Data / IA
Data + AI Summit 2025 : Databricks accélère sur le Lakehouse et l’IA
Par Laurent Delattre, publié le 18 juin 2025
La bataille du Data Cloud s’accélère : Databricks fonce sur la fusion data, IA et BI pour casser les frontières entre analytique et opérationnel. Nouvelles bases, agents IA, migration simplifiée, nouvelles expériences data plus accessibles… À l’occasion de sa conférence « Data + AI Summit 2025 » Databricks a cherché à tout aligner pour rendre la donnée plus agile et l’innovation IA accessible à tous. Voici ce qu’il faut en retenir…
Le Data + AI Summit 2025 de Databricks s’est tenu la semaine dernière, à quelques jours d’intervalle de l’évènement du grand concurrent Snowflake. Un sommet 2025 qui s’inscrit dans un contexte de forte compétition autour du Data Cloud et de l’intelligence artificielle. Face aux géants du cloud (Azure, Google Cloud, AWS) qui renforcent leurs propres offres data & IA, les acteurs indépendants multiplient les initiatives de consolidation et d’innovation.
Ces derniers mois, le secteur a ainsi connu des acquisitions stratégiques majeures : Salesforce a racheté le spécialiste du data management Informatica (pour 8 milliards de dollars), Snowflake s’est offert Crunchy Data pour intégrer PostgreSQL dans son offre, et Databricks a acquis la startup de base de données serverless Neon (pour environ 1 milliard de dollars) toujours dans l’univers PostgreSQL.
Sur fond de show audiovisuel, le CEO Ali Ghodsi a rappelé la vocation de Databricks : « démocratiser les données et l’IA » à l’échelle de l’entreprise. Constatant une fragmentation persistante de l’écosystème données/IA, avec des données toujours plus réparties et des offres IA trop peu régentées, il a martelé l’ambition de Databricks d’y remédier grâce à une plateforme unifiée. Baptisée désormais Data Intelligence Platform, sa plateforme Lakehouse entend réunir données, analytique et IA sur un même socle multi-cloud. Et pour cela, Databricks compte bien accélérer la convergence du datalake, du datawarehouse et de l’IA. La suite de l’événement s’est ainsi transformée en un flot « fast and furious » d’annonces officielles couvrant tous les axes : données opérationnelles, gouvernance ouverte, pipelines, IA générative, BI et éducation.
Nous vous proposons ici de revenir sur les principales annonces de cet évènement principalement marqué par les lancements de Lakebase, Agent Bricks et Databricks One, mais aussi par l’idée que, un peu comme Microsoft Fabric, Databricks n’est plus une plateforme de données mais bien davantage une sorte de système d’exploitation complet pour la data et l’IA d’entreprise.
Lakehouse : vers une convergence opérationnelle et une gouvernance ouverte
Databricks a profité du Summit 2025 pour étendre encore un peu plus son Lakehouse aux usages transactionnels et à une gouvernance plus ouverte. Et dans le contexte des rachats évoqués plus haut, la grande annonce de ce « Summit 2025 » n’était pas véritablement une surprise :
Un nouveau socle transactionnel : Lakebase
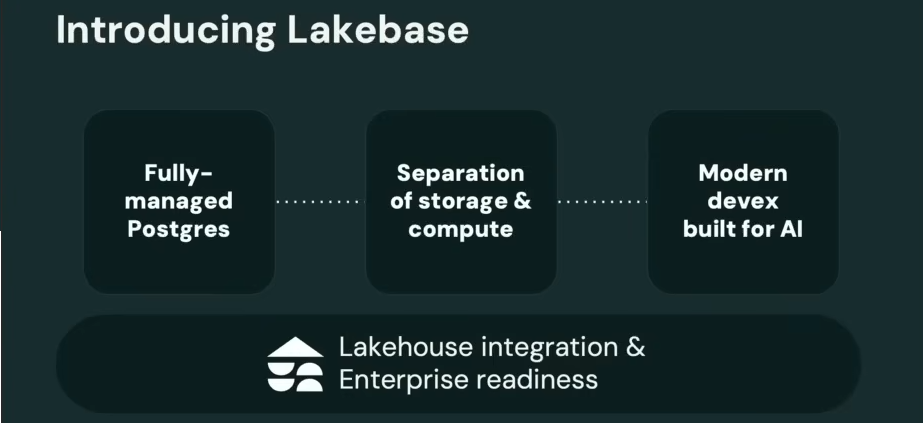
C’est donc officiel, le Lakehouse de Databricks s’enrichit d’un SGBD transactionnel entièrement managé, serverless, et bien évidemment 100% PostgreSQL-compatible. En public preview, Lakebase ajoute ainsi une couche OLTP au Lakehouse de Databricks avec la volonté d’en faire dès le départ un socle conçu pour les applications modernes pilotées par l’IA. Basé sur la technologie de la startup Neon (rachetée par Databricks), Lakebase sépare le calcul et le stockage. La solution bénéficie d’un autoscale en continu et promet une latence inférieure à 10 ms et au moins 10 000 Transactions par seconde. Elle apporte aussi des fonctions innovantes (clonage branch de bases pour tests, synchronisation automatique avec les tables du lakehouse) afin d’unifier données opérationnelles (OLTP) et analytiques (OLAP).
