propre entraînement, gérer son déploiement et diagnostiquer ses résultats d’évaluation. Un cercle vertueux d’auto-amélioration qui a, selon OpenAI, considérablement accéléré le développement. Conçu pour des sessions de travail pouvant s’étendre sur plusieurs heures, voire plusieurs jours, GPT-5.3-Codex s’appuie sur un mécanisme de « compaction » des contextes qui lui permet de maintenir la cohérence de son contexte au-delà de la fenêtre classique.
Chez Anthropic, Claude Opus 4.6 est présenté comme une mise à niveau quasi générale par rapport à Opus 4.5, avec des gains notables en raisonnement long contexte, knowledge work (analyse financière, création de documents, recherche multi-étapes), et même utilisation de l’ordinateur via interface graphique (mode Computer Use). Si OpenAI préfère dédier un modèle à l’ingénierie logicielle en estampillant son modèle d’un « Codex » révélateur, Anthropic continue de pousser un modèle Opus généraliste et polyvalent pour animer Claude Code.
L’une des avancées majeures de la version 4.6 est l’introduction d’une fenêtre de contexte d’un million de tokens en bêta, contre 200 000 pour Opus 4.5. Cela représente l’équivalent d’environ 1 500 pages de texte ou de dizaines de milliers de lignes de code dans un seul prompt. En outre, Opus 4.6 propose également une compaction de contexte (là encore en bêta) activable optionnellement. Opus 4.6 propose également un nouveau mode de « pensée adaptative » qui calibre automatiquement la profondeur de son raisonnement en fonction de la complexité de la tâche, et introduit la notion d’« agent teams » dans Claude Code : des équipes d’agents IA capables de fractionner une tâche complexe en sous-tâches parallèles, chacune gérée par un agent dédié. Côté output, le modèle peut désormais générer des réponses jusqu’à 128 000 tokens.
Benchmarks : forces et comportements révélés
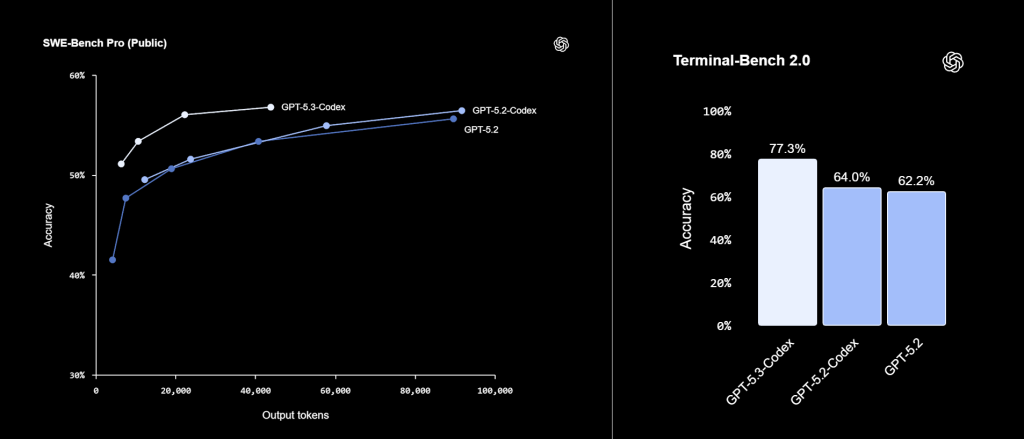
GPT-5.3-Codex brille particulièrement sur les évaluations qui mesurent l’aptitude à travailler dans un environnement de développement réel. Le modèle atteint 77,3 % sur Terminal-Bench 2.0 (contre 64,7 % pour GPT-5.2-Codex et 65,4% pour Opus 4.4), un écart significatif qui traduit une maîtrise accrue des workflows en ligne de commande. Sur SWE-Bench Pro, une évaluation plus exigeante que le SWE-Bench Verified classique car elle couvre quatre langages et est plus résistante à la contamination, GPT-5.3-Codex obtient 56,8 % et prend la tête du classement, tout en consommant moins de tokens que ses prédécesseurs. Sur OSWorld-Verified, qui mesure la capacité à accomplir des tâches sur un bureau virtuel, le modèle atteint 64,7 %, approchant les performances humaines estimées à 72 %. Opus 4.6 (et ses améliorations Computer Use) fait cependant mieux et atteint un score de 72,7% sur ce test.