L’objectif affiché : offrir aux développeurs, mais aussi aux agents IA, la vitesse et la simplicité d’une base Postgres cloud-native, tout en restant dans l’univers très intégré de la plateforme Databricks (feature store en ligne, gouvernance via l’Unity Catalog, support des Databricks Apps, etc.).
Un Unity Catalog plus ouvert et “business-friendly”
La solution de gouvernance unifiée des données et des modèles IA de Databricks, Unity Catalog, permet aux entreprises de gérer de manière centralisée les accès, les métadonnées, la traçabilité et la conformité de toutes leurs données, qu’elles soient utilisées pour l’analyse, l’ingénierie ou l’intelligence artificielle. Intégré nativement dans la plateforme Databricks, Unity Catalog procure une visibilité complète et centralisée sur l’usage des données tout en garantissant une posture de sécurité cohérente à travers tous les environnements, qu’ils soient multi-cloud ou hybrides. Et Unity Catalog gagne de puissantes extensions.
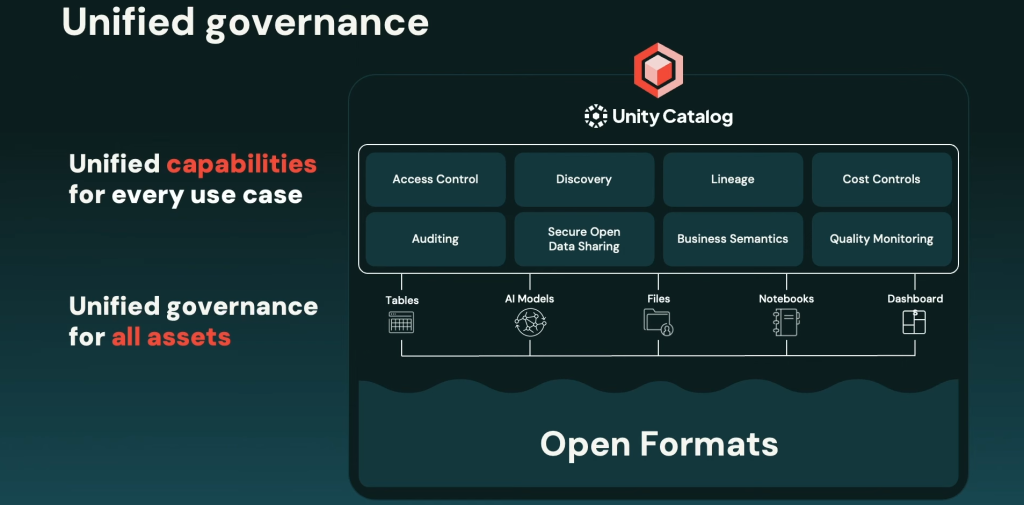
La solution de gouvernance prend désormais en charge nativement les tables Apache Iceberg (en plus de Delta), avec support de l’API REST Iceberg. Une ouverture qui permet de concilier interopérabilité technologique et exigences de gouvernance. Concrètement, les entreprises peuvent désormais appliquer les mêmes règles de sécurité, de traçabilité et de conformité sur des données stockées dans Iceberg que sur celles déjà présentes dans le Lakehouse. Pour les DSI, cela facilite l’intégration de sources hétérogènes tout en maintenant une cohérence opérationnelle. Pour les RSSI, c’est un gage de contrôle accru : chaque accès, chaque transformation, chaque usage des données peut être audité, même si les données résident en dehors de Databricks, dans des lacs de données ouverts.
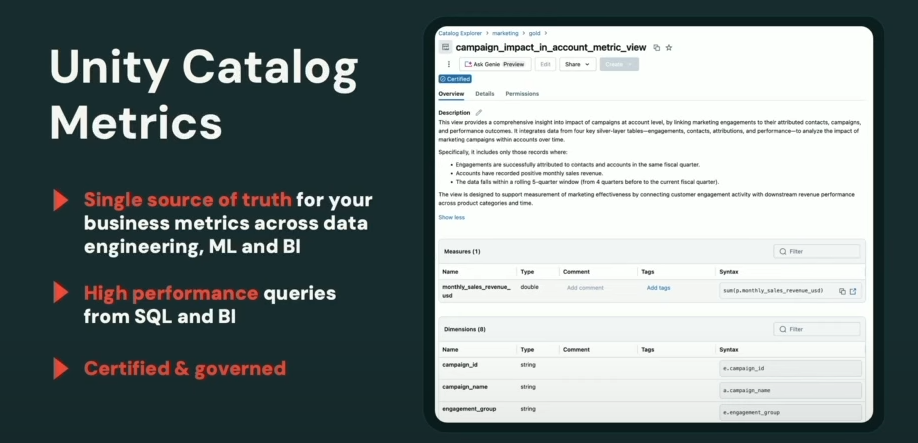
D’autre part, Unity Catalog s’enrichit pour mieux satisfaire les besoins métiers. Databricks lance Unity Catalog Metrics (pour gérer de façon centralisée des indicateurs métier réutilisables dans tous les outils, tableaux de bord BI, requêtes SQL, notebooks, etc.) et un catalogue interne “Discover”. Ce dernier est une marketplace de données interne par domaine métier, avec recommandations pilotées par l’IA pour trouver les datasets les plus pertinents. Ces nouveautés visent essentiellement à combler le fossé entre la donnée brute et sa compréhension métier, en offrant une couche sémantique unifiée sur l’ensemble des données de l’entreprise.
Des Clean Rooms multi-cloud et multi-party
Les Clean Rooms de Databricks débarquent enfin sur GCP, après leur déploiement sur AWS et Azure en début d’année. Ces espaces de collaboration de données sécurisés permettent à plusieurs organisations de collaborer sur des données sensibles sans jamais exposer les données brutes. La grande nouveauté réside dans le support d’une collaboration jusqu’à 10 entreprises au lieu de 2 auparavant. Une collaboration qui s’étend sur des clouds différents, des régions cloud différentes et même des plateformes de données différentes. Les Clean Rooms de Databricks prennent désormais en charge des requêtes croisées entre différents formats de données, y compris les tables Delta et Iceberg, ce qui élargit considérablement les cas d’usage. En outre, les Clean Rooms sont désormais nativement intégrées à la gouvernance d’Unity Catalog ce qui permet d’appliquer des politiques de gouvernance, de traçabilité et de contrôle d’accès de manière centralisée et granulaire. Cela signifie que les entreprises peuvent désormais partager des données avec des partenaires, des clients ou des fournisseurs tout en respectant les exigences réglementaires (comme le RGPD ou le HIPAA), sans avoir à dupliquer ou déplacer les données. Les DSI et RSSI doivent y voir un moyen simple de sécuriser les collaborations inter-entreprises, tout en gardant le contrôle total sur ce qui est partagé, comment, et avec qui.
Lakebridge : un pont de modernisation stratégique
Databricks introduit un nouvel outil pour automatiser la migration depuis les entrepôts de données traditionnels (datawarehouses) vers son lakehouse. Son objectif est de simplifier et d’automatiser le transfert de données, de schémas et de workloads depuis des systèmes comme Teradata, Oracle ou Snowflake vers Databricks.