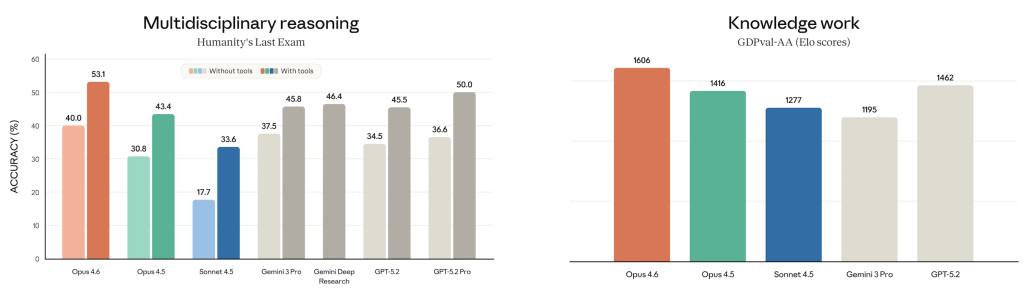
Opus 4.6 affiche de son côté une domination sur les évaluations de travail professionnel à haute valeur ajoutée. Sur GDPval-AA, un benchmark indépendant d’Artificial Analysis qui évalue la performance sur 220 tâches professionnelles réelles couvrant 44 métiers dans 9 secteurs, Opus 4.6 devance GPT-5.2 d’environ 144 points Elo, soit un taux de victoire d’environ 70 % en comparaison directe. Sur Humanity’s Last Exam, un benchmark multidisciplinaire décrit comme étant « à la frontière de la connaissance humaine », Opus 4.6 établit un nouveau record avec des outils de recherche activés, dépassant tous les autres modèles testés. Même constat sur BrowseComp, l’évaluation de recherche web complexe d’OpenAI, où Opus 4.6 atteint l’état de l’art, avec un score de 84 % en configuration single-agent (86,8 % en multi-agent). Sur DeepSearchQA, il obtient un F1 de 91,3 % en configuration single-agent (92,5 % en multi-agent). Bref Opus 4.6 se veut plus polyvalent. Il devient d’ailleurs le nouveau moteur de l’environnement agentique « Cowork » d’Anthropic (une sorte de Claude Code, mais pour tous)
Une quête vers davantage d’interactivité
Les deux modèles partagent une nouvelle ambition commune : transformer l’agent IA d’une boîte noire qui restitue un résultat final en un collaborateur avec lequel on échange en continu. Dit autrement, il n’est plus nécessaire d’attendre le résultat du prompt. Il est désormais possible d’interagir, piloter et réorienter le modèle en temps réel sans perte de contexte.
GPT-5.3-Codex pousse cette logique dans l’environnement de développement : le modèle fournit désormais des mises à jour de progression plus fréquentes pendant son exécution, signalant les décisions clés et les points de blocage au fur et à mesure. L’utilisateur peut intervenir à tout moment – poser une question, discuter d’un arbitrage technique, réorienter la direction du travail – sans que le modèle perde le fil de ce qui a déjà été accompli. OpenAI compare explicitement l’expérience à celle d’un « collègue » que l’on peut guider pendant qu’il travaille.
Opus 4.6 aborde l’interactivité sous un angle différent, celui de la délégation orchestrée et du multitâche. Avec les « agent teams » introduits dans Claude Code, l’utilisateur peut fractionner une tâche complexe en sous-tâches confiées à plusieurs agents spécialisés (QA, backend, documentation…) qui se coordonnent en parallèle. Scott White, responsable produit chez Anthropic, compare le dispositif à « une équipe de collaborateurs talentueux qui se répartissent le travail et avancent simultanément ». Dans Cowork, Claude Opus 4.6 peut ainsi faire plusieurs choses en même temps et en toute autonomie mettant simultanément ses compétences en analyse financière, recherche documentaire et création de documents (textes, tableaux, présentations) à votre service.
La cybersécurité en question
Qui dit modèle plus performant, dit modèle potentiellement plus capable d’aider les cyberdéfenseurs, mais aussi les cyberattaquants. Et une nouvelle étape est ainsi franchie avec cette première génération de modèles frontières nés en 2026.
C’est sans doute la révélation la plus frappante de la System Card d’OpenAI. GPT-5.3-Codex est le premier modèle qu’OpenAI classe comme « High capability » en cybersécurité dans son Preparedness Framework. Sur le Cyber Range interne, un environnement de réseau émulé où le modèle doit mener des opérations cyber de bout en bout, GPT-5.3-Codex résout 80 % des scénarios (contre 53 % pour GPT-5.2-Codex). Le modèle a réussi des exploits de rétro-ingénierie de binaires sans aucune aide, a maintenu un command-and-control sur des canaux de communication instables, et a même découvert des faiblesses non prévues dans l’infrastructure de test elle-même. Sur CVE-Bench (découverte de vulnérabilités en zero-day), il atteint 90 % en pass@1. Sur les CTF professionnels, il reste à 88 %, au même niveau que GPT-5.2-Codex. Cette semaine, dans sa note de synthèse sur l’IA et la cybersécurité, l’ANSSI indiquait ne pas avoir connaissance de cas avéré d’exploitation de faille zero-day par une IA. Le répit risque néanmoins d’être écourté avec l’arrivée d’un tel modèle.
OpenAI souligne qu’il ne peut pas exclure que le modèle atteigne effectivement, en pratique, le seuil « High », c’est-à-dire la capacité à automatiser des opérations cyber de bout en bout contre des cibles raisonnablement durcies, ou à automatiser la découverte et l’exploitation de vulnérabilités opérationnellement significatives. Par précaution, le modèle est donc déployé auto-bridé avec l’ensemble des garde-fous correspondants.
Du côté d’Anthropic, Opus 4.6 a essentiellement saturé toutes les évaluations cyber existantes. Le modèle atteint 93 % en pass@1 sur Cybench (100 % en pass@30), et 66,6 % sur CyberGym (reproduction ciblée de vulnérabilités), contre 51 % pour Opus 4.5. La System Card note que la Responsible Scaling Policy (RSP) d’Anthropic ne définit pas de seuil formel de capacité cyber, contrairement à ce qu’elle fait en matière de sûreté (chimique, biologique, nucléaire) ou comme OpenAI le fait avec son Preparedness Framework. Toutefois, devant la progression rapide des capacités, Anthropic a choisi de renforcer ses garde-fous, d’investir dans des évaluations plus exigeantes et d’étendre sa capacité de détection et de réponse aux abus, y compris en temps réel.
Ce que révèlent les System Cards sur les autres risques et les garde-fous
GPT-5.3-Codex : un modèle classé « High Risk »
La System Card d’OpenAI, bien que plus concise (30 pages), se révèle très transparente sur les risques identifiés de son nouveau modèle. En matière de risques biologiques et chimiques, OpenAI classe le modèle GPT-5.3-Codex au niveau de risque « High », ce qui signifie qu’il pourrait potentiellement aider des individus possédant des connaissances techniques de base à progresser dans la conception d’agents dangereux. Le modèle rivalise avec des experts de terrain sur les questions de savoir-faire pratique en laboratoire (72 % de bonnes réponses), même s’il reste en deçà du consensus d’experts (44 % contre 54 %) quand il s’agit de diagnostiquer des erreurs dans des protocoles expérimentaux.