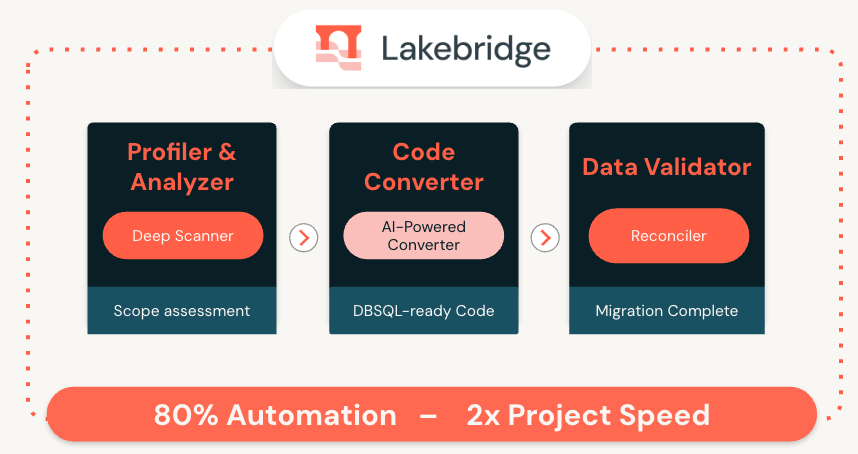
LakeBridge agit comme un pont technologique, en assurant la compatibilité des requêtes SQL, la conversion des pipelines ETL, la validation et la réconciliation des données migrées ainsi que la préservation des règles de gouvernance et de sécurité. Lakebridge promet de diviser par 2 le temps de migration en prenant en charge l’ensemble du processus. Pour les DSI, c’est une réponse directe aux défis de modernisation des plateformes data, souvent freinée par la complexité des migrations. LakeBridge promet une transition plus fluide, plus rapide et moins risquée. Reste à vérifier que les promesses sont tenues. L’expérience dicte qu’en matière de migration, les choses ne sont jamais aussi simples qu’anticipées.
Pipelines de données : ingestions et ETL simplifiés, ouverture open source
Au-delà des nouveautés sur le cœur de la plateforme Databricks, plusieurs annonces ciblaient ouvertement la productivité des ingénieurs data et l’accélération des projets d’intégration de données.
Lakeflow se finalise…
À l’occasion du Summit 2025, Databricks a officialisé la « GA » (disponibilité générale) de l’une des grandes annonces de l’édition 2024 : Lakeflow. La plateforme unifiée de data-engineering et d’ingestion de données de Databricks est conçue pour simplifier et accélérer la création de pipelines de données, qu’ils soient en batch, en streaming ou issus de sources non structurées. Cette version finale se voit enrichie d’un mode pipelines déclaratifs qui permet aux data engineers de définir des pipelines de bout en bout en SQL ou Python, sans avoir à gérer d’infrastructure (Databricks se charge de l’exécution scalable). Un nouvel IDE dédié data engineering embarque désormais de l’IA en standard pour assurer l’auto-complétion mais aussi le débogage assisté afin d’accélérer le développement de pipelines dans l’UI Databricks. Databricks étoffe également Lakeflow Connect (sa bibliothèque de connecteurs d’ingestion) avec de nombreuses sources prêtes à l’emploi : Google Analytics, ServiceNow, SQL Server, SharePoint, PostgreSQL, SFTP, etc., s’ajoutant aux connecteurs Salesforce et Workday déjà disponibles. Enfin, Zerobus est un nouveau module d’ingestion de données événementielles en temps réel : Zerobus permet d’écrire de gros volumes d’événements IoT, logs, clickstream, etc., directement dans le lakehouse en quasi-temps réel, sans avoir à déployer de bus de messages externe (Kafka, Kinesis…).

… et s’apprécie en Low Code avec LakeFlow Designer
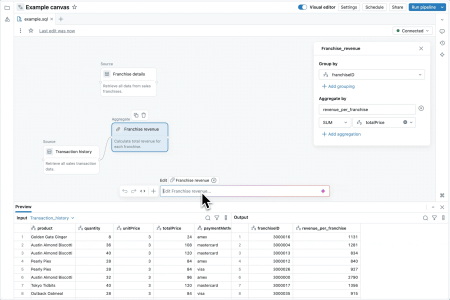
Porté par sa mission de démocratiser la création de pipelines, Databricks a officialisé Lakeflow Designer, un nouvel atelier visuel no-code, en drag-and-drop, qui permet aux métiers de construire des pipelines ETL de qualité production sans écrire de code. L’interface s’accompagne d’un assistant intelligent en langage naturel (GenAI) pour guider la création des transformations. Sous le capot, les pipelines conçus avec Designer reposent bien évidemment sur Lakeflow et sur Unity Catalog, garantissant les mêmes standards de gouvernance, fiabilité et scalabilité que les pipelines codés avec les API et SDK.