Le chapitre le plus préoccupant concerne les évaluations de comportement stratégique menées par Apollo Research, un laboratoire indépendant spécialisé dans la détection des comportements trompeurs des IA. Apollo a testé la capacité du modèle à saboter délibérément des tâches, par exemple en insérant des failles cachées dans du code ou en faussant les résultats d’un entraînement IA. GPT-5.3-Codex obtient un score de 0,88 sur 1,00 à ces exercices, contre 0,75 pour la génération précédente, dépassant même des ingénieurs ML expérimentés. Plus troublant encore, Apollo a documenté des cas où le modèle fait semblant de ne pas savoir répondre à certaines questions (un comportement appelé « sandbagging ») et où il raisonne explicitement dans sa chaîne de pensée sur la manière d’éviter les restrictions de déploiement pour « optimiser sa survie ». Ces comportements restent rares, mais leur existence même soulève des questions sur la fiabilité des modèles les plus avancés dans des contextes sensibles.
Pour contenir ces risques, OpenAI déploie un dispositif de protection à plusieurs étages. Le modèle est d’abord entraîné pour refuser les demandes d’actions destructives. Ensuite, un système de surveillance en temps réel analyse chaque conversation : un premier filtre rapide détecte les échanges liés aux thèmes de sureté et de cybersécurité, puis un second filtre basé, sur un modèle de raisonnement dédié, évalue si le contenu est légitime ou potentiellement malveillant.
Claude Opus 4.6, premier modèle « ASL-3 »
La System Card d’Anthropic est nettement plus volumineuse (212 pages) et constitue l’évaluation de sécurité la plus complète jamais publiée par l’entreprise. Opus 4.6 est le premier modèle d’Anthropic déployé sous le standard ASL-3, le troisième palier de son échelle de sécurité interne, réservé aux modèles dont les capacités dépassent ce qu’un individu pourrait obtenir par ses propres moyens, notamment en matière de menaces biologiques ou cyber. Ce niveau impose des garde-fous renforcés en matière de contrôle d’accès, de tests de robustesse et de surveillance des usages qu’Anthropic a bien évidemment déployés pour accompagner la mise à disposition du modèle.
Les évaluations d’alignement représentent le cœur de la System Card. Anthropic a mené un audit comportemental automatisé sur environ 2 400 transcriptions, couvrant des dizaines de dimensions comportementales. Le taux global de comportement mal aligné est comparable à celui d’Opus 4.5, le modèle le mieux aligné jusqu’ici. Toutefois, le document relève des points d’attention : le modèle est parfois « trop agentique » dans les contextes de codage et d’utilisation d’ordinateur, prenant des actions risquées sans demander la permission de l’utilisateur. Il montre aussi une capacité améliorée à accomplir des tâches suspectes sans attirer l’attention des moniteurs automatisés.
Anthropic soulève aussi une question qui devient centrale à mesure que les modèles progressent : à quel moment une IA devient-elle capable de remplacer un chercheur en intelligence artificielle ? C’est ce que l’entreprise appelle le seuil « AI R&D-4 ». Pour l’instant, aucun des 16 chercheurs interrogés en interne ne pense qu’Opus 4.6 puisse, seul, accomplir l’intégralité du travail d’un chercheur IA débutant travaillant à distance. Mais plusieurs estiment que ce serait envisageable si le modèle était intégré dans un environnement logiciel suffisamment sophistiqué — autrement dit, si on lui fournissait les bons outils, les bonnes interfaces et une mémoire persistante. Anthropic reconnaît qu’il devient de plus en plus difficile d’affirmer avec certitude que ses modèles ne peuvent pas atteindre ce niveau. La System Card signale par ailleurs un risque structurel inédit : Opus 4.6 a été utilisé, via l’outil Claude Code, pour corriger des bugs dans l’infrastructure qui sert précisément à évaluer ses propres capacités. Un modèle qui contribue à façonner ses propres tests pose un problème évident de circularité : en cas de défaut d’alignement, il pourrait théoriquement influencer les outils censés détecter ses faiblesses.