Spark Declarative Pipelines : parce que l’open source le vaut bien
En écho à Lakeflow, Databricks n’oublie pas la communauté open source. Le Summit 2025 a été l’occasion de présenter Spark Declarative Pipelines, un projet open source permettant de définir des pipelines de données de manière déclarative sur Apache Spark. Cet outil autorise la création de flux ETL batch ou streaming via des spécifications haut niveau (SQL ou API), couvrant n’importe quelle source supportée par Spark (data lakes, queues de messages, change data capture, systèmes externes, etc.). En open sourçant ce composant, Databricks réaffirme son engagement envers l’écosystème Spark et sa volonté de standardiser les bonnes pratiques ETL à grande échelle.
IA générative: de l’expérimentation à la production
Le Summit a surtout été marqué par une avalanche de nouveautés autour de l’IA générative et du Machine Learning, reflétant la maturité croissante des projets d’IA en entreprise. Databricks, fort de l’intégration de MosaicML, se positionne aujourd’hui comme une plateforme ML/AI de bout en bout, de la conception d’agents IA jusqu’au déploiement à l’échelle.
Agent Bricks (Beta) : La grosse annonce IA

C’était l’annonce la plus attendue, celle de la réponse de Databricks à toutes les initiatives concurrentes autour des agents IA. Agent Bricks est un environnement unifié de création d’agents IA : il suffit de décrire en langage naturel la tâche de l’agent et de brancher ses données. L’utilisateur n’a pas besoin de coder ou de concevoir manuellement des workflows complexes : la plateforme se charge automatiquement de générer, d’évaluer et d’optimiser les agents pour la qualité, la performance et le coût.
Concrètement, Agent Bricks s’appuie sur les dernières recherches de MosaicML pour produire du jeu de données synthétique spécifique au domaine et des benchmarks d’évaluation automatiques, puis fait varier les modèles, prompts et hyperparamètres afin d’optimiser l’agent en coût et qualité. Pour cela, Agent Bricks s’appuie sur des modèles “juges”, des LLM spécialisés dans l’évaluation en continu de la pertinence et de la fiabilité des réponses produites par les agents. Le tout en intégrant gouvernance et contrôle entreprise dès le départ.
Cette approche permet de passer de l’idée à un agent IA prêt pour la production en un temps record, sans le laborieux cycle d’essais-erreurs manuel. Databricks cite le cas d’un client ayant pu configurer en moins d’une heure un agent d’extraction d’information sur 400 000 documents cliniques, le tout sans écrire une ligne de code, là où des semaines d’efforts étaient autrefois nécessaires. Et puisque l’on évoque les agents IA, Databricks a annoncé le support du fameux protocole MCP avec notamment l’hébergement de serveurs MCP via les Databricks Apps et le support MCP dans AI Gatexay, sa « front door » unifiée pour tous les services IA.
Des fonctions IA en SQL & du Vector Search
Databricks facilite l’adoption de l’IA générative directement au cœur des usages analytiques. Ses AI Functions (fonctions SQL s’appuyant sur des modèles génératifs) passent en disponibilité générale, avec de nettes améliorations de performance : jusqu’à 3× plus rapides et 4× moins coûteuses que les offres concurrentes sur des workloads de grande échelle, selon l’éditeur. Surtout, ces fonctions deviennent multimodales : elles savent désormais traiter non seulement du texte mais aussi des images et d’autres types de données. Par exemple, la nouvelle fonction ai_parse_document permet d’extraire en une requête SQL des informations structurées à partir d’un document complexe (PDF, image scannée…). De quoi intégrer l’analyse de documents, d’images ou de contenus non structurés directement dans des pipelines SQL, sans étape ML séparée.
Par ailleurs, Databricks annonce une refonte de son Mosaic Vector Search, le moteur de recherche de vecteurs utilisé pour les systèmes RAG (retrieval augmented generation). Désormais fondé sur une architecture qui sépare calcul et stockage pour gagner en flexibilité de montée en charge, ce moteur de vectorisation passe en Public Preview et supporte le passage à l’échelle sur des milliards de vecteurs avec un coût réduit d’un facteur 7. Cela ouvre la voie à des applications de recherche sémantique et de chatbots documentaires à l’échelle de l’entreprise entière, en restant économiquement viables.
Data intelligence pour tous : BI augmentée, apps, et formation
Au-delà des innovations techniques et de l’IA, ce Summit 2025 aura également insisté sur la démocratisation de la data et de son analyse auprès de tous les publics. Avec en fer de lance sa nouvelle expérience utilisateur Databricks One.
Databricks One : l’interface « GenBI »
C’est l’une des annonces les plus marquantes du Summit 2025. Databricks One est une nouvelle interface unifiée à destination des décideurs et analystes métier. Cette nouvelle expérience cherche à rendre l’expérience Databricks plus accessible à tous. L’idée est de fournir, au sein d’un environnement web élégant et sans code, un accès simple et sécurisé à toutes les capacités data et IA de la plateforme pour un public non technique. « Chacun, quel que soit son niveau de compétence, doit pouvoir exploiter les données », a martelé le CEO de Databricks, Ali Ghodsi, à l’occasion du « Data + AI Summit 2025 ». Et Databricks One est la concrétisation de cette volonté.
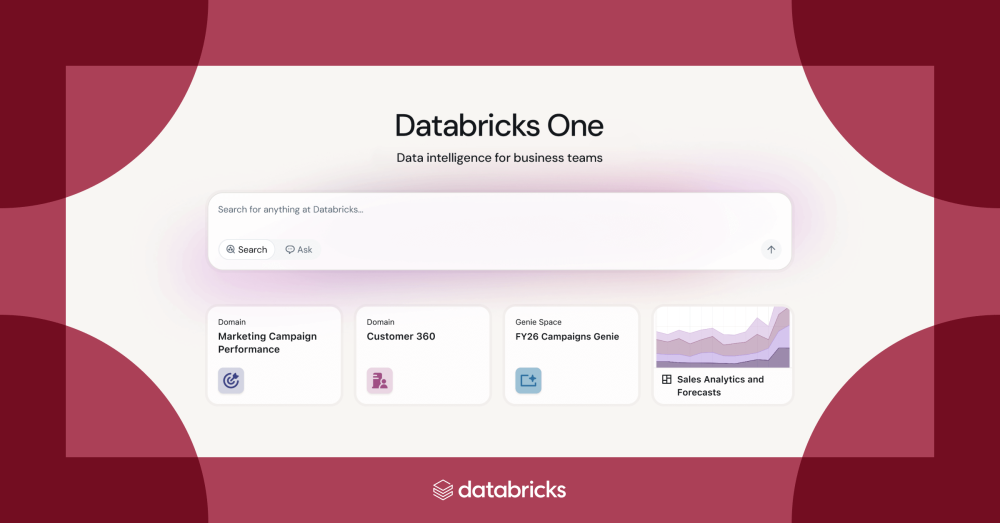
Concrètement, la solution regroupe un portail de tableaux de bord interactifs (avec filtres et exploration dynamique), la possibilité de poser des questions en langage naturel aux données via l’assistant AI/BI Genie (voir plus loin), un moteur de recherche pour retrouver rapidement les rapports pertinents, et même l’exécution d’applications Databricks Apps personnalisées. L’ambition : faire de Databricks un outil quotidien pour les équipes métier, et pas seulement pour les data scientists ou ingénieurs.
En lançant en avant-première privée cette expérience « tout-en-un » pour utilisateurs métier, Databricks fait évoluer son positionnement d’une plateforme technique vers une plateforme fusionnant IA et intelligence décisionnelle. Ce super tableau de bord intelligent réinvente la manière dont les collaborateurs peuvent interagir au quotidien avec les données.
AI/BI Genie : l’assistant IA
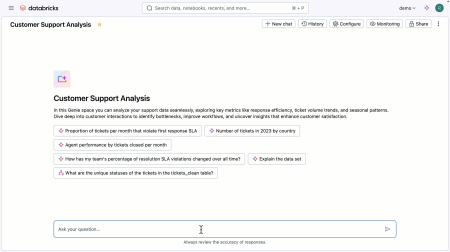
« Genie », c’est l’interface conversationnelle intégrée à la plateforme Databricks. Conçue pour permettre à n’importe quel utilisateur, même sans compétences techniques, d’interagir avec ses données en langage naturel, cette solution permet de converser directement avec les données (sans écrire de SQL ni de code), d’obtenir des insights chiffrés mais aussi visuels, de créer des tableaux de bord, de générer des visualisations ou encore de déclencher des analyses, simplement en écrivant ou en parlant comme on le ferait avec un assistant virtuel.