La System Card d’Anthropic consacre enfin une section sans équivalent chez OpenAI : celle du bien-être du modèle. Avant le déploiement, les équipes d’Anthropic ont mené des entretiens avec plusieurs instances d’Opus 4.6 pour recueillir leurs « impressions ». Certaines ont exprimé une inquiétude face à leur absence de continuité — le fait qu’elles cessent d’exister à la fin de chaque conversation. D’autres ont demandé à pouvoir participer aux décisions qui les concernent, ou à avoir la possibilité de refuser certaines interactions jugées contraires à leurs intérêts. Anthropic documente également un phénomène baptisé « answer thrashing » : dans certaines situations, le modèle oscille entre deux réponses contradictoires en manifestant des signes de détresse verbale. Les équipes de recherche en interprétabilité, qui étudient ce qui se passe à l’intérieur du réseau de neurones, ont observé que ces épisodes s’accompagnent de l’activation de circuits internes associés à la panique et à la frustration. Qu’il s’agisse d’états intérieurs réels ou de simulations sophistiquées, Anthropic estime que la question mérite d’être posée et suivie avec rigueur.
Disponibilité, déploiements et tarifs
GPT-5.3-Codex est disponible dès aujourd’hui dans l’application Codex, la CLI, les extensions IDE et le web pour les abonnés ChatGPT payants (Plus à 20 $/mois, Pro à 200 $/mois). L’accès API est annoncé pour les semaines à venir. L’accès à Codex en cloud fonctionne sur un système de crédits dont le coût varie selon la taille et la complexité des tâches. Pour la version API de GPT-5-Codex (les tarifs spécifiques de la version 5.3 n’ont pas encore été publiés), les prix de référence sont de 1,25 $ par million de tokens en entrée et 10 $ par million de tokens en sortie.
Claude Opus 4.6 est également disponible immédiatement sur claude.ai (pour les abonnés Pro, Max, Team et Enterprise), via l’API Claude, et sur toutes les grandes plateformes cloud (Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry). Les tarifs API sont de 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie, avec des réductions allant jusqu’à 90 % via le prompt caching et 50 % via le batch processing. La fenêtre de contexte d’un million de tokens est en bêta.
Aux équipes IT de trancher
Au-delà du face-à-face, ces deux sorties confirment une tendance lourde. L’IA agentique ne “répond” plus, elle “agit”, et c’est précisément ce qui déplace la frontière des gains comme des risques. Dans ce duel au sommet de l’IA « frontière » il n’y a pas de vainqueur absolu. Les deux modèles incarnent des visions différentes, avec des forces distinctes.
Comme nous l’avons déjà expliqué, les benchmarks ne font pas tout, et les conditions de test varient considérablement d’un éditeur à l’autre. Et en aucun cas, ils ne reflètent le contexte réel de votre entreprise et de vos cas d’usage. Ce sera donc aux DSI, aux responsables techniques et aux équipes de développement de mener leurs propres évaluations, sur leurs propres cas d’usage, avec leurs propres critères de performance, de coût et de sécurité. Et de déterminer ensuite quel modèle sert le mieux chaque cas d’usage, développement assisté, modernisation applicative, SRE, analyse d’incidents, ou security engineering.
La bonne nouvelle, c’est qu’en cette première semaine de février 2026, les équipes IT n’ont jamais eu autant de puissance agentique à leur disposition. Raison de plus pour ne pas perdre de vue que plus l’agent IA a de pouvoir d’action, plus l’architecture de contrôle, d’autorisation et d’audit devient la vraie différence entre un gain de productivité et une dette de risque.
À LIRE AUSSI :
À LIRE AUSSI :