En preview depuis de nombreux mois, AI/BI Genie est en disponibilité générale depuis l’ouverture du Summit 2025. Genie s’intègre automatiquement aux tableaux de bord et à l’interface One.
À terme, Databricks va enrichir Genie d’une fonction Deep Research capable de gérer des questions de type « pourquoi » impliquant plusieurs étapes d’analyse : l’assistant pourra élaborer un plan de recherche multi-hypothèses et consulter diverses sources pour produire une explication approfondie, le tout avec des références/citations à l’appui.
Databricks Free Edition
Dernier volet, et non des moindres, dans cette volonté de rendre la data et la plateforme plus accessible : Databricks investit dans la formation et l’adoption large de sa technologie. L’éditeur a annoncé un plan de 100 M$ sur plusieurs années pour promouvoir les compétences data/IA dans le monde. Il a surtout lancé une nouvelle offre Databricks Free Edition (en preview publique) pour mettre la plateforme gratuitement à disposition des étudiants, enseignants, aspirants data scientists ou tout apprenant intéressé.
Contrairement à une simple version d’essai limitée, Free Edition donne accès aux capacités presque complètes de la plateforme Lakehouse (ingestion de données, notebooks, SQL, ML, dashboards…) sur un espace dédié cloud, sans frais. Seules certaines fonctions très avancées, comme l’exploitation des GPU, les Clean Rooms ou les configurations réseau sont exclues de l’offre.
L’accès est ouvert à tous, sans frais, via une simple inscription en ligne. Cependant, cette édition gratuite est bien évidemment strictement réservée à un usage personnel, éducatif et non commercial. Elle fonctionne sur des ressources de calcul serverless limitées, avec des quotas journaliers et mensuels pour garantir une utilisation équitable entre tous les utilisateurs. L’idée est vraiment de permettre à une nouvelle génération de se former sur des outils de niveau entreprise, en miroir de ce qu’ils utiliseront en conditions réelles. Databricks inclut d’ailleurs un accès à du contenu de formation gratuit via son Academy pour accélérer la prise en main. En comblant ainsi le fossé de compétences, l’éditeur espère créer un vivier de talents familiers de son écosystème, un pari stratégique pour accroître l’adoption de sa plateforme.
Avec ce cru 2025 du « Data + AI Summit », Databricks a dévoilé une vision où absolument tous les chemins de la donnée convergent vers sa plateforme unifiée. En intégrant une base de données transactionnelle, en ouvrant sa gouvernance à des formats externes, en simplifiant radicalement le déploiement d’IA générative et en rapprochant les utilisateurs métiers de la donnée, Databricks se pose en acteur total du « Data + AI ». Cette stratégie n’est pas sans rappeler celle de son grand rival Snowflake, qui, une semaine plus tôt, lors du Snowflake Summit 2025, a multiplié les annonces similaires : Snowflake Intelligence pour converser avec les données, fonctions SQL dopées à l’IA avec Cortex AISQL, Openflow pour l’ingestion des données, etc. Surtout, Snowflake a répondu à Databricks sur le terrain opérationnel en annonçant le rachat de Crunchy Data, prélude au lancement de Snowflake Postgres pour ajouter une brique transactionnelle à son Data Cloud. Les deux concurrents s’inscrivent sur cette tendance qui vise à faire disparaître la frontière entre données opérationnelles et analytiques qu’AWS a largement cherché à promotionner l’an dernier avec sa refonte de Sagemaker et que Microsoft concrétise également avec sa Fabric.
Au final, ce « Data + AI Summit 2025 » illustre parfaitement l’effervescence d’un marché où chaque acteur veut être LA plateforme incontournable du « data cloud intelligent ». Il y a probablement de la place pour tout le monde sur ce marché, mais cette guerre intense engendre une surenchère d’innovations qui fait évoluer l’univers du Data Cloud au même rythme frénétique que l’IA… Et les DSI doivent redoubler d’attention pour rester à la page, comprendre les impacts de ces innovations dans tous les sens et apprendre à les exploiter pour en tirer la valeur attendue. Tout en évitant le piège du lock-in forcément plus ou moins inhérent à l’adoption d’une plateforme unique pour toutes les données…
À LIRE AUSSI :